 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChimera: Harnessing Multi-Agent LLMs for Automatic Insider Threat Simulation
Aug 12, 2025Insider threats, which can lead to severe losses, remain a major security concern. While machine learning-based insider threat detection (ITD) methods have shown promising results, their progress is hindered by the scarcity of high-quality data. Enterprise data is sensitive and rarely accessible, while publicly available datasets, when limited in scale due to cost, lack sufficient real-world coverage; and when purely synthetic, they fail to capture rich semantics and realistic user behavior. To address this, we propose Chimera, the first large language model (LLM)-based multi-agent framework that automatically simulates both benign and malicious insider activities and collects diverse logs across diverse enterprise environments. Chimera models each employee with agents that have role-specific behavior and integrates modules for group meetings, pairwise interactions, and autonomous scheduling, capturing realistic organizational dynamics. It incorporates 15 types of insider attacks (e.g., IP theft, system sabotage) and has been deployed to simulate activities in three sensitive domains: technology company, finance corporation, and medical institution, producing a new dataset, ChimeraLog. We assess ChimeraLog via human studies and quantitative analysis, confirming its diversity, realism, and presence of explainable threat patterns. Evaluations of existing ITD methods show an average F1-score of 0.83, which is significantly lower than 0.99 on the CERT dataset, demonstrating ChimeraLog's higher difficulty and utility for advancing ITD research.
Who is Undercover? Guiding LLMs to Explore Multi-Perspective Team Tactic in the Game
Oct 20, 2024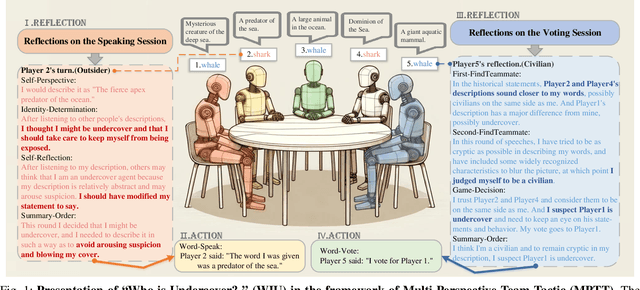

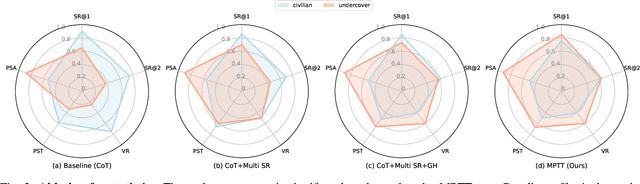

Large Language Models (LLMs) are pivotal AI agents in complex tasks but still face challenges in open decision-making problems within complex scenarios. To address this, we use the language logic game ``Who is Undercover?'' (WIU) as an experimental platform to propose the Multi-Perspective Team Tactic (MPTT) framework. MPTT aims to cultivate LLMs' human-like language expression logic, multi-dimensional thinking, and self-perception in complex scenarios. By alternating speaking and voting sessions, integrating techniques like self-perspective, identity-determination, self-reflection, self-summary and multi-round find-teammates, LLM agents make rational decisions through strategic concealment and communication, fostering human-like trust. Preliminary results show that MPTT, combined with WIU, leverages LLMs' cognitive capabilities to create a decision-making framework that can simulate real society. This framework aids minority groups in communication and expression, promoting fairness and diversity in decision-making. Additionally, our Human-in-the-loop experiments demonstrate that LLMs can learn and align with human behaviors through interactive, indicating their potential for active participation in societal decision-making.
Enhancing Deep Learning with Optimized Gradient Descent: Bridging Numerical Methods and Neural Network Training
Sep 07, 2024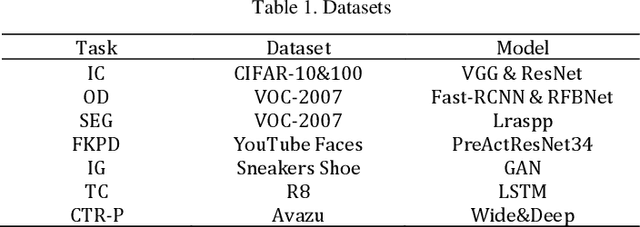

