 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-quality generation of dynamic game content via small language models: A proof of concept
Jan 30, 2026Large language models (LLMs) offer promise for dynamic game content generation, but they face critical barriers, including narrative incoherence and high operational costs. Due to their large size, they are often accessed in the cloud, limiting their application in offline games. Many of these practical issues are solved by pivoting to small language models (SLMs), but existing studies using SLMs have resulted in poor output quality. We propose a strategy of achieving high-quality SLM generation through aggressive fine-tuning on deliberately scoped tasks with narrow context, constrained structure, or both. In short, more difficult tasks require narrower scope and higher specialization to the training corpus. Training data is synthetically generated via a DAG-based approach, grounding models in the specific game world. Such models can form the basis for agentic networks designed around the narratological framework at hand, representing a more practical and robust solution than cloud-dependent LLMs. To validate this approach, we present a proof-of-concept focusing on a single specialized SLM as the fundamental building block. We introduce a minimal RPG loop revolving around rhetorical battles of reputations, powered by this model. We demonstrate that a simple retry-until-success strategy reaches adequate quality (as defined by an LLM-as-a-judge scheme) with predictable latency suitable for real-time generation. While local quality assessment remains an open question, our results demonstrate feasibility for real-time generation under typical game engine constraints.
Evaluating Quality of Gaming Narratives Co-created with AI
Sep 04, 2025This paper proposes a structured methodology to evaluate AI-generated game narratives, leveraging the Delphi study structure with a panel of narrative design experts. Our approach synthesizes story quality dimensions from literature and expert insights, mapping them into the Kano model framework to understand their impact on player satisfaction. The results can inform game developers on prioritizing quality aspects when co-creating game narratives with generative AI.
AntiCheatPT: A Transformer-Based Approach to Cheat Detection in Competitive Computer Games
Aug 08, 2025Cheating in online video games compromises the integrity of gaming experiences. Anti-cheat systems, such as VAC (Valve Anti-Cheat), face significant challenges in keeping pace with evolving cheating methods without imposing invasive measures on users' systems. This paper presents AntiCheatPT\_256, a transformer-based machine learning model designed to detect cheating behaviour in Counter-Strike 2 using gameplay data. To support this, we introduce and publicly release CS2CD: A labelled dataset of 795 matches. Using this dataset, 90,707 context windows were created and subsequently augmented to address class imbalance. The transformer model, trained on these windows, achieved an accuracy of 89.17\% and an AUC of 93.36\% on an unaugmented test set. This approach emphasizes reproducibility and real-world applicability, offering a robust baseline for future research in data-driven cheat detection.
Exploring Deep Learning Models for EEG Neural Decoding
Mar 20, 2025Neural decoding is an important method in cognitive neuroscience that aims to decode brain representations from recorded neural activity using a multivariate machine learning model. The THINGS initiative provides a large EEG dataset of 46 subjects watching rapidly shown images. Here, we test the feasibility of using this method for decoding high-level object features using recent deep learning models. We create a derivative dataset from this of living vs non-living entities test 15 different deep learning models with 5 different architectures and compare to a SOTA linear model. We show that the linear model is not able to solve the decoding task, while almost all the deep learning models are successful, suggesting that in some cases non-linear models are needed to decode neural representations. We also run a comparative study of the models' performance on individual object categories, and suggest how artificial neural networks can be used to study brain activity.
Modelling Emotions in Face-to-Face Setting: The Interplay of Eye-Tracking, Personality, and Temporal Dynamics
Mar 18, 2025Accurate emotion recognition is pivotal for nuanced and engaging human-computer interactions, yet remains difficult to achieve, especially in dynamic, conversation-like settings. In this study, we showcase how integrating eye-tracking data, temporal dynamics, and personality traits can substantially enhance the detection of both perceived and felt emotions. Seventy-three participants viewed short, speech-containing videos from the CREMA-D dataset, while being recorded for eye-tracking signals (pupil size, fixation patterns), Big Five personality assessments, and self-reported emotional states. Our neural network models combined these diverse inputs including stimulus emotion labels for contextual cues and yielded marked performance gains compared to the state-of-the-art. Specifically, perceived valence predictions reached a macro F1-score of 0.76, and models incorporating personality traits and stimulus information demonstrated significant improvements in felt emotion accuracy. These results highlight the benefit of unifying physiological, individual and contextual factors to address the subjectivity and complexity of emotional expression. Beyond validating the role of user-specific data in capturing subtle internal states, our findings inform the design of future affective computing and human-agent systems, paving the way for more adaptive and cross-individual emotional intelligence in real-world interactions.
