 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinding the Cracks: Improving LLMs Reasoning with Paraphrastic Probing and Consistency Verification
Feb 11, 2026Large language models have demonstrated impressive performance across a variety of reasoning tasks. However, their problem-solving ability often declines on more complex tasks due to hallucinations and the accumulation of errors within these intermediate steps. Recent work has introduced the notion of critical tokens--tokens in the reasoning process that exert significant influence on subsequent steps. Prior studies suggest that replacing critical tokens can refine reasoning trajectories. Nonetheless, reliably identifying and exploiting critical tokens remains challenging. To address this, we propose the Paraphrastic Probing and Consistency Verification~(PPCV) framework. PPCV operates in two stages. In the first stage, we roll out an initial reasoning path from the original question and then concatenate paraphrased versions of the question with this reasoning path. And we identify critical tokens based on mismatches between the predicted top-1 token and the expected token in the reasoning path. A criterion is employed to confirm the final critical token. In the second stage, we substitute critical tokens with candidate alternatives and roll out new reasoning paths for both the original and paraphrased questions. The final answer is determined by checking the consistency of outputs across these parallel reasoning processes. We evaluate PPCV on mainstream LLMs across multiple benchmarks. Extensive experiments demonstrate PPCV substantially enhances the reasoning performance of LLMs compared to baselines.
Unified Dense Prediction of Video Diffusion
Mar 12, 2025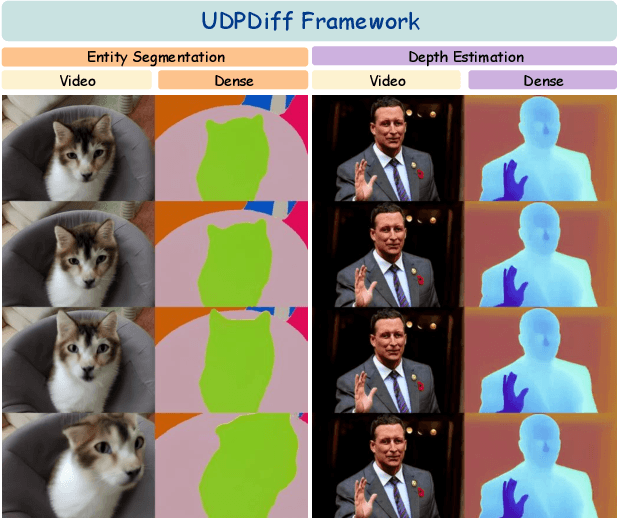
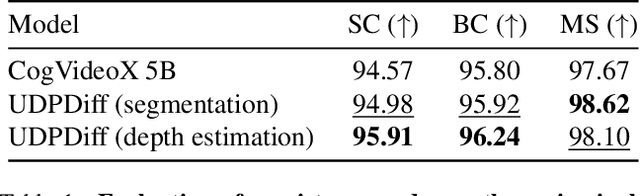
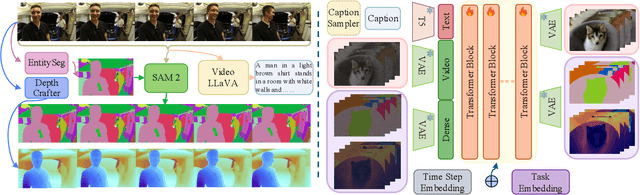
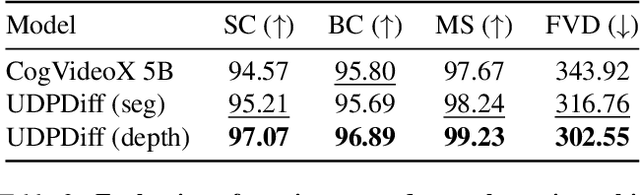
We present a unified network for simultaneously generating videos and their corresponding entity segmentation and depth maps from text prompts. We utilize colormap to represent entity masks and depth maps, tightly integrating dense prediction with RGB video generation. Introducing dense prediction information improves video generation's consistency and motion smoothness without increasing computational costs. Incorporating learnable task embeddings brings multiple dense prediction tasks into a single model, enhancing flexibility and further boosting performance. We further propose a large-scale dense prediction video dataset~\datasetname, addressing the issue that existing datasets do not concurrently contain captions, videos, segmentation, or depth maps. Comprehensive experiments demonstrate the high efficiency of our method, surpassing the state-of-the-art in terms of video quality, consistency, and motion smoothness.