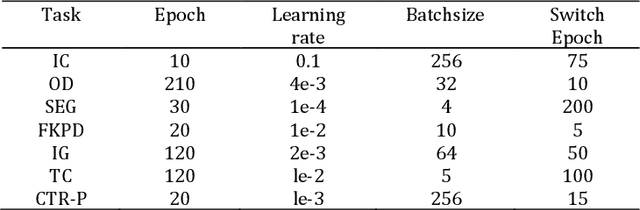
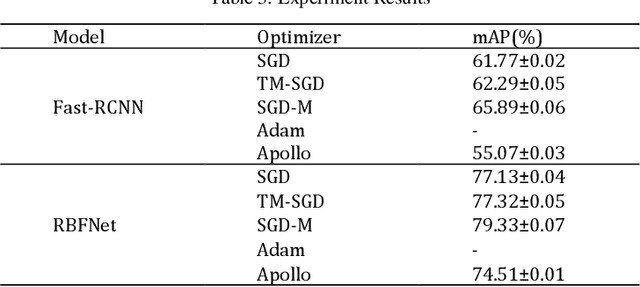
Optimization theory serves as a pivotal scientific instrument for achieving optimal system performance, with its origins in economic applications to identify the best investment strategies for maximizing benefits. Over the centuries, from the geometric inquiries of ancient Greece to the calculus contributions by Newton and Leibniz, optimization theory has significantly advanced. The persistent work of scientists like Lagrange, Cauchy, and von Neumann has fortified its progress. The modern era has seen an unprecedented expansion of optimization theory applications, particularly with the growth of computer science, enabling more sophisticated computational practices and widespread utilization across engineering, decision analysis, and operations research. This paper delves into the profound relationship between optimization theory and deep learning, highlighting the omnipresence of optimization problems in the latter. We explore the gradient descent algorithm and its variants, which are the cornerstone of optimizing neural networks. The chapter introduces an enhancement to the SGD optimizer, drawing inspiration from numerical optimization methods, aiming to enhance interpretability and accuracy. Our experiments on diverse deep learning tasks substantiate the improved algorithm's efficacy. The paper concludes by emphasizing the continuous development of optimization theory and its expanding role in solving intricate problems, enhancing computational capabilities, and informing better policy decisions.
Research on Optimization of Natural Language Processing Model Based on Multimodal Deep Learning
Jun 13, 2024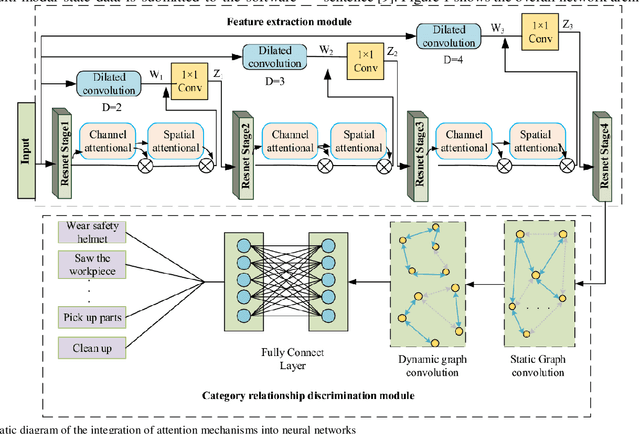


This project intends to study the image representation based on attention mechanism and multimodal data. By adding multiple pattern layers to the attribute model, the semantic and hidden layers of image content are integrated. The word vector is quantified by the Word2Vec method and then evaluated by a word embedding convolutional neural network. The published experimental results of the two groups were tested. The experimental results show that this method can convert discrete features into continuous characters, thus reducing the complexity of feature preprocessing. Word2Vec and natural language processing technology are integrated to achieve the goal of direct evaluation of missing image features. The robustness of the image feature evaluation model is improved by using the excellent feature analysis characteristics of a convolutional neural network. This project intends to improve the existing image feature identification methods and eliminate the subjective influence in the evaluation process. The findings from the simulation indicate that the novel approach has developed is viable, effectively augmenting the features within the produced representations.
Robust Dual-Modal Speech Keyword Spotting for XR Headsets
Jan 26, 2024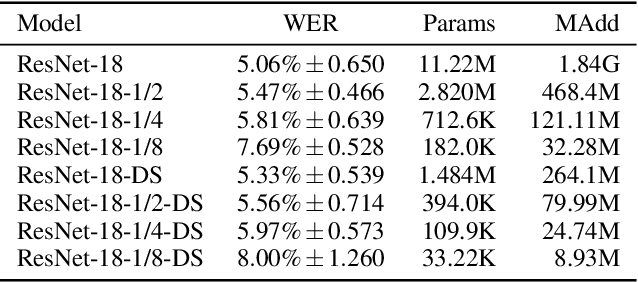
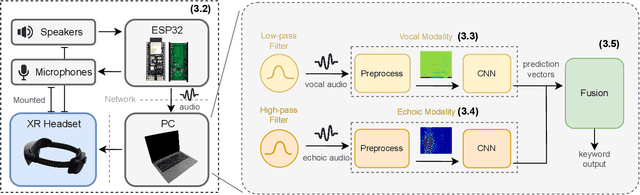

