 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMacroLens: A Multi-Task Benchmark for Contextual Financial Reasoning under Macroeconomic Scenarios
Jun 23, 2026Financial decision-making is contextual: forecasting prices, valuing companies, and assessing event exposure weigh price history, accounting fundamentals, macroeconomic regime, and contemporaneous text. A benchmark over these four signals is hard to build because finance violates four assumptions of time-series evaluation: text must be gated by its publication date to prevent look-ahead, quarterly fundamentals are reported with a one- to ninety-day lag, filing text is partly redundant with the numerical statement fields it accompanies, and macroeconomic regimes leak across calendar splits. No public benchmark addresses all four signals jointly. MacroLens covers 4,416 U.S. small- and micro-cap equities over 2021-2026. Seven tasks share one point-in-time panel of prices, 46.8M XBRL accounting facts, 53 macroeconomic series, 295,860 SEC filings, and 215,882 news articles, plus a scenario layer of 1,130 macroeconomic events across 49 types automatically detected and rendered as natural language. Tasks span contextual forecasting, public and private valuation, statement generation from fundamentals and descriptions, scenario-conditioned returns, and real-estate valuation. We evaluate 19 methods across six families spanning naive heuristics through time-series foundation models, fine-tuned LLM-based time-series models, and zero-shot large language models (LLMs), plus a five-step feature-context ablation on two frontier LLMs and a gradient-boosted baseline. MacroLens is released at https://huggingface.co/datasets/DeepAuto-AI/MacroLens.
TS-Debate: Multimodal Collaborative Debate for Zero-Shot Time Series Reasoning
Jan 27, 2026Recent progress at the intersection of large language models (LLMs) and time series (TS) analysis has revealed both promise and fragility. While LLMs can reason over temporal structure given carefully engineered context, they often struggle with numeric fidelity, modality interference, and principled cross-modal integration. We present TS-Debate, a modality-specialized, collaborative multi-agent debate framework for zero-shot time series reasoning. TS-Debate assigns dedicated expert agents to textual context, visual patterns, and numerical signals, preceded by explicit domain knowledge elicitation, and coordinates their interaction via a structured debate protocol. Reviewer agents evaluate agent claims using a verification-conflict-calibration mechanism, supported by lightweight code execution and numerical lookup for programmatic verification. This architecture preserves modality fidelity, exposes conflicting evidence, and mitigates numeric hallucinations without task-specific fine-tuning. Across 20 tasks spanning three public benchmarks, TS-Debate achieves consistent and significant performance improvements over strong baselines, including standard multimodal debate in which all agents observe all inputs.
Cost-effective Interactive Attention Learning with Neural Attention Processes
Jun 09, 2020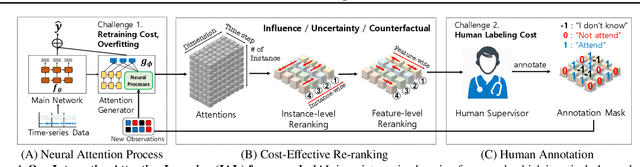
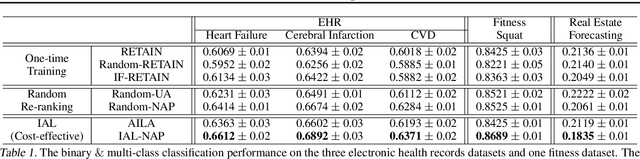
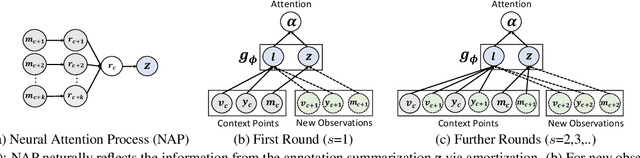

We propose a novel interactive learning framework which we refer to as Interactive Attention Learning (IAL), in which the human supervisors interactively manipulate the allocated attentions, to correct the model's behavior by updating the attention-generating network. However, such a model is prone to overfitting due to scarcity of human annotations, and requires costly retraining. Moreover, it is almost infeasible for the human annotators to examine attentions on tons of instances and features. We tackle these challenges by proposing a sample-efficient attention mechanism and a cost-effective reranking algorithm for instances and features. First, we propose Neural Attention Process (NAP), which is an attention generator that can update its behavior by incorporating new attention-level supervisions without any retraining. Secondly, we propose an algorithm which prioritizes the instances and the features by their negative impacts, such that the model can yield large improvements with minimal human feedback. We validate IAL on various time-series datasets from multiple domains (healthcare, real-estate, and computer vision) on which it significantly outperforms baselines with conventional attention mechanisms, or without cost-effective reranking, with substantially less retraining and human-model interaction cost.
Uncertainty-Aware Attention for Reliable Interpretation and Prediction
May 24, 2018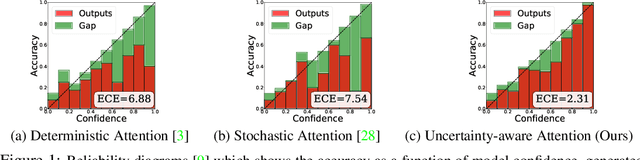
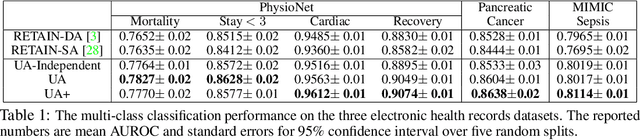
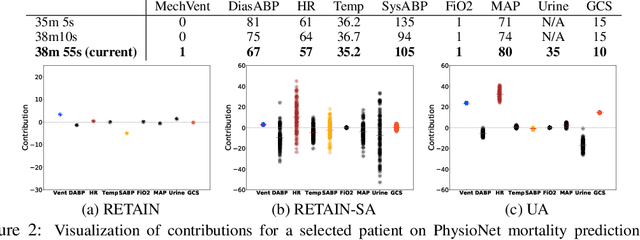
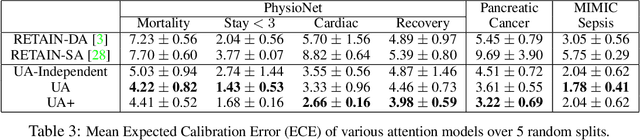
Attention mechanism is effective in both focusing the deep learning models on relevant features and interpreting them. However, attentions may be unreliable since the networks that generate them are often trained in a weakly-supervised manner. To overcome this limitation, we introduce the notion of input-dependent uncertainty to the attention mechanism, such that it generates attention for each feature with varying degrees of noise based on the given input, to learn larger variance on instances it is uncertain about. We learn this Uncertainty-aware Attention (UA) mechanism using variational inference, and validate it on various risk prediction tasks from electronic health records on which our model significantly outperforms existing attention models. The analysis of the learned attentions shows that our model generates attentions that comply with clinicians' interpretation, and provide richer interpretation via learned variance. Further evaluation of both the accuracy of the uncertainty calibration and the prediction performance with "I don't know" decision show that UA yields networks with high reliability as well.