 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Simple Class Decision Balancing for Incremental Learning
Paper and Code
Mar 31, 2020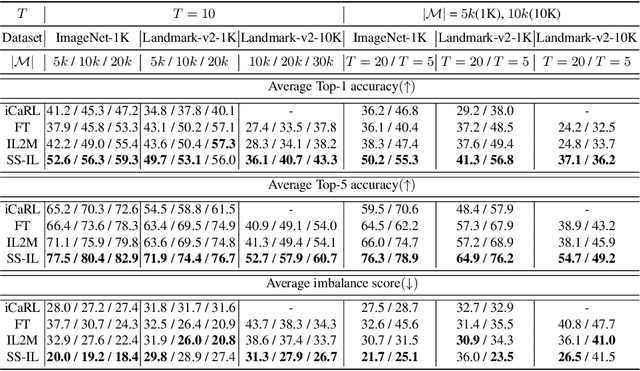
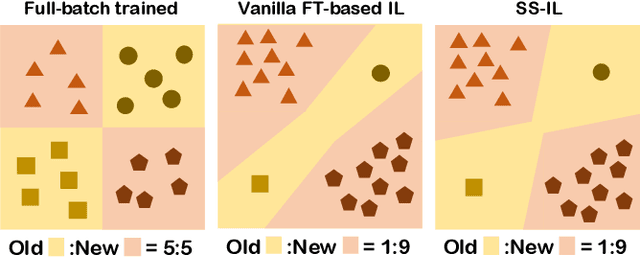
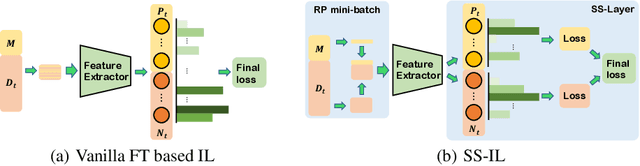
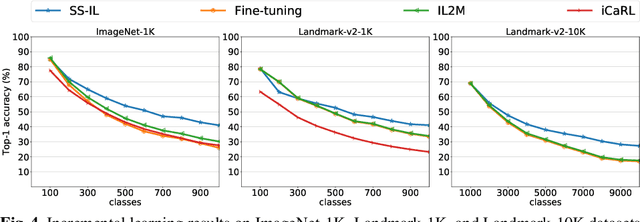
Class incremental learning (CIL) problem, in which a learning agent continuously learns new classes from incrementally arriving training data batches, has gained much attention recently in AI and computer vision community due to both fundamental and practical perspectives of the problem. For mitigating the main difficulty of deep neural network(DNN)-based CIL, the catastrophic forgetting, recent work showed that a simple fine-tuning (FT) based schemes can outperform the earlier attempts of using knowledge distillation, particularly when a small-sized exemplar-memory for storing samples from the previously learned classes is allowed. The core limitation of the vanilla FT, however, is the severe classification score bias between the new and previously learned classes, and several state-of-the-art methods proposed to rectify the bias via additional post-processing of the scores. In this paper, we propose two simple modifications for the vanilla FT, separated softmax (SS) layer and ratio-preserving (RP) mini-batches for SGD updates. Our scheme, dubbed as SS-IL, is shown to give much more balanced class decisions, have much less biased scores, and outperform strong state-of-the-art baselines on several large-scale benchmark datasets, without any sophisticated post-processing of the scores. We also give several novel analyses our and baseline methods, confirming the effectiveness of our approach in CIL.