 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralizable Entity Grounding via Assistance of Large Language Model
Paper and Code
Feb 04, 2024

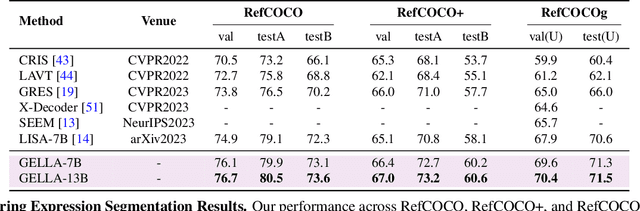

In this work, we propose a novel approach to densely ground visual entities from a long caption. We leverage a large multimodal model (LMM) to extract semantic nouns, a class-agnostic segmentation model to generate entity-level segmentation, and the proposed multi-modal feature fusion module to associate each semantic noun with its corresponding segmentation mask. Additionally, we introduce a strategy of encoding entity segmentation masks into a colormap, enabling the preservation of fine-grained predictions from features of high-resolution masks. This approach allows us to extract visual features from low-resolution images using the CLIP vision encoder in the LMM, which is more computationally efficient than existing approaches that use an additional encoder for high-resolution images. Our comprehensive experiments demonstrate the superiority of our method, outperforming state-of-the-art techniques on three tasks, including panoptic narrative grounding, referring expression segmentation, and panoptic segmentation.