 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBertinho: Galician BERT Representations
Paper and Code

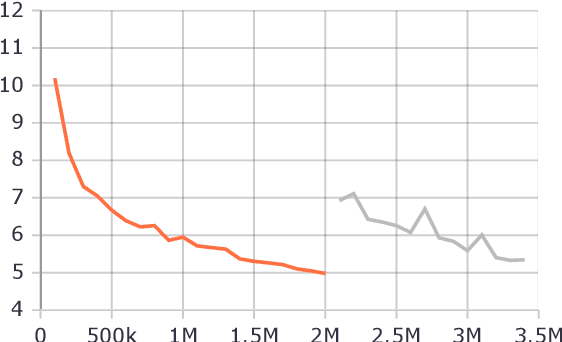
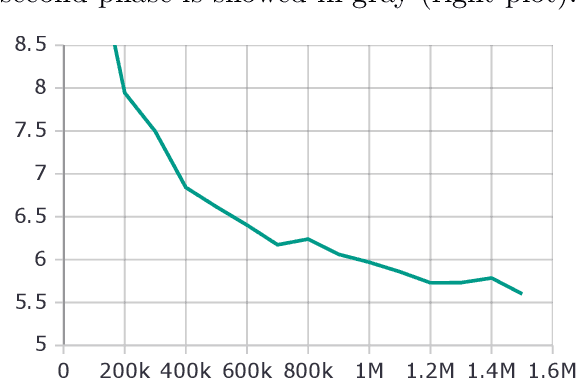
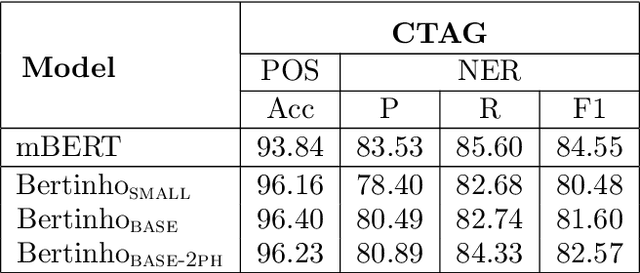
This paper presents a monolingual BERT model for Galician. We follow the recent trend that shows that it is feasible to build robust monolingual BERT models even for relatively low-resource languages, while performing better than the well-known official multilingual BERT (mBERT). More particularly, we release two monolingual Galician BERT models, built using 6 and 12 transformer layers, respectively; trained with limited resources (~45 million tokens on a single GPU of 24GB). We then provide an exhaustive evaluation on a number of tasks such as POS-tagging, dependency parsing and named entity recognition. For this purpose, all these tasks are cast in a pure sequence labeling setup in order to run BERT without the need to include any additional layers on top of it (we only use an output classification layer to map the contextualized representations into the predicted label). The experiments show that our models, especially the 12-layer one, outperform the results of mBERT in most tasks.