 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning with Noisy Labels by Efficient Transition Matrix Estimation to Combat Label Miscorrection
Nov 29, 2021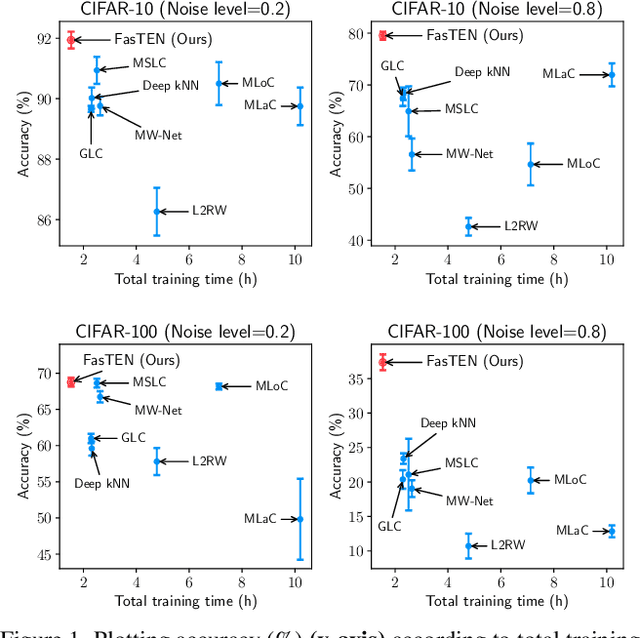
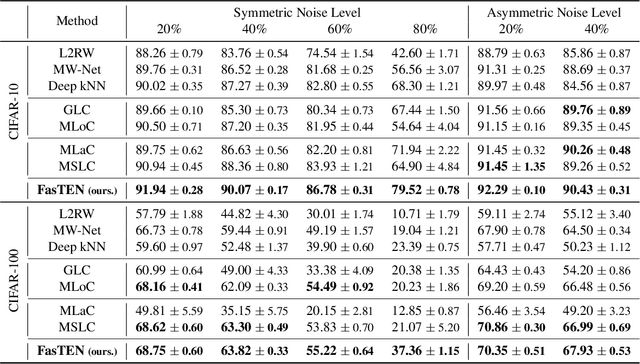
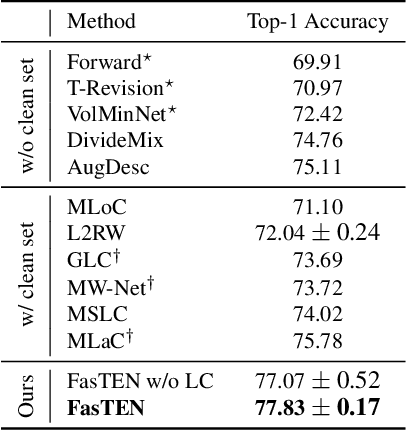
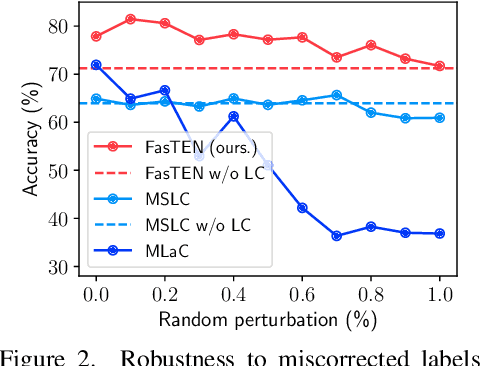
Recent studies on learning with noisy labels have shown remarkable performance by exploiting a small clean dataset. In particular, model agnostic meta-learning-based label correction methods further improve performance by correcting noisy labels on the fly. However, there is no safeguard on the label miscorrection, resulting in unavoidable performance degradation. Moreover, every training step requires at least three back-propagations, significantly slowing down the training speed. To mitigate these issues, we propose a robust and efficient method that learns a label transition matrix on the fly. Employing the transition matrix makes the classifier skeptical about all the corrected samples, which alleviates the miscorrection issue. We also introduce a two-head architecture to efficiently estimate the label transition matrix every iteration within a single back-propagation, so that the estimated matrix closely follows the shifting noise distribution induced by label correction. Extensive experiments demonstrate that our approach shows the best performance in training efficiency while having comparable or better accuracy than existing methods.
