 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified Dense Prediction of Video Diffusion
Paper and Code
Mar 12, 2025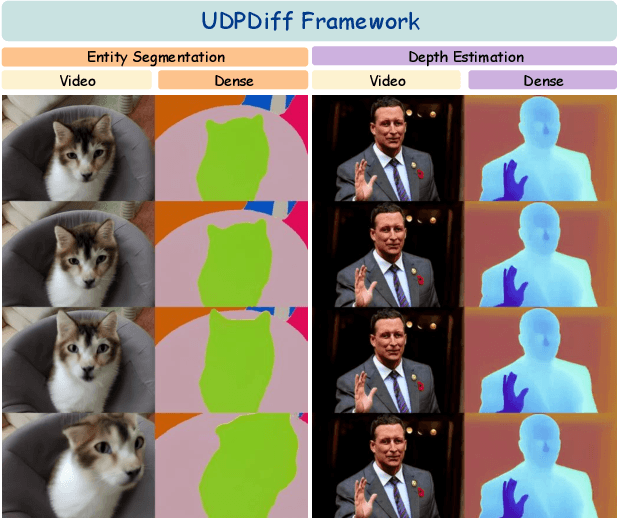
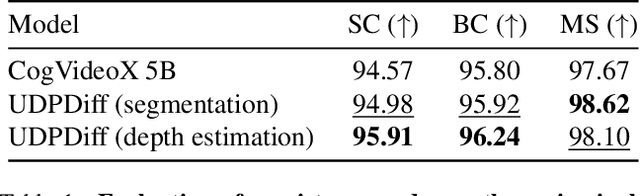
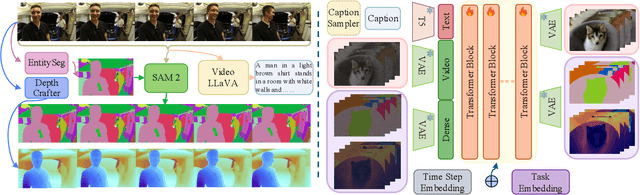
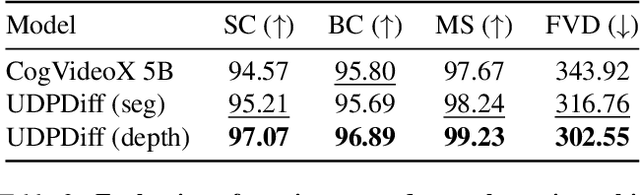
We present a unified network for simultaneously generating videos and their corresponding entity segmentation and depth maps from text prompts. We utilize colormap to represent entity masks and depth maps, tightly integrating dense prediction with RGB video generation. Introducing dense prediction information improves video generation's consistency and motion smoothness without increasing computational costs. Incorporating learnable task embeddings brings multiple dense prediction tasks into a single model, enhancing flexibility and further boosting performance. We further propose a large-scale dense prediction video dataset~\datasetname, addressing the issue that existing datasets do not concurrently contain captions, videos, segmentation, or depth maps. Comprehensive experiments demonstrate the high efficiency of our method, surpassing the state-of-the-art in terms of video quality, consistency, and motion smoothness.