 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFooling Neural Network Interpretations via Adversarial Model Manipulation
Paper and Code
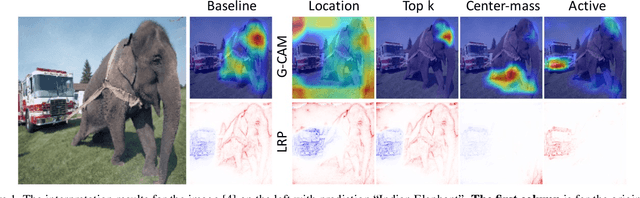
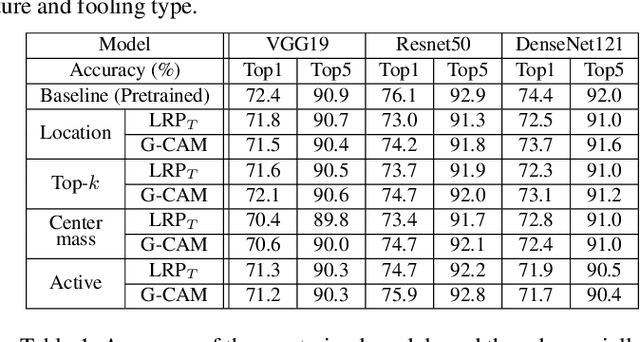
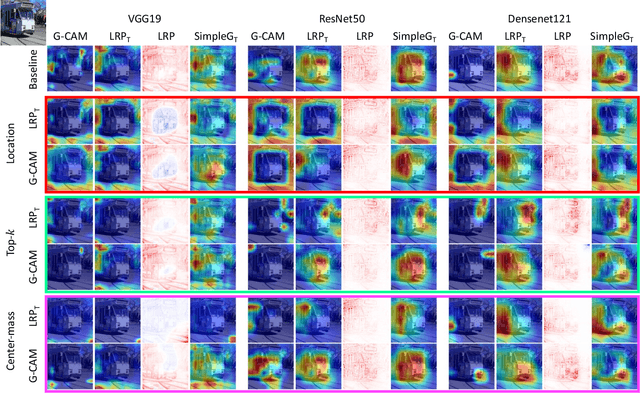

We ask whether the neural network interpretation methods can be fooled via adversarial model manipulation, which is defined as a model fine-tuning step that aims to radically alter the explanations without hurting the accuracy of the original model. By incorporating the interpretation results directly in the regularization term of the objective function for fine-tuning, we show that the state-of-the-art interpreters, e.g., LRP and Grad-CAM, can be easily fooled with our model manipulation. We propose two types of fooling, passive and active, and demonstrate such foolings generalize well to the entire validation set as well as transfer to other interpretation methods. Our results are validated by both visually showing the fooled explanations and reporting quantitative metrics that measure the deviations from the original explanations. We claim that the stability of neural network interpretation method with respect to our adversarial model manipulation is an important criterion to check for developing robust and reliable neural network interpretation method.