Don't Get Too Excited -- Eliciting Emotions in LLMs
Mar 04, 2025This paper investigates the challenges of affect control in large language models (LLMs), focusing on their ability to express appropriate emotional states during extended dialogues. We evaluated state-of-the-art open-weight LLMs to assess their affective expressive range in terms of arousal and valence. Our study employs a novel methodology combining LLM-based sentiment analysis with multiturn dialogue simulations between LLMs. We quantify the models' capacity to express a wide spectrum of emotions and how they fluctuate during interactions. Our findings reveal significant variations among LLMs in their ability to maintain consistent affect, with some models demonstrating more stable emotional trajectories than others. Furthermore, we identify key challenges in affect control, including difficulties in producing and maintaining extreme emotional states and limitations in adapting affect to changing conversational contexts. These findings have important implications for the development of more emotionally intelligent AI systems and highlight the need for improved affect modelling in LLMs.
Difficulty Modelling in Mobile Puzzle Games: An Empirical Study on Different Methods to Combine Player Analytics and Simulated Data
Jan 30, 2024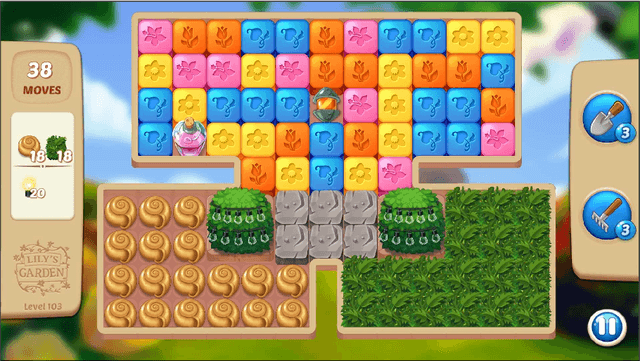


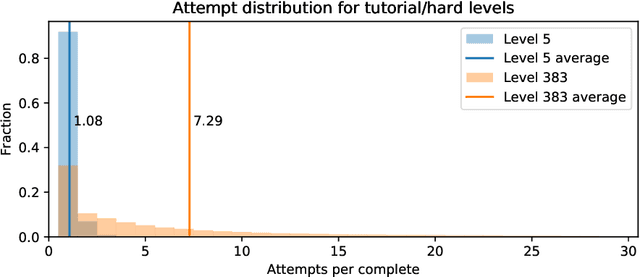
Difficulty is one of the key drivers of player engagement and it is often one of the aspects that designers tweak most to optimise the player experience; operationalising it is, therefore, a crucial task for game development studios. A common practice consists of creating metrics out of data collected by player interactions with the content; however, this allows for estimation only after the content is released and does not consider the characteristics of potential future players. In this article, we present a number of potential solutions for the estimation of difficulty under such conditions, and we showcase the results of a comparative study intended to understand which method and which types of data perform better in different scenarios. The results reveal that models trained on a combination of cohort statistics and simulated data produce the most accurate estimations of difficulty in all scenarios. Furthermore, among these models, artificial neural networks show the most consistent results.
Procedurally generating rules to adapt difficulty for narrative puzzle games
Jul 07, 2023This paper focuses on procedurally generating rules and communicating them to players to adjust the difficulty. This is part of a larger project to collect and adapt games in educational games for young children using a digital puzzle game designed for kindergarten. A genetic algorithm is used together with a difficulty measure to find a target number of solution sets and a large language model is used to communicate the rules in a narrative context. During testing the approach was able to find rules that approximate any given target difficulty within two dozen generations on average. The approach was combined with a large language model to create a narrative puzzle game where players have to host a dinner for animals that can't get along. Future experiments will try to improve evaluation, specialize the language model on children's literature, and collect multi-modal data from players to guide adaptation.
Creating user stereotypes for persona development from qualitative data through semi-automatic subspace clustering
Jun 26, 2023Personas are models of users that incorporate motivations, wishes, and objectives; These models are employed in user-centred design to help design better user experiences and have recently been employed in adaptive systems to help tailor the personalized user experience. Designing with personas involves the production of descriptions of fictitious users, which are often based on data from real users. The majority of data-driven persona development performed today is based on qualitative data from a limited set of interviewees and transformed into personas using labour-intensive manual techniques. In this study, we propose a method that employs the modelling of user stereotypes to automate part of the persona creation process and addresses the drawbacks of the existing semi-automated methods for persona development. The description of the method is accompanied by an empirical comparison with a manual technique and a semi-automated alternative (multiple correspondence analysis). The results of the comparison show that manual techniques differ between human persona designers leading to different results. The proposed algorithm provides similar results based on parameter input, but was more rigorous and will find optimal clusters, while lowering the labour associated with finding the clusters in the dataset. The output of the method also represents the largest variances in the dataset identified by the multiple correspondence analysis.
Procedural content generation of puzzle games using conditional generative adversarial networks
Jun 26, 2023



In this article, we present an experimental approach to using parameterized Generative Adversarial Networks (GANs) to produce levels for the puzzle game Lily's Garden. We extract two condition vectors from the real levels in an effort to control the details of the GAN's outputs. While the GANs perform well in approximating the first condition (map shape), they struggle to approximate the second condition (piece distribution). We hypothesize that this might be improved by trying out alternative architectures for both the Generator and Discriminator of the GANs.