 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-free Dense Depth Distillation
Paper and Code
Aug 26, 2022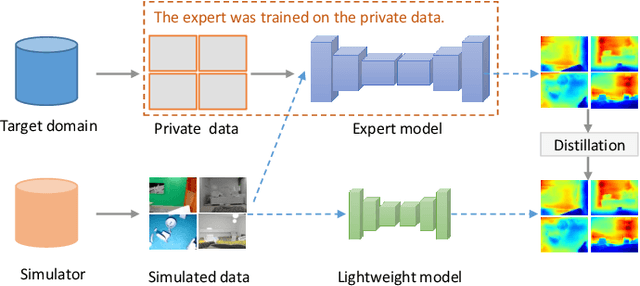
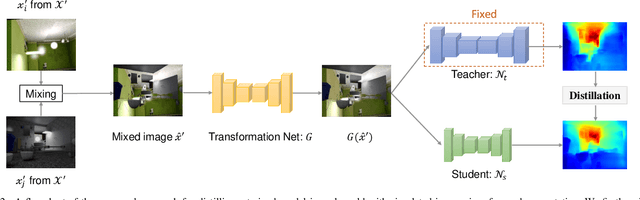

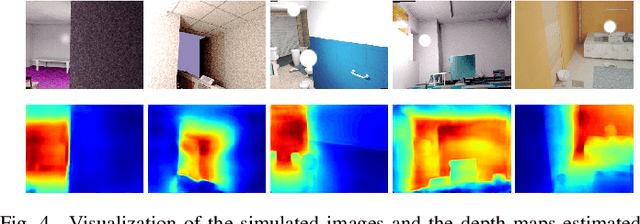
We study data-free knowledge distillation (KD) for monocular depth estimation (MDE), which learns a lightweight network for real-world depth perception by compressing from a trained expert model under the teacher-student framework while lacking training data in the target domain. Owing to the essential difference between dense regression and image recognition, previous methods of data-free KD are not applicable to MDE. To strengthen the applicability in the real world, in this paper, we seek to apply KD with out-of-distribution simulated images. The major challenges are i) lacking prior information about object distribution of the original training data; ii) the domain shift between the real world and the simulation. To cope with the first difficulty, we apply object-wise image mixing to generate new training samples for maximally covering distributed patterns of objects in the target domain. To tackle the second difficulty, we propose to utilize a transformation network that efficiently learns to fit the simulated data to the feature distribution of the teacher model. We evaluate the proposed approach for various depth estimation models and two different datasets. As a result, our method outperforms the baseline KD by a good margin and even achieves slightly better performance with as few as $1/6$ images, demonstrating a clear superiority.