 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparsity Normalization: Stabilizing the Expected Outputs of Deep Networks
Paper and Code


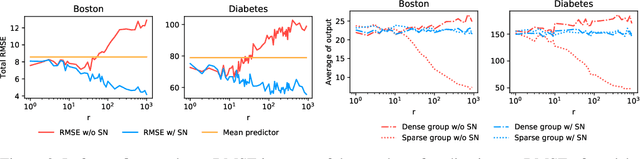
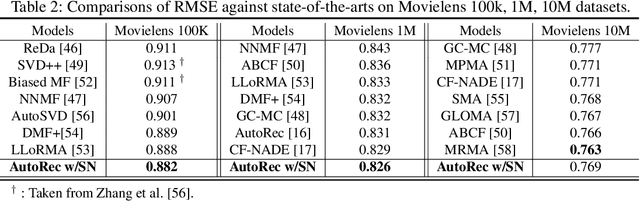
The learning of deep models, in which a numerous of parameters are superimposed, is known to be a fairly sensitive process and should be carefully done through a combination of several techniques that can help to stabilize it. We introduce an additional challenge that has never been explicitly studied: the heterogeneity of sparsity at the instance level due to missing values or the innate nature of the input distribution. We confirm experimentally on the widely used benchmark datasets that this variable sparsity problem makes the output statistics of neurons unstable and makes the learning process more difficult by saturating non-linearities. We also provide the analysis of this phenomenon, and based on our analysis, we present a simple technique to prevent this issue, referred to as Sparsity Normalization (SN). Finally, we show that the performance can be significantly improved with SN on certain popular benchmark datasets, or that similar performance can be achieved with lower capacity. Especially focusing on the collaborative filtering problem where the variable sparsity issue has been completely ignored, we achieve new state-of-the-art results on Movielens 100k and 1M datasets, by simply applying Sparsity Normalization (SN).