 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelational Proxy Loss for Audio-Text based Keyword Spotting
Paper and Code
Jun 08, 2024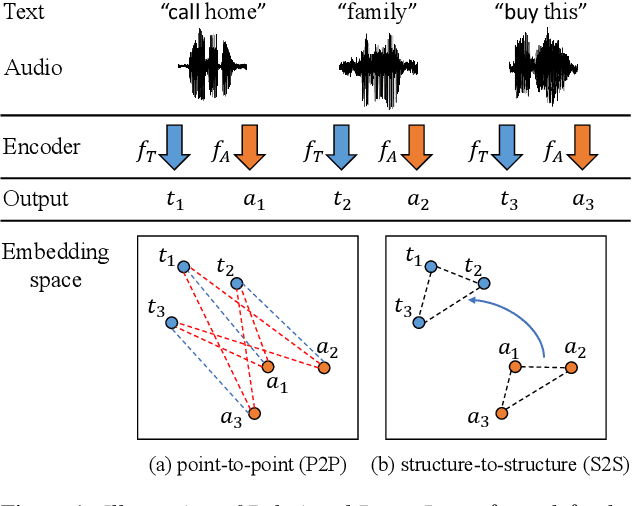
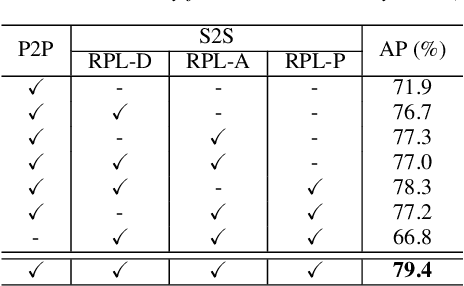
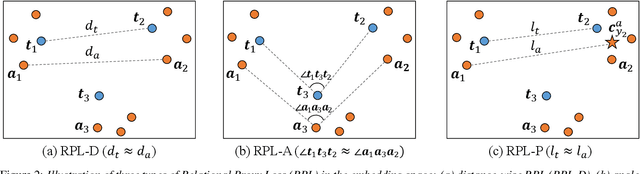

In recent years, there has been an increasing focus on user convenience, leading to increased interest in text-based keyword enrollment systems for keyword spotting (KWS). Since the system utilizes text input during the enrollment phase and audio input during actual usage, we call this task audio-text based KWS. To enable this task, both acoustic and text encoders are typically trained using deep metric learning loss functions, such as triplet- and proxy-based losses. This study aims to improve existing methods by leveraging the structural relations within acoustic embeddings and within text embeddings. Unlike previous studies that only compare acoustic and text embeddings on a point-to-point basis, our approach focuses on the relational structures within the embedding space by introducing the concept of Relational Proxy Loss (RPL). By incorporating RPL, we demonstrated improved performance on the Wall Street Journal (WSJ) corpus.