 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEdge-Centric Relational Reasoning for 3D Scene Graph Prediction
Nov 19, 2025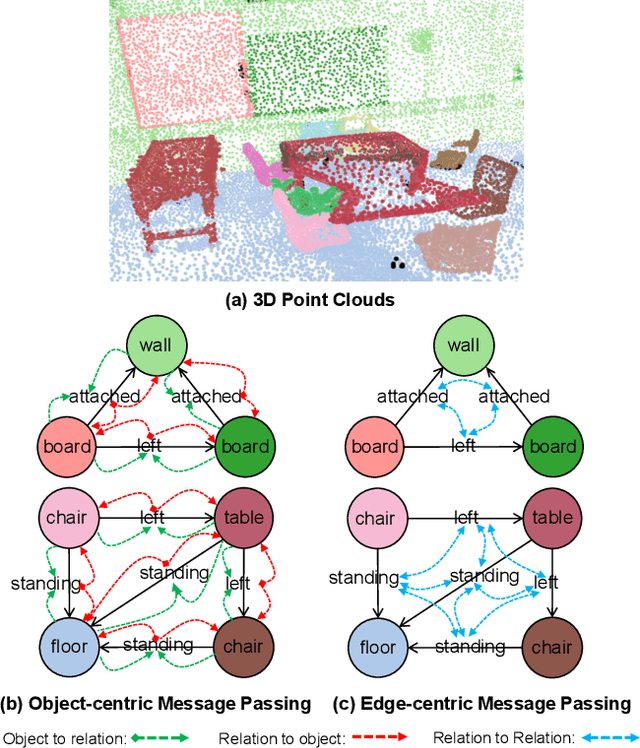
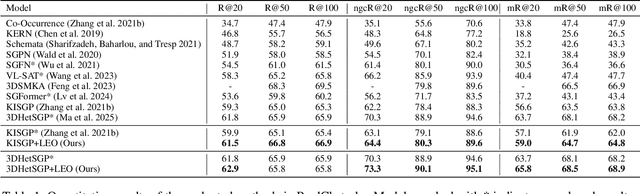
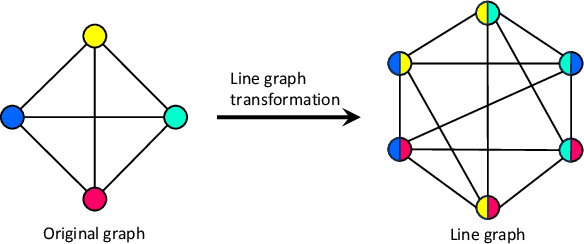
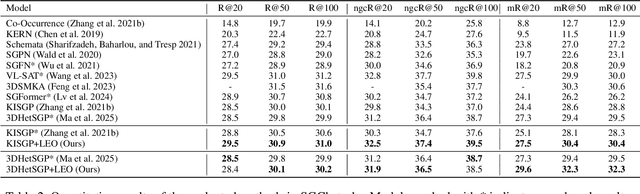
3D scene graph prediction aims to abstract complex 3D environments into structured graphs consisting of objects and their pairwise relationships. Existing approaches typically adopt object-centric graph neural networks, where relation edge features are iteratively updated by aggregating messages from connected object nodes. However, this design inherently restricts relation representations to pairwise object context, making it difficult to capture high-order relational dependencies that are essential for accurate relation prediction. To address this limitation, we propose a Link-guided Edge-centric relational reasoning framework with Object-aware fusion, namely LEO, which enables progressive reasoning from relation-level context to object-level understanding. Specifically, LEO first predicts potential links between object pairs to suppress irrelevant edges, and then transforms the original scene graph into a line graph where each relation is treated as a node. A line graph neural network is applied to perform edge-centric relational reasoning to capture inter-relation context. The enriched relation features are subsequently integrated into the original object-centric graph to enhance object-level reasoning and improve relation prediction. Our framework is model-agnostic and can be integrated with any existing object-centric method. Experiments on the 3DSSG dataset with two competitive baselines show consistent improvements, highlighting the effectiveness of our edge-to-object reasoning paradigm.
Point Cloud Unsupervised Pre-training via 3D Gaussian Splatting
Nov 27, 2024



Pre-training on large-scale unlabeled datasets contribute to the model achieving powerful performance on 3D vision tasks, especially when annotations are limited. However, existing rendering-based self-supervised frameworks are computationally demanding and memory-intensive during pre-training due to the inherent nature of volume rendering. In this paper, we propose an efficient framework named GS$^3$ to learn point cloud representation, which seamlessly integrates fast 3D Gaussian Splatting into the rendering-based framework. The core idea behind our framework is to pre-train the point cloud encoder by comparing rendered RGB images with real RGB images, as only Gaussian points enriched with learned rich geometric and appearance information can produce high-quality renderings. Specifically, we back-project the input RGB-D images into 3D space and use a point cloud encoder to extract point-wise features. Then, we predict 3D Gaussian points of the scene from the learned point cloud features and uses a tile-based rasterizer for image rendering. Finally, the pre-trained point cloud encoder can be fine-tuned to adapt to various downstream 3D tasks, including high-level perception tasks such as 3D segmentation and detection, as well as low-level tasks such as 3D scene reconstruction. Extensive experiments on downstream tasks demonstrate the strong transferability of the pre-trained point cloud encoder and the effectiveness of our self-supervised learning framework. In addition, our GS$^3$ framework is highly efficient, achieving approximately 9$\times$ pre-training speedup and less than 0.25$\times$ memory cost compared to the previous rendering-based framework Ponder.
3D Scene Graph Guided Vision-Language Pre-training
Nov 27, 2024



3D vision-language (VL) reasoning has gained significant attention due to its potential to bridge the 3D physical world with natural language descriptions. Existing approaches typically follow task-specific, highly specialized paradigms. Therefore, these methods focus on a limited range of reasoning sub-tasks and rely heavily on the hand-crafted modules and auxiliary losses. This highlights the need for a simpler, unified and general-purpose model. In this paper, we leverage the inherent connection between 3D scene graphs and natural language, proposing a 3D scene graph-guided vision-language pre-training (VLP) framework. Our approach utilizes modality encoders, graph convolutional layers and cross-attention layers to learn universal representations that adapt to a variety of 3D VL reasoning tasks, thereby eliminating the need for task-specific designs. The pre-training objectives include: 1) Scene graph-guided contrastive learning, which leverages the strong correlation between 3D scene graphs and natural language to align 3D objects with textual features at various fine-grained levels; and 2) Masked modality learning, which uses cross-modality information to reconstruct masked words and 3D objects. Instead of directly reconstructing the 3D point clouds of masked objects, we use position clues to predict their semantic categories. Extensive experiments demonstrate that our pre-training model, when fine-tuned on several downstream tasks, achieves performance comparable to or better than existing methods in tasks such as 3D visual grounding, 3D dense captioning, and 3D question answering.