The Ninth NTIRE 2024 Efficient Super-Resolution Challenge Report
Apr 16, 2024



This paper provides a comprehensive review of the NTIRE 2024 challenge, focusing on efficient single-image super-resolution (ESR) solutions and their outcomes. The task of this challenge is to super-resolve an input image with a magnification factor of x4 based on pairs of low and corresponding high-resolution images. The primary objective is to develop networks that optimize various aspects such as runtime, parameters, and FLOPs, while still maintaining a peak signal-to-noise ratio (PSNR) of approximately 26.90 dB on the DIV2K_LSDIR_valid dataset and 26.99 dB on the DIV2K_LSDIR_test dataset. In addition, this challenge has 4 tracks including the main track (overall performance), sub-track 1 (runtime), sub-track 2 (FLOPs), and sub-track 3 (parameters). In the main track, all three metrics (ie runtime, FLOPs, and parameter count) were considered. The ranking of the main track is calculated based on a weighted sum-up of the scores of all other sub-tracks. In sub-track 1, the practical runtime performance of the submissions was evaluated, and the corresponding score was used to determine the ranking. In sub-track 2, the number of FLOPs was considered. The score calculated based on the corresponding FLOPs was used to determine the ranking. In sub-track 3, the number of parameters was considered. The score calculated based on the corresponding parameters was used to determine the ranking. RLFN is set as the baseline for efficiency measurement. The challenge had 262 registered participants, and 34 teams made valid submissions. They gauge the state-of-the-art in efficient single-image super-resolution. To facilitate the reproducibility of the challenge and enable other researchers to build upon these findings, the code and the pre-trained model of validated solutions are made publicly available at https://github.com/Amazingren/NTIRE2024_ESR/.
Generalizable Entity Grounding via Assistance of Large Language Model
Feb 04, 2024

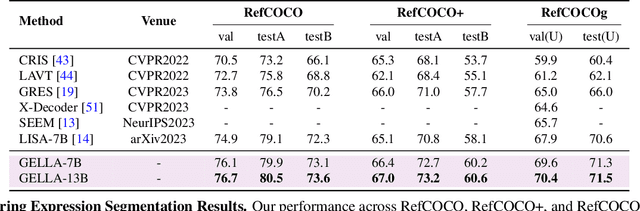

In this work, we propose a novel approach to densely ground visual entities from a long caption. We leverage a large multimodal model (LMM) to extract semantic nouns, a class-agnostic segmentation model to generate entity-level segmentation, and the proposed multi-modal feature fusion module to associate each semantic noun with its corresponding segmentation mask. Additionally, we introduce a strategy of encoding entity segmentation masks into a colormap, enabling the preservation of fine-grained predictions from features of high-resolution masks. This approach allows us to extract visual features from low-resolution images using the CLIP vision encoder in the LMM, which is more computationally efficient than existing approaches that use an additional encoder for high-resolution images. Our comprehensive experiments demonstrate the superiority of our method, outperforming state-of-the-art techniques on three tasks, including panoptic narrative grounding, referring expression segmentation, and panoptic segmentation.
UniGS: Unified Representation for Image Generation and Segmentation
Dec 04, 2023



This paper introduces a novel unified representation of diffusion models for image generation and segmentation. Specifically, we use a colormap to represent entity-level masks, addressing the challenge of varying entity numbers while aligning the representation closely with the image RGB domain. Two novel modules, including the location-aware color palette and progressive dichotomy module, are proposed to support our mask representation. On the one hand, a location-aware palette guarantees the colors' consistency to entities' locations. On the other hand, the progressive dichotomy module can efficiently decode the synthesized colormap to high-quality entity-level masks in a depth-first binary search without knowing the cluster numbers. To tackle the issue of lacking large-scale segmentation training data, we employ an inpainting pipeline and then improve the flexibility of diffusion models across various tasks, including inpainting, image synthesis, referring segmentation, and entity segmentation. Comprehensive experiments validate the efficiency of our approach, demonstrating comparable segmentation mask quality to state-of-the-art and adaptability to multiple tasks. The code will be released at \href{https://github.com/qqlu/Entity}{https://github.com/qqlu/Entity}.
