 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCost-Sensitive Multi-Fidelity Bayesian Optimization with Transfer of Learning Curve Extrapolation
May 28, 2024In this paper, we address the problem of cost-sensitive multi-fidelity Bayesian Optimization (BO) for efficient hyperparameter optimization (HPO). Specifically, we assume a scenario where users want to early-stop the BO when the performance improvement is not satisfactory with respect to the required computational cost. Motivated by this scenario, we introduce utility, which is a function predefined by each user and describes the trade-off between cost and performance of BO. This utility function, combined with our novel acquisition function and stopping criterion, allows us to dynamically choose for each BO step the best configuration that we expect to maximally improve the utility in future, and also automatically stop the BO around the maximum utility. Further, we improve the sample efficiency of existing learning curve (LC) extrapolation methods with transfer learning, while successfully capturing the correlations between different configurations to develop a sensible surrogate function for multi-fidelity BO. We validate our algorithm on various LC datasets and found it outperform all the previous multi-fidelity BO and transfer-BO baselines we consider, achieving significantly better trade-off between cost and performance of BO.
Cost-effective Interactive Attention Learning with Neural Attention Processes
Jun 09, 2020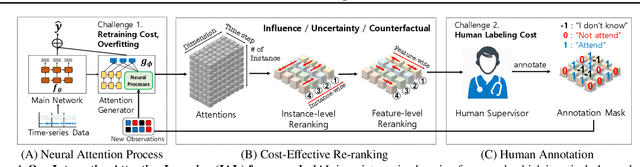
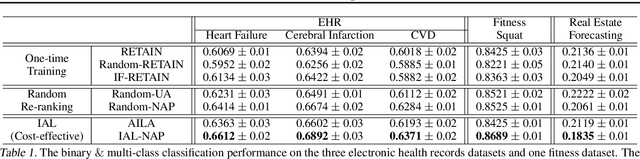
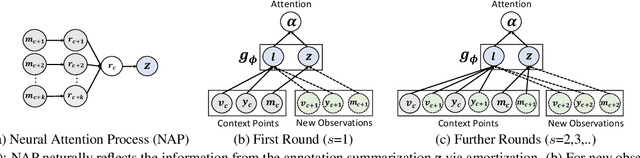

We propose a novel interactive learning framework which we refer to as Interactive Attention Learning (IAL), in which the human supervisors interactively manipulate the allocated attentions, to correct the model's behavior by updating the attention-generating network. However, such a model is prone to overfitting due to scarcity of human annotations, and requires costly retraining. Moreover, it is almost infeasible for the human annotators to examine attentions on tons of instances and features. We tackle these challenges by proposing a sample-efficient attention mechanism and a cost-effective reranking algorithm for instances and features. First, we propose Neural Attention Process (NAP), which is an attention generator that can update its behavior by incorporating new attention-level supervisions without any retraining. Secondly, we propose an algorithm which prioritizes the instances and the features by their negative impacts, such that the model can yield large improvements with minimal human feedback. We validate IAL on various time-series datasets from multiple domains (healthcare, real-estate, and computer vision) on which it significantly outperforms baselines with conventional attention mechanisms, or without cost-effective reranking, with substantially less retraining and human-model interaction cost.