Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking the Knowledge Distillation From the Perspective of Model Calibration
Nov 03, 2021
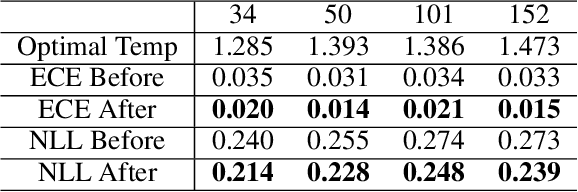
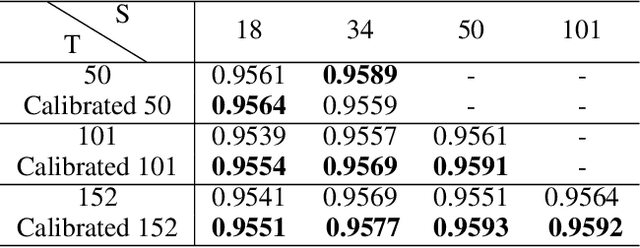
Recent years have witnessed dramatically improvements in the knowledge distillation, which can generate a compact student model for better efficiency while retaining the model effectiveness of the teacher model. Previous studies find that: more accurate teachers do not necessary make for better teachers due to the mismatch of abilities. In this paper, we aim to analysis the phenomenon from the perspective of model calibration. We found that the larger teacher model may be too over-confident, thus the student model cannot effectively imitate. While, after the simple model calibration of the teacher model, the size of the teacher model has a positive correlation with the performance of the student model.
Via