Rethinking the Knowledge Distillation From the Perspective of Model Calibration
Nov 03, 2021
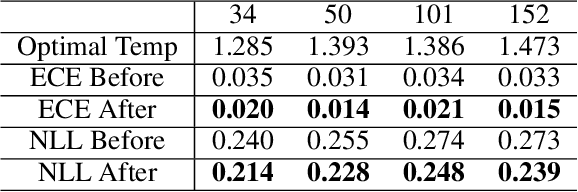
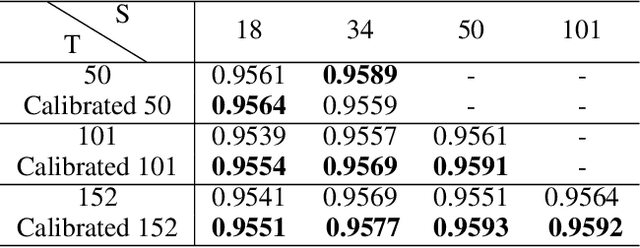
Recent years have witnessed dramatically improvements in the knowledge distillation, which can generate a compact student model for better efficiency while retaining the model effectiveness of the teacher model. Previous studies find that: more accurate teachers do not necessary make for better teachers due to the mismatch of abilities. In this paper, we aim to analysis the phenomenon from the perspective of model calibration. We found that the larger teacher model may be too over-confident, thus the student model cannot effectively imitate. While, after the simple model calibration of the teacher model, the size of the teacher model has a positive correlation with the performance of the student model.
NTIRE 2021 Multi-modal Aerial View Object Classification Challenge
Jul 02, 2021
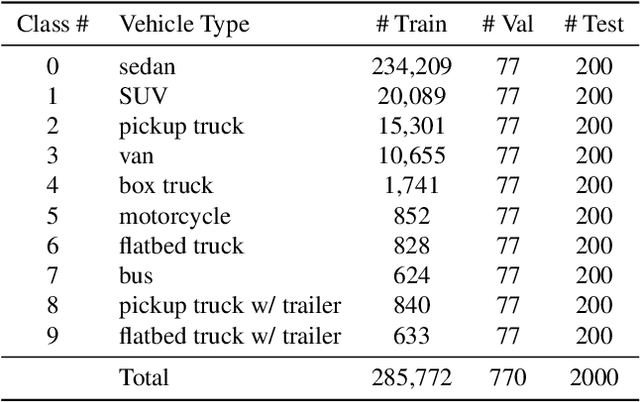
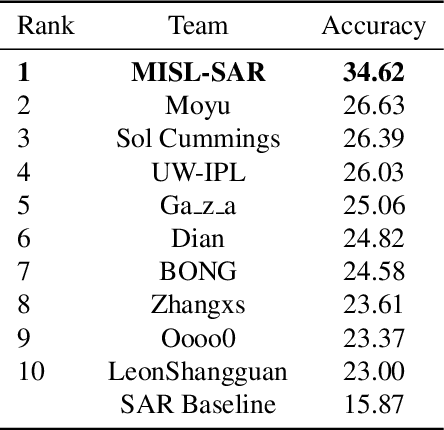
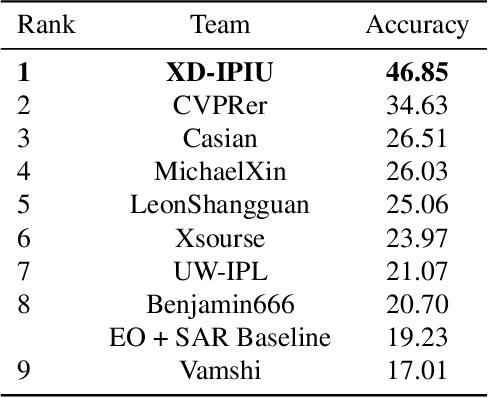
In this paper, we introduce the first Challenge on Multi-modal Aerial View Object Classification (MAVOC) in conjunction with the NTIRE 2021 workshop at CVPR. This challenge is composed of two different tracks using EO andSAR imagery. Both EO and SAR sensors possess different advantages and drawbacks. The purpose of this competition is to analyze how to use both sets of sensory information in complementary ways. We discuss the top methods submitted for this competition and evaluate their results on our blind test set. Our challenge results show significant improvement of more than 15% accuracy from our current baselines for each track of the competition
