 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifficulty Modelling in Mobile Puzzle Games: An Empirical Study on Different Methods to Combine Player Analytics and Simulated Data
Jan 30, 2024


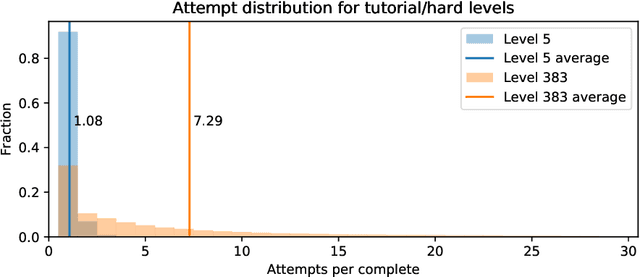
Difficulty is one of the key drivers of player engagement and it is often one of the aspects that designers tweak most to optimise the player experience; operationalising it is, therefore, a crucial task for game development studios. A common practice consists of creating metrics out of data collected by player interactions with the content; however, this allows for estimation only after the content is released and does not consider the characteristics of potential future players. In this article, we present a number of potential solutions for the estimation of difficulty under such conditions, and we showcase the results of a comparative study intended to understand which method and which types of data perform better in different scenarios. The results reveal that models trained on a combination of cohort statistics and simulated data produce the most accurate estimations of difficulty in all scenarios. Furthermore, among these models, artificial neural networks show the most consistent results.
Estimating player completion rate in mobile puzzle games using reinforcement learning
Jun 26, 2023



In this work we investigate whether it is plausible to use the performance of a reinforcement learning (RL) agent to estimate the difficulty measured as the player completion rate of different levels in the mobile puzzle game Lily's Garden.For this purpose we train an RL agent and measure the number of moves required to complete a level. This is then compared to the level completion rate of a large sample of real players.We find that the strongest predictor of player completion rate for a level is the number of moves taken to complete a level of the ~5% best runs of the agent on a given level. A very interesting observation is that, while in absolute terms, the agent is unable to reach human-level performance across all levels, the differences in terms of behaviour between levels are highly correlated to the differences in human behaviour. Thus, despite performing sub-par, it is still possible to use the performance of the agent to estimate, and perhaps further model, player metrics.
Combining Sequential and Aggregated Data for Churn Prediction in Casual Freemium Games
Sep 06, 2022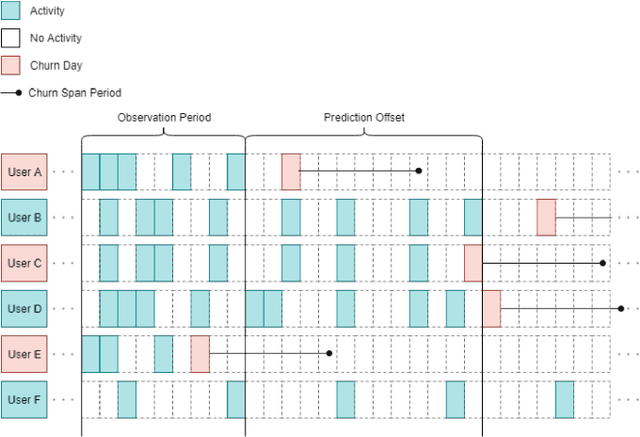
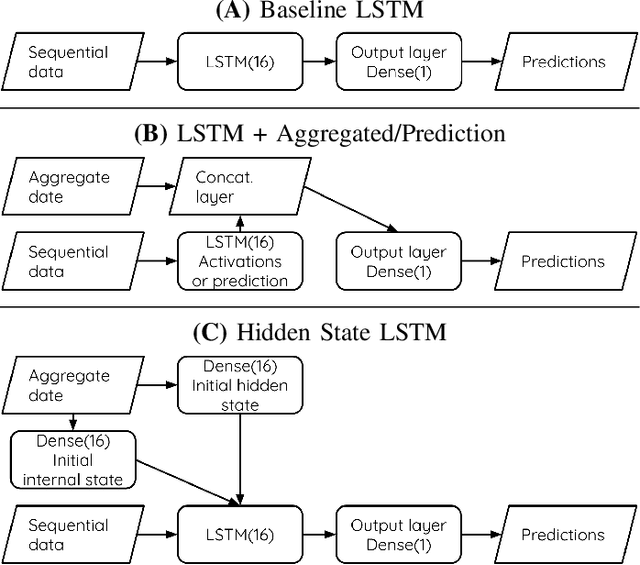

