 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Estimates At The Edge Using Intermittent And Aged Measurement Updates
Jan 20, 2022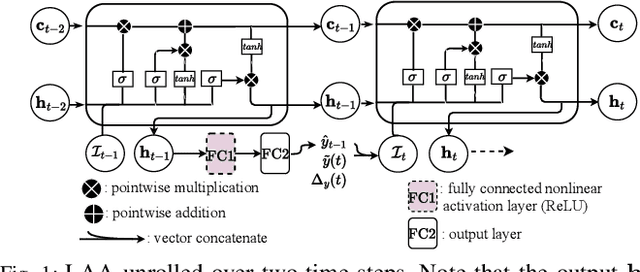
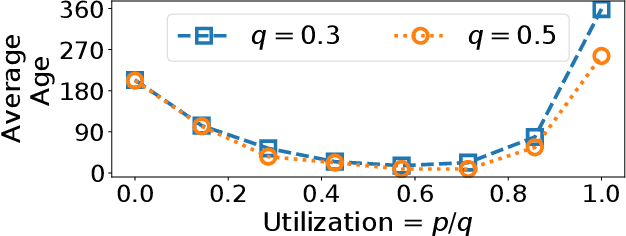
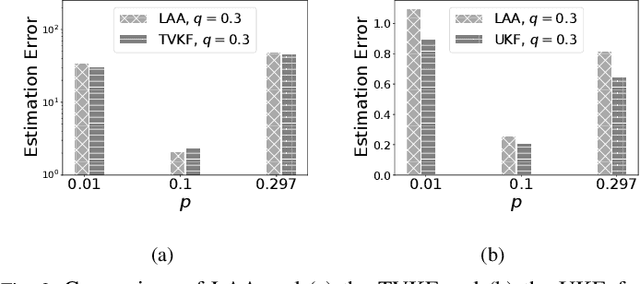
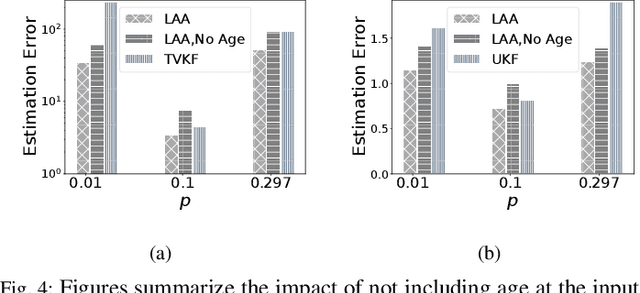
Cyber Physical Systems (CPS) applications have agents that actuate in their local vicinity, while requiring measurements that capture the state of their larger environment to make actuation choices. These measurements are made by sensors and communicated over a network as update packets. Network resource constraints dictate that updates arrive at an agent intermittently and be aged on their arrival. This can be alleviated by providing an agent with a fast enough rate of estimates of the measurements. Often works on estimation assume knowledge of the dynamic model of the system being measured. However, as CPS applications become pervasive, such information may not be available in practice. In this work, we propose a novel deep neural network architecture that leverages Long Short Term Memory (LSTM) networks to learn estimates in a model-free setting using only updates received over the network. We detail an online algorithm that enables training of our architecture. The architecture is shown to provide good estimates of measurements of both a linear and a non-linear dynamic system. It learns good estimates even when the learning proceeds over a generic network setting in which the distributions that govern the rate and age of received measurements may change significantly over time. We demonstrate the efficacy of the architecture by comparing it with the baselines of the Time-varying Kalman Filter and the Unscented Kalman Filter. The architecture enables empirical insights with regards to maintaining the ages of updates at the estimator, which are used by it and also the baselines.