* 10 pages, 1 figure. Conference on Computer Vision and Pattern Recognition
NTIRE 2021 Challenge on Perceptual Image Quality Assessment
May 11, 2021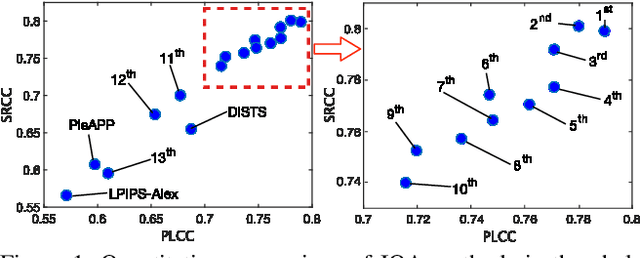
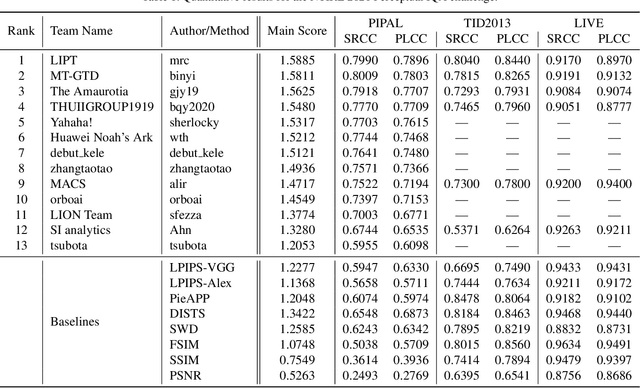

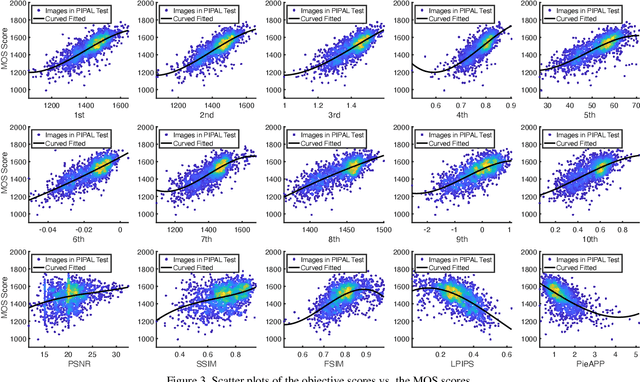
This paper reports on the NTIRE 2021 challenge on perceptual image quality assessment (IQA), held in conjunction with the New Trends in Image Restoration and Enhancement workshop (NTIRE) workshop at CVPR 2021. As a new type of image processing technology, perceptual image processing algorithms based on Generative Adversarial Networks (GAN) have produced images with more realistic textures. These output images have completely different characteristics from traditional distortions, thus pose a new challenge for IQA methods to evaluate their visual quality. In comparison with previous IQA challenges, the training and testing datasets in this challenge include the outputs of perceptual image processing algorithms and the corresponding subjective scores. Thus they can be used to develop and evaluate IQA methods on GAN-based distortions. The challenge has 270 registered participants in total. In the final testing stage, 13 participating teams submitted their models and fact sheets. Almost all of them have achieved much better results than existing IQA methods, while the winning method can demonstrate state-of-the-art performance.