Efficient Click-Through Rate Prediction for Developing Countries via Tabular Learning
Apr 15, 2021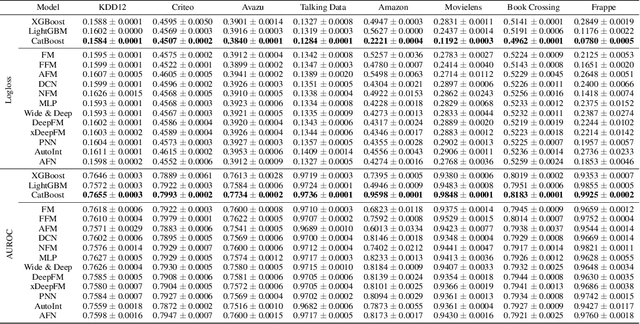
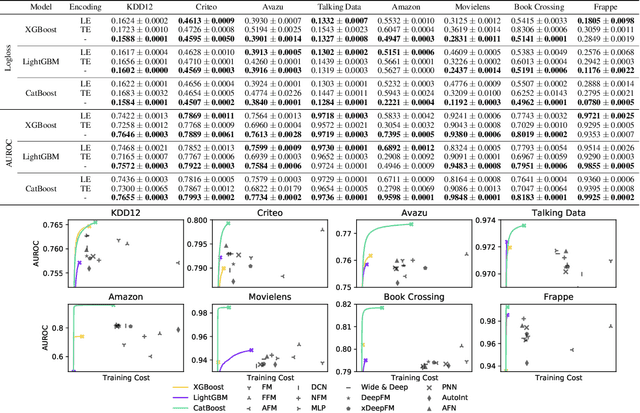

Despite the rapid growth of online advertisement in developing countries, existing highly over-parameterized Click-Through Rate (CTR) prediction models are difficult to be deployed due to the limited computing resources. In this paper, by bridging the relationship between CTR prediction task and tabular learning, we present that tabular learning models are more efficient and effective in CTR prediction than over-parameterized CTR prediction models. Extensive experiments on eight public CTR prediction datasets show that tabular learning models outperform twelve state-of-the-art CTR prediction models. Furthermore, compared to over-parameterized CTR prediction models, tabular learning models can be fast trained without expensive computing resources including high-performance GPUs. Finally, through an A/B test on an actual online application, we show that tabular learning models improve not only offline performance but also the CTR of real users.
Sparsity Normalization: Stabilizing the Expected Outputs of Deep Networks
Jun 01, 2019

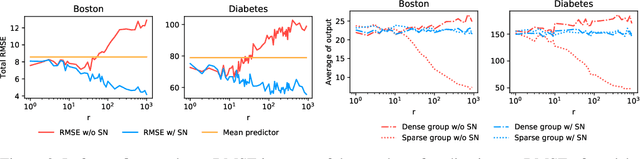
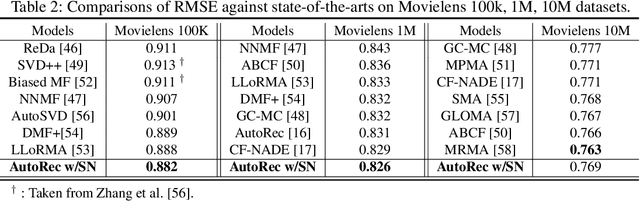
The learning of deep models, in which a numerous of parameters are superimposed, is known to be a fairly sensitive process and should be carefully done through a combination of several techniques that can help to stabilize it. We introduce an additional challenge that has never been explicitly studied: the heterogeneity of sparsity at the instance level due to missing values or the innate nature of the input distribution. We confirm experimentally on the widely used benchmark datasets that this variable sparsity problem makes the output statistics of neurons unstable and makes the learning process more difficult by saturating non-linearities. We also provide the analysis of this phenomenon, and based on our analysis, we present a simple technique to prevent this issue, referred to as Sparsity Normalization (SN). Finally, we show that the performance can be significantly improved with SN on certain popular benchmark datasets, or that similar performance can be achieved with lower capacity. Especially focusing on the collaborative filtering problem where the variable sparsity issue has been completely ignored, we achieve new state-of-the-art results on Movielens 100k and 1M datasets, by simply applying Sparsity Normalization (SN).