 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Syntactic Iberian Polarity Classification
Aug 17, 2017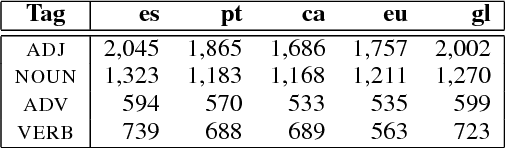
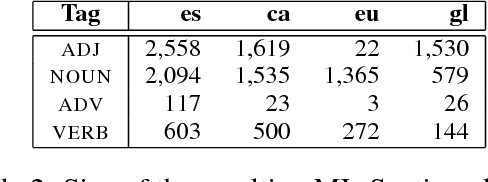
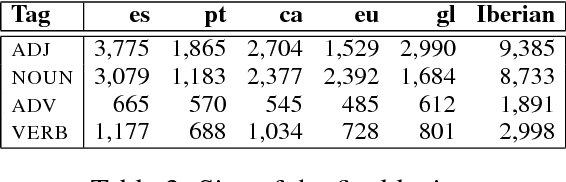
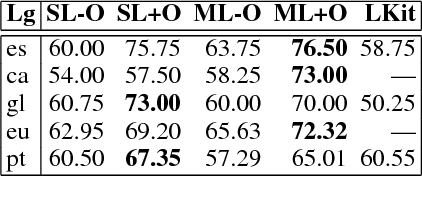
Lexicon-based methods using syntactic rules for polarity classification rely on parsers that are dependent on the language and on treebank guidelines. Thus, rules are also dependent and require adaptation, especially in multilingual scenarios. We tackle this challenge in the context of the Iberian Peninsula, releasing the first symbolic syntax-based Iberian system with rules shared across five official languages: Basque, Catalan, Galician, Portuguese and Spanish. The model is made available.
Universal, Unsupervised (Rule-Based), Uncovered Sentiment Analysis
Jan 05, 2017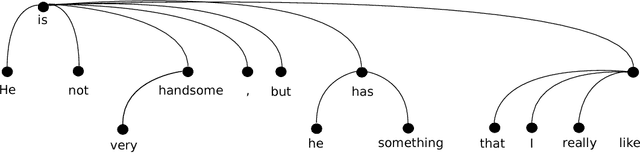

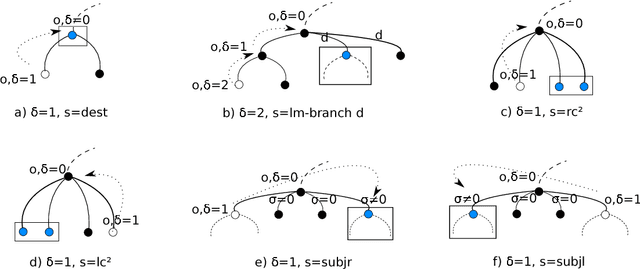
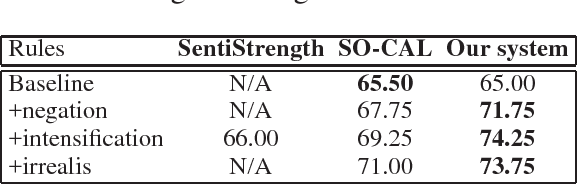
We present a novel unsupervised approach for multilingual sentiment analysis driven by compositional syntax-based rules. On the one hand, we exploit some of the main advantages of unsupervised algorithms: (1) the interpretability of their output, in contrast with most supervised models, which behave as a black box and (2) their robustness across different corpora and domains. On the other hand, by introducing the concept of compositional operations and exploiting syntactic information in the form of universal dependencies, we tackle one of their main drawbacks: their rigidity on data that are structured differently depending on the language concerned. Experiments show an improvement both over existing unsupervised methods, and over state-of-the-art supervised models when evaluating outside their corpus of origin. Experiments also show how the same compositional operations can be shared across languages. The system is available at http://www.grupolys.org/software/UUUSA/
* 19 pages, 5 Tables, 6 Figures. This is the authors version of a work that was accepted for publication in Knowledge-Based Systems
One model, two languages: training bilingual parsers with harmonized treebanks
May 19, 2016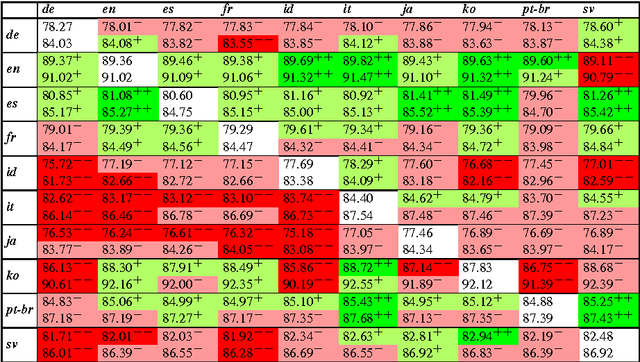

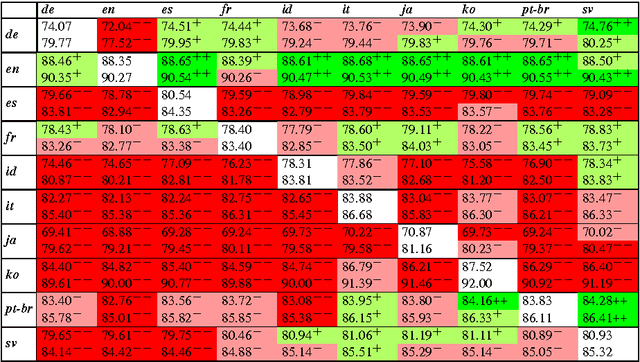

We introduce an approach to train lexicalized parsers using bilingual corpora obtained by merging harmonized treebanks of different languages, producing parsers that can analyze sentences in either of the learned languages, or even sentences that mix both. We test the approach on the Universal Dependency Treebanks, training with MaltParser and MaltOptimizer. The results show that these bilingual parsers are more than competitive, as most combinations not only preserve accuracy, but some even achieve significant improvements over the corresponding monolingual parsers. Preliminary experiments also show the approach to be promising on texts with code-switching and when more languages are added.