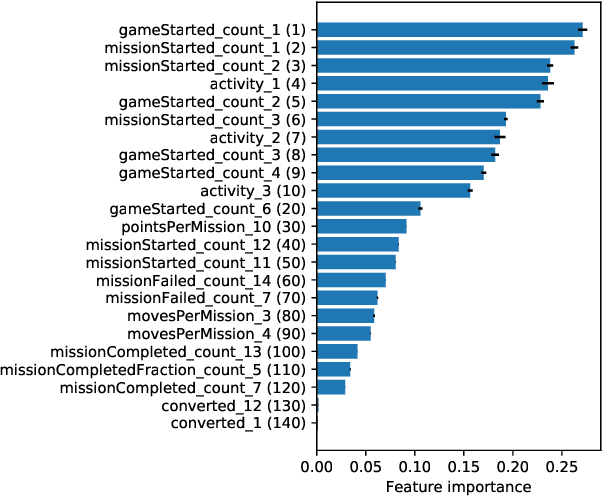
In freemium games, the revenue from a player comes from the in-app purchases made and the advertisement to which that player is exposed. The longer a player is playing the game, the higher will be the chances that he or she will generate a revenue within the game. Within this scenario, it is extremely important to be able to detect promptly when a player is about to quit playing (churn) in order to react and attempt to retain the player within the game, thus prolonging his or her game lifetime. In this article we investigate how to improve the current state-of-the-art in churn prediction by combining sequential and aggregate data using different neural network architectures. The results of the comparative analysis show that the combination of the two data types grants an improvement in the prediction accuracy over predictors based on either purely sequential or purely aggregated data.
Statistical Modelling of Level Difficulty in Puzzle Games
Jul 08, 2021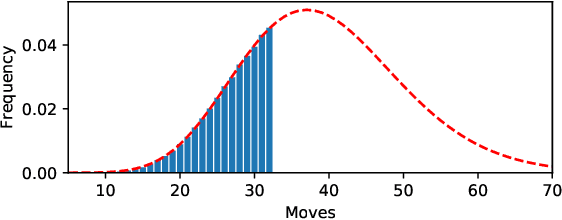

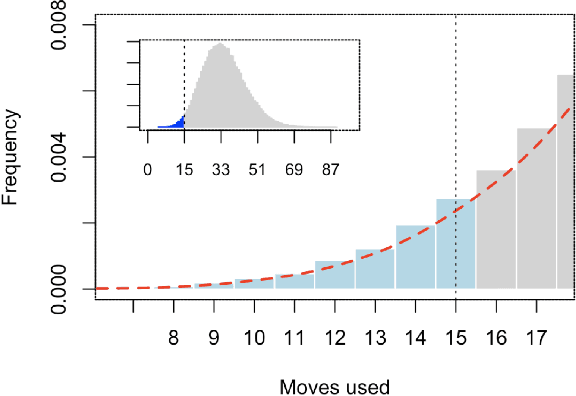
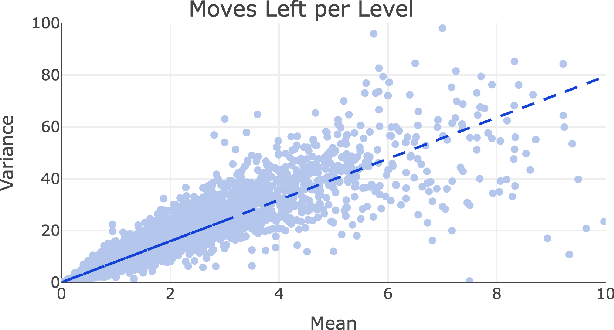
Successful and accurate modelling of level difficulty is a fundamental component of the operationalisation of player experience as difficulty is one of the most important and commonly used signals for content design and adaptation. In games that feature intermediate milestones, such as completable areas or levels, difficulty is often defined by the probability of completion or completion rate; however, this operationalisation is limited in that it does not describe the behaviour of the player within the area. In this research work, we formalise a model of level difficulty for puzzle games that goes beyond the classical probability of success. We accomplish this by describing the distribution of actions performed within a game level using a parametric statistical model thus creating a richer descriptor of difficulty. The model is fitted and evaluated on a dataset collected from the game Lily's Garden by Tactile Games, and the results of the evaluation show that the it is able to describe and explain difficulty in a vast majority of the levels.
Strategies for Using Proximal Policy Optimization in Mobile Puzzle Games
Jul 03, 2020



While traditionally a labour intensive task, the testing of game content is progressively becoming more automated. Among the many directions in which this automation is taking shape, automatic play-testing is one of the most promising thanks also to advancements of many supervised and reinforcement learning (RL) algorithms. However these type of algorithms, while extremely powerful, often suffer in production environments due to issues with reliability and transparency in their training and usage. In this research work we are investigating and evaluating strategies to apply the popular RL method Proximal Policy Optimization (PPO) in a casual mobile puzzle game with a specific focus on improving its reliability in training and generalization during game playing. We have implemented and tested a number of different strategies against a real-world mobile puzzle game (Lily's Garden from Tactile Games). We isolated the conditions that lead to a failure in either training or generalization during testing and we identified a few strategies to ensure a more stable behaviour of the algorithm in this game genre.