 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGazeOnce360: Fisheye-Based 360° Multi-Person Gaze Estimation with Global-Local Feature Fusion
Mar 17, 2026We present GazeOnce360, a novel end-to-end model for multi-person gaze estimation from a single tabletop-mounted upward-facing fisheye camera. Unlike conventional approaches that rely on forward-facing cameras in constrained viewpoints, we address the underexplored setting of estimating the 3D gaze direction of multiple people distributed across a 360° scene from an upward fisheye perspective. To support research in this setting, we introduce MPSGaze360, a large-scale synthetic dataset rendered using Unreal Engine, featuring diverse multi-person configurations with accurate 3D gaze and eye landmark annotations. Our model tackles the severe distortion and perspective variation inherent in fisheye imagery by incorporating rotational convolutions and eye landmark supervision. To better capture fine-grained eye features crucial for gaze estimation, we propose a dual-resolution architecture that fuses global low-resolution context with high-resolution local eye regions. Experimental results demonstrate the effectiveness of each component in our model. This work highlights the feasibility and potential of fisheye-based 360° gaze estimation in practical multi-person scenarios. Project page: https://caizhuojiang.github.io/GazeOnce360/.
LSS3D: Learnable Spatial Shifting for Consistent and High-Quality 3D Generation from Single-Image
Nov 15, 2025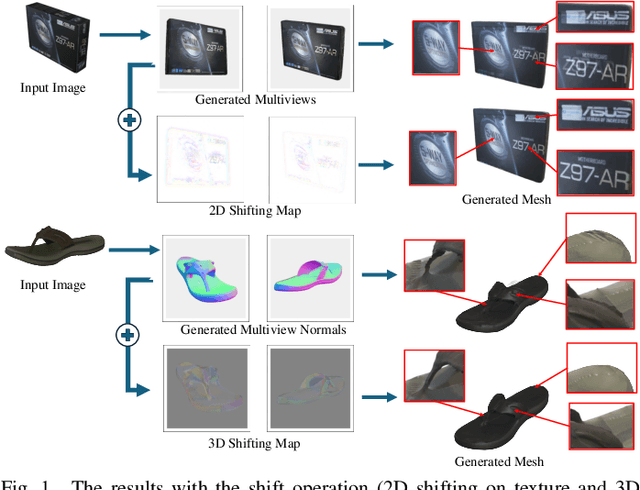
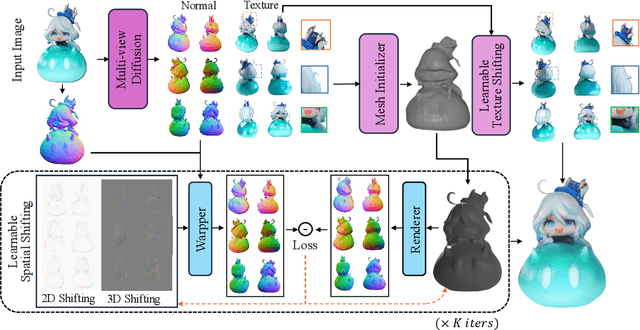

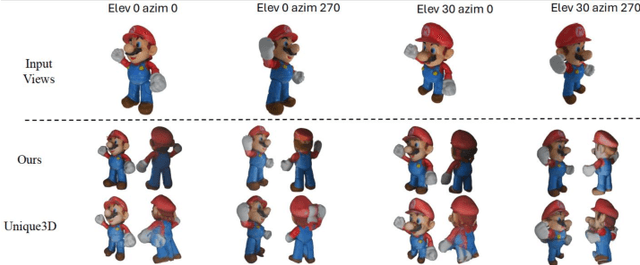
Recently, multi-view diffusion-based 3D generation methods have gained significant attention. However, these methods often suffer from shape and texture misalignment across generated multi-view images, leading to low-quality 3D generation results, such as incomplete geometric details and textural ghosting. Some methods are mainly optimized for the frontal perspective and exhibit poor robustness to oblique perspective inputs. In this paper, to tackle the above challenges, we propose a high-quality image-to-3D approach, named LSS3D, with learnable spatial shifting to explicitly and effectively handle the multiview inconsistencies and non-frontal input view. Specifically, we assign learnable spatial shifting parameters to each view, and adjust each view towards a spatially consistent target, guided by the reconstructed mesh, resulting in high-quality 3D generation with more complete geometric details and clean textures. Besides, we include the input view as an extra constraint for the optimization, further enhancing robustness to non-frontal input angles, especially for elevated viewpoint inputs. We also provide a comprehensive quantitative evaluation pipeline that can contribute to the community in performance comparisons. Extensive experiments demonstrate that our method consistently achieves leading results in both geometric and texture evaluation metrics across more flexible input viewpoints.
Robust Dual-Modal Speech Keyword Spotting for XR Headsets
Jan 26, 2024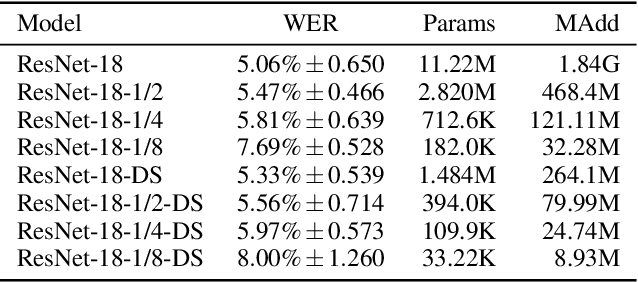
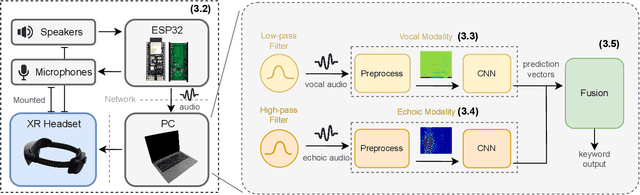

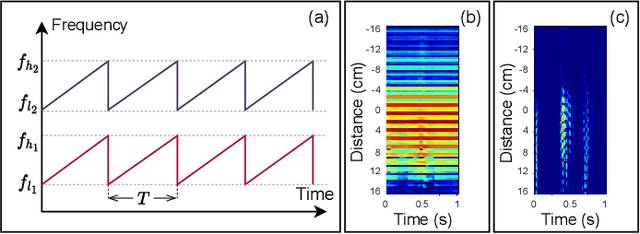
While speech interaction finds widespread utility within the Extended Reality (XR) domain, conventional vocal speech keyword spotting systems continue to grapple with formidable challenges, including suboptimal performance in noisy environments, impracticality in situations requiring silence, and susceptibility to inadvertent activations when others speak nearby. These challenges, however, can potentially be surmounted through the cost-effective fusion of voice and lip movement information. Consequently, we propose a novel vocal-echoic dual-modal keyword spotting system designed for XR headsets. We devise two different modal fusion approches and conduct experiments to test the system's performance across diverse scenarios. The results show that our dual-modal system not only consistently outperforms its single-modal counterparts, demonstrating higher precision in both typical and noisy environments, but also excels in accurately identifying silent utterances. Furthermore, we have successfully applied the system in real-time demonstrations, achieving promising results. The code is available at https://github.com/caizhuojiang/VE-KWS.