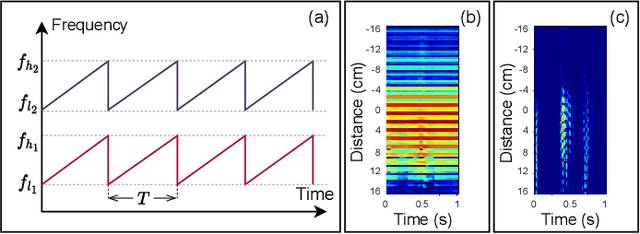
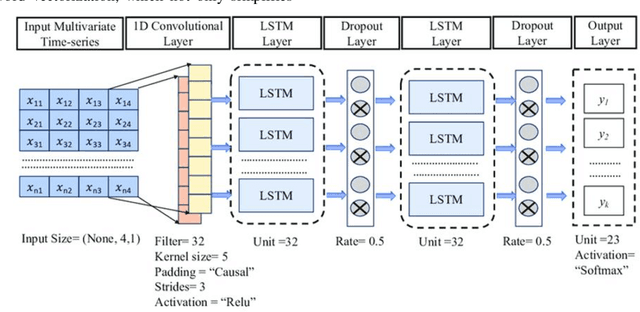
While speech interaction finds widespread utility within the Extended Reality (XR) domain, conventional vocal speech keyword spotting systems continue to grapple with formidable challenges, including suboptimal performance in noisy environments, impracticality in situations requiring silence, and susceptibility to inadvertent activations when others speak nearby. These challenges, however, can potentially be surmounted through the cost-effective fusion of voice and lip movement information. Consequently, we propose a novel vocal-echoic dual-modal keyword spotting system designed for XR headsets. We devise two different modal fusion approches and conduct experiments to test the system's performance across diverse scenarios. The results show that our dual-modal system not only consistently outperforms its single-modal counterparts, demonstrating higher precision in both typical and noisy environments, but also excels in accurately identifying silent utterances. Furthermore, we have successfully applied the system in real-time demonstrations, achieving promising results. The code is available at https://github.com/caizhuojiang/VE-KWS.
Sci-CoT: Leveraging Large Language Models for Enhanced Knowledge Distillation in Small Models for Scientific QA
Aug 09, 2023

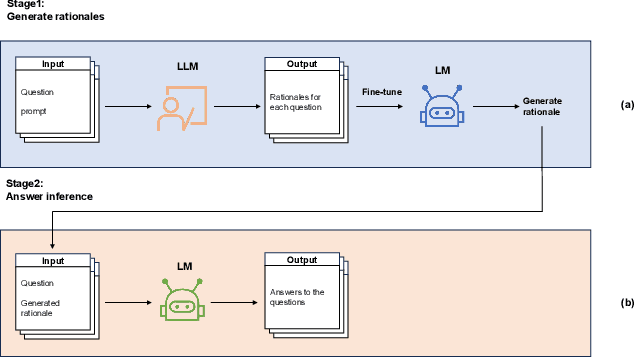
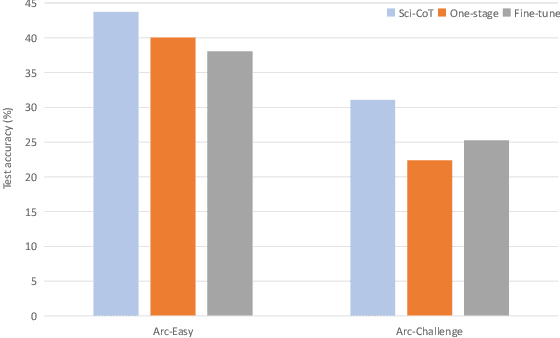
Large Language Models (LLMs) have shown outstanding performance across wide range of downstream tasks. This competency is attributed to their substantial parameter size and pre-training on extensive corpus. Moreover, LLMs have exhibited enhanced reasoning capabilities in tackling complex reasoning tasks, owing to the utilization of a method named ``Chain-of-Thought (CoT) prompting''. This method is designed to generate intermediate reasoning steps that guide the inference of the final answer. However, it is essential to highlight that these advanced reasoning abilities appear to emerge in models with a minimum of 10 billion parameters, thereby limiting its efficacy in situations where computational resources are constrained. In this paper, we investigate the possibility of transferring the reasoning capabilities of LLMs to smaller models via knowledge distillation. Specifically, we propose Sci-CoT, a two-stage framework that separates the processes of generating rationales and inferring answers. This method enables a more efficient use of rationales during the answer inference stage, leading to improved performance on scientific question-answering tasks. Utilizing Sci-CoT, our 80-million parameter model is able to exceed the performance of BLOOM-176B in the ARC-Easy dataset under the few shot setting.