 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey of Knowledge Enhanced Pre-trained Models
Paper and Code
Oct 01, 2021
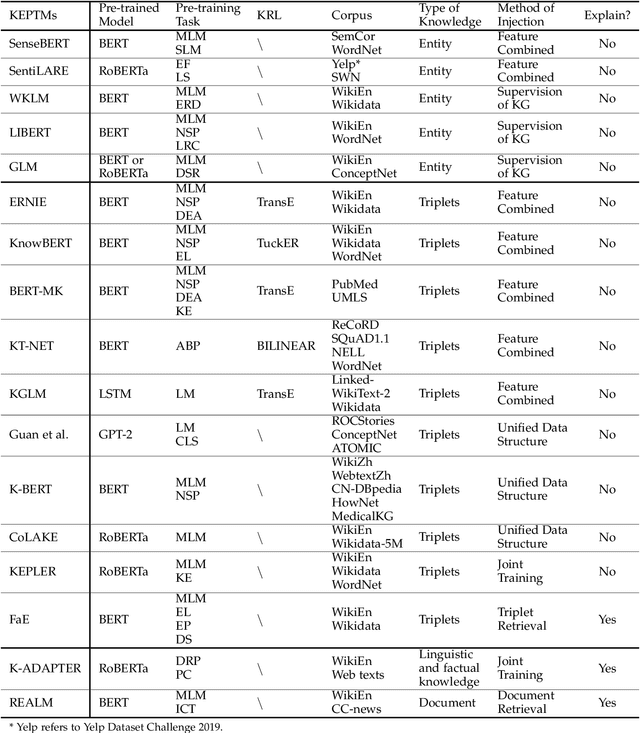

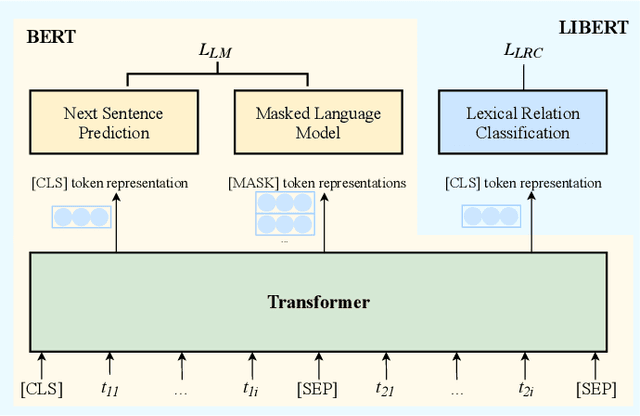
Pre-trained models learn contextualized word representations on large-scale text corpus through a self-supervised learning method, which has achieved promising performance after fine-tuning. These models, however, suffer from poor robustness and lack of interpretability. Pre-trained models with knowledge injection, which we call knowledge enhanced pre-trained models (KEPTMs), possess deep understanding and logical reasoning and introduce interpretability to some extent. In this survey, we provide a comprehensive overview of KEPTMs for natural language processing. We first introduce the progress of pre-trained models and knowledge representation learning. Then we systematically categorize existing KEPTMs from three different perspectives. Finally, we outline some potential directions of KEPTMs for future research.