 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Clinically Ready Foundation Models in Medical Image Analysis: Adaptation Mechanisms and Deployment Trade-offs
Mar 15, 2026Foundation models (FMs) have demonstrated strong transferability across medical imaging tasks, yet their clinical utility depends critically on how pretrained representations are adapted to domain-specific data, supervision regimes, and deployment constraints. Prior surveys primarily emphasize architectural advances and application coverage, while the mechanisms of adaptation and their implications for robustness, calibration, and regulatory feasibility remain insufficiently structured. This review introduces a strategy-centric framework for FM adaptation in medical image analysis (MIA). We conceptualize adaptation as a post-pretraining intervention and organize existing approaches into five mechanisms: parameter-, representation-, objective-, data-centric, and architectural/sequence-level adaptation. For each mechanism, we analyze trade-offs in adaptation depth, label efficiency, domain robustness, computational cost, auditability, and regulatory burden. We synthesize evidence across classification, segmentation, and detection tasks, highlighting how adaptation strategies influence clinically relevant failure modes rather than only aggregate benchmark performance. Finally, we examine how adaptation choices interact with validation protocols, calibration stability, multi-institutional deployment, and regulatory oversight. By reframing adaptation as a process of controlled representational change under clinical constraints, this review provides practical guidance for designing FM-based systems that are robust, auditable, and compatible with clinical deployment.
Computationally Efficient Diffusion Models in Medical Imaging: A Comprehensive Review
May 09, 2025The diffusion model has recently emerged as a potent approach in computer vision, demonstrating remarkable performances in the field of generative artificial intelligence. Capable of producing high-quality synthetic images, diffusion models have been successfully applied across a range of applications. However, a significant challenge remains with the high computational cost associated with training and generating these models. This study focuses on the efficiency and inference time of diffusion-based generative models, highlighting their applications in both natural and medical imaging. We present the most recent advances in diffusion models by categorizing them into three key models: the Denoising Diffusion Probabilistic Model (DDPM), the Latent Diffusion Model (LDM), and the Wavelet Diffusion Model (WDM). These models play a crucial role in medical imaging, where producing fast, reliable, and high-quality medical images is essential for accurate analysis of abnormalities and disease diagnosis. We first investigate the general framework of DDPM, LDM, and WDM and discuss the computational complexity gap filled by these models in natural and medical imaging. We then discuss the current limitations of these models as well as the opportunities and future research directions in medical imaging.
Resource-Efficient Medical Report Generation using Large Language Models
Oct 21, 2024



Medical report generation is the task of automatically writing radiology reports for chest X-ray images. Manually composing these reports is a time-consuming process that is also prone to human errors. Generating medical reports can therefore help reduce the burden on radiologists. In other words, we can promote greater clinical automation in the medical domain. In this work, we propose a new framework leveraging vision-enabled Large Language Models (LLM) for the task of medical report generation. We introduce a lightweight solution that achieves better or comparative performance as compared to previous solutions on the task of medical report generation. We conduct extensive experiments exploring different model sizes and enhancement approaches, such as prefix tuning to improve the text generation abilities of the LLMs. We evaluate our approach on a prominent large-scale radiology report dataset - MIMIC-CXR. Our results demonstrate the capability of our resource-efficient framework to generate patient-specific reports with strong medical contextual understanding and high precision.
LLaVA Needs More Knowledge: Retrieval Augmented Natural Language Generation with Knowledge Graph for Explaining Thoracic Pathologies
Oct 07, 2024



Generating Natural Language Explanations (NLEs) for model predictions on medical images, particularly those depicting thoracic pathologies, remains a critical and challenging task. Existing methodologies often struggle due to general models' insufficient domain-specific medical knowledge and privacy concerns associated with retrieval-based augmentation techniques. To address these issues, we propose a novel Vision-Language framework augmented with a Knowledge Graph (KG)-based datastore, which enhances the model's understanding by incorporating additional domain-specific medical knowledge essential for generating accurate and informative NLEs. Our framework employs a KG-based retrieval mechanism that not only improves the precision of the generated explanations but also preserves data privacy by avoiding direct data retrieval. The KG datastore is designed as a plug-and-play module, allowing for seamless integration with various model architectures. We introduce and evaluate three distinct frameworks within this paradigm: KG-LLaVA, which integrates the pre-trained LLaVA model with KG-RAG; Med-XPT, a custom framework combining MedCLIP, a transformer-based projector, and GPT-2; and Bio-LLaVA, which adapts LLaVA by incorporating the Bio-ViT-L vision model. These frameworks are validated on the MIMIC-NLE dataset, where they achieve state-of-the-art results, underscoring the effectiveness of KG augmentation in generating high-quality NLEs for thoracic pathologies.
Nonlinear motion separation via untrained generator networks with disentangled latent space variables and applications to cardiac MRI
May 20, 2022

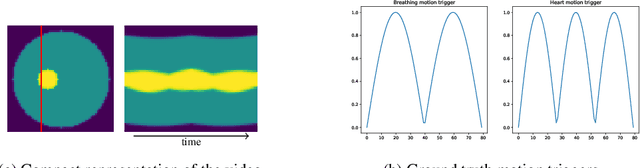
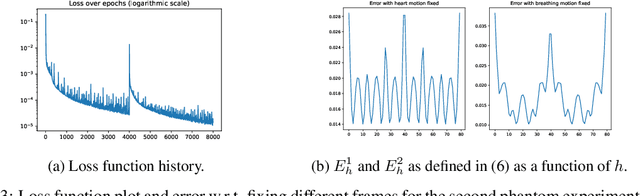
In this paper, a nonlinear approach to separate different motion types in video data is proposed. This is particularly relevant in dynamic medical imaging (e.g. PET, MRI), where patient motion poses a significant challenge due to its effects on the image reconstruction as well as for its subsequent interpretation. Here, a new method is proposed where dynamic images are represented as the forward mapping of a sequence of latent variables via a generator neural network. The latent variables are structured so that temporal variations in the data are represented via dynamic latent variables, which are independent of static latent variables characterizing the general structure of the frames. In particular, different kinds of motion are also characterized independently of each other via latent space disentanglement using one-dimensional prior information on all but one of the motion types. This representation allows to freeze any selection of motion types, and to obtain accurate independent representations of other dynamics of interest. Moreover, the proposed algorithm is training-free, i.e., all the network parameters are learned directly from a single video. We illustrate the performance of this method on phantom and real-data MRI examples, where we successfully separate respiratory and cardiac motion.