 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocal and Global Decoding in Text Generation
Oct 14, 2024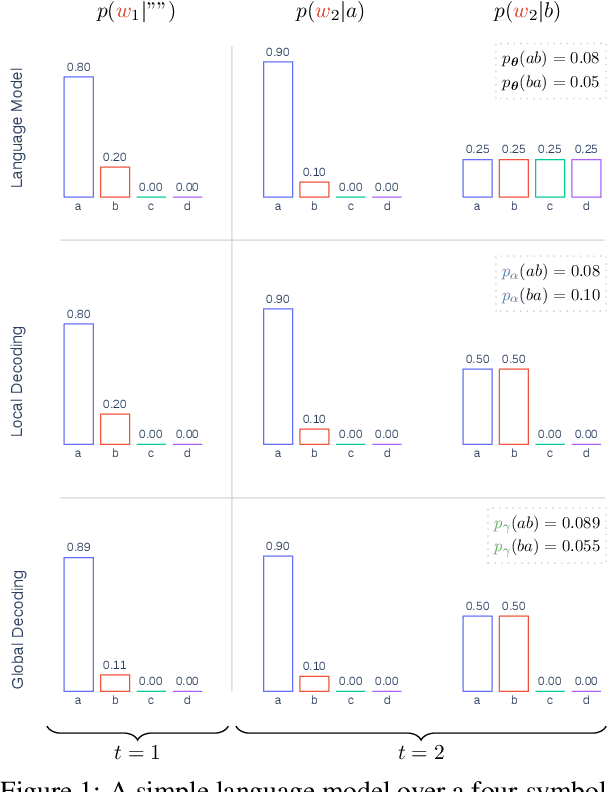
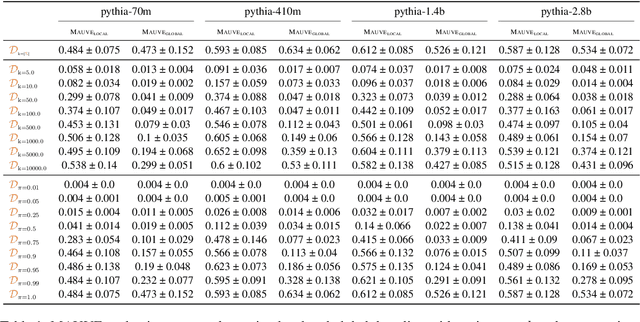

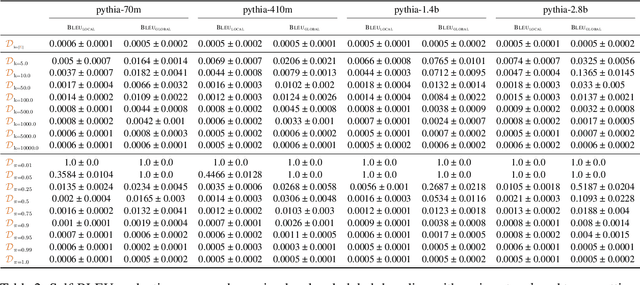
Text generation, a key component in applications such as dialogue systems, relies on decoding algorithms that sample strings from a language model distribution. Traditional methods, such as top-$k$ and top-$\pi$, apply local normalisation to the model's output distribution, which can distort it. In this paper, we investigate the effect of this distortion by introducing globally-normalised versions of these decoding methods. Additionally, we propose an independent Metropolis-Hastings algorithm to approximate sampling from globally-normalised distributions without explicitly computing them. Our empirical analysis compares the performance of local and global normalisation across two decoding algorithms (top-$k$ and top-$\pi$) with various hyperparameters, using Pythia language models. Results show that, in most configurations, global decoding performs worse than the local decoding version of the same algorithms -- despite preserving the distribution's integrity. Our results suggest that distortion is an important feature of local decoding algorithms.