 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Hierarchy Aware Features for Reducing Mistake Severity
Jul 26, 2022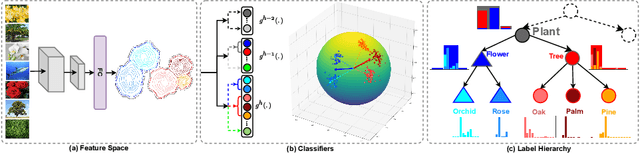

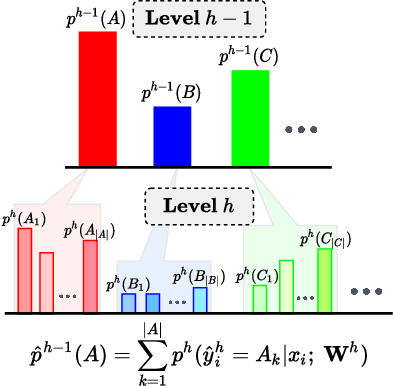
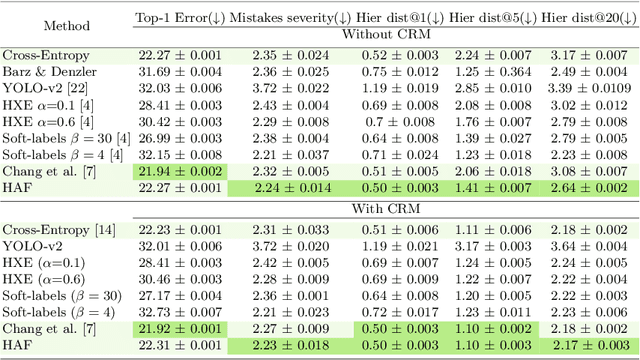
Label hierarchies are often available apriori as part of biological taxonomy or language datasets WordNet. Several works exploit these to learn hierarchy aware features in order to improve the classifier to make semantically meaningful mistakes while maintaining or reducing the overall error. In this paper, we propose a novel approach for learning Hierarchy Aware Features (HAF) that leverages classifiers at each level of the hierarchy that are constrained to generate predictions consistent with the label hierarchy. The classifiers are trained by minimizing a Jensen-Shannon Divergence with target soft labels obtained from the fine-grained classifiers. Additionally, we employ a simple geometric loss that constrains the feature space geometry to capture the semantic structure of the label space. HAF is a training time approach that improves the mistakes while maintaining top-1 error, thereby, addressing the problem of cross-entropy loss that treats all mistakes as equal. We evaluate HAF on three hierarchical datasets and achieve state-of-the-art results on the iNaturalist-19 and CIFAR-100 datasets. The source code is available at https://github.com/07Agarg/HAF
HIERMATCH: Leveraging Label Hierarchies for Improving Semi-Supervised Learning
Oct 30, 2021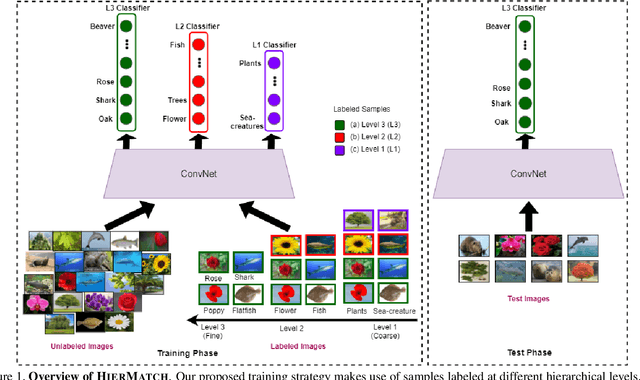
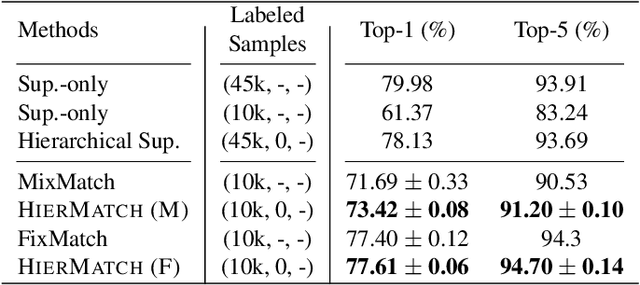
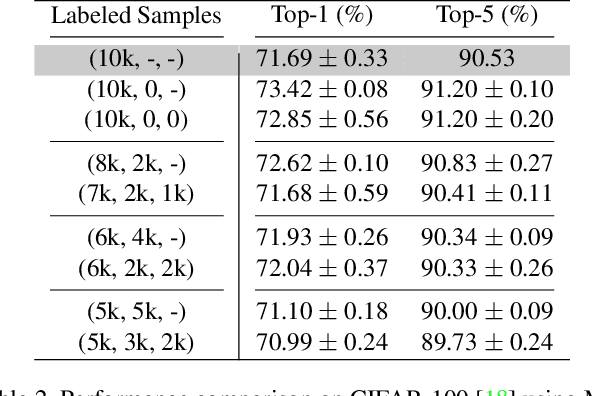
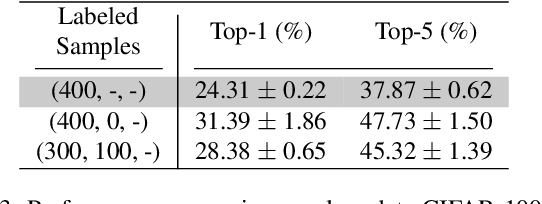
Semi-supervised learning approaches have emerged as an active area of research to combat the challenge of obtaining large amounts of annotated data. Towards the goal of improving the performance of semi-supervised learning methods, we propose a novel framework, HIERMATCH, a semi-supervised approach that leverages hierarchical information to reduce labeling costs and performs as well as a vanilla semi-supervised learning method. Hierarchical information is often available as prior knowledge in the form of coarse labels (e.g., woodpeckers) for images with fine-grained labels (e.g., downy woodpeckers or golden-fronted woodpeckers). However, the use of supervision using coarse category labels to improve semi-supervised techniques has not been explored. In the absence of fine-grained labels, HIERMATCH exploits the label hierarchy and uses coarse class labels as a weak supervisory signal. Additionally, HIERMATCH is a generic-approach to improve any semisupervised learning framework, we demonstrate this using our results on recent state-of-the-art techniques MixMatch and FixMatch. We evaluate the efficacy of HIERMATCH on two benchmark datasets, namely CIFAR-100 and NABirds. HIERMATCH can reduce the usage of fine-grained labels by 50% on CIFAR-100 with only a marginal drop of 0.59% in top-1 accuracy as compared to MixMatch.