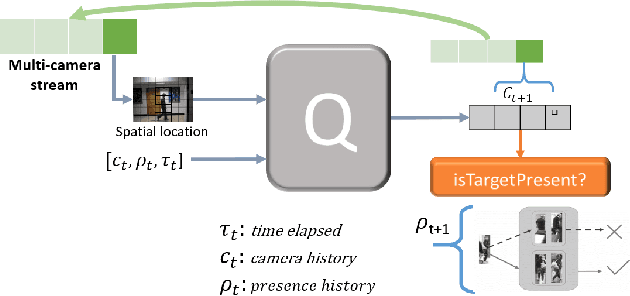
Intelligent Querying for Target Tracking in Camera Networks using Deep Q-Learning with n-Step Bootstrapping
Apr 20, 2020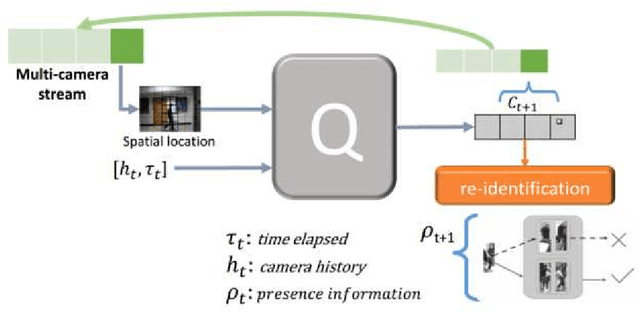
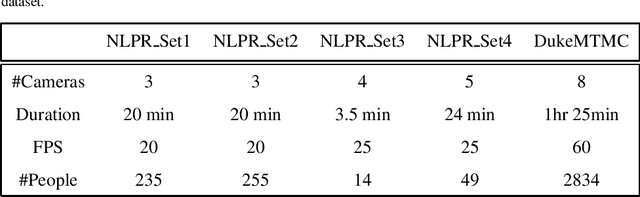
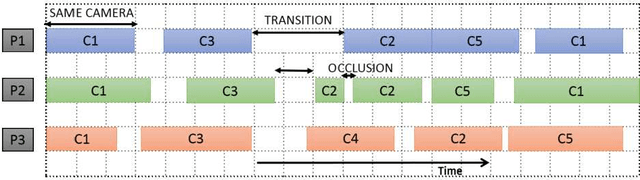
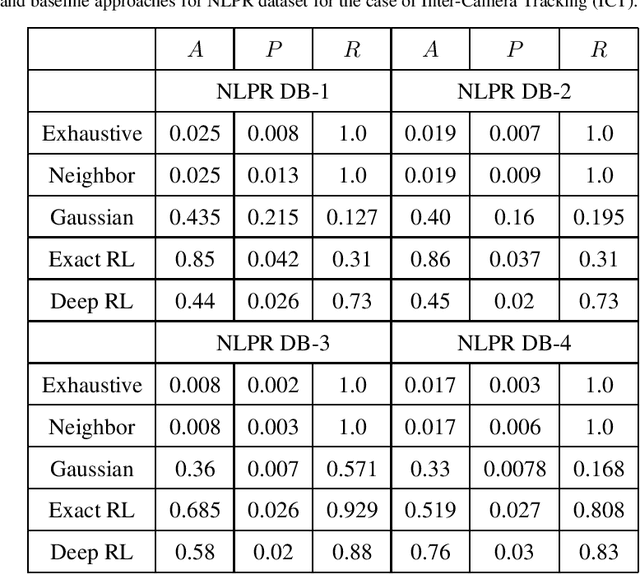
Surveillance camera networks are a useful infrastructure for various visual analytics applications, where high-level inferences and predictions could be made based on target tracking across the network. Most multi-camera tracking works focus on target re-identification and trajectory association problems to track the target. However, since camera networks can generate enormous amount of video data, inefficient schemes for making re-identification or trajectory association queries can incur prohibitively large computational requirements. In this paper, we address the problem of intelligent scheduling of re-identification queries in a multi-camera tracking setting. To this end, we formulate the target tracking problem in a camera network as an MDP and learn a reinforcement learning based policy that selects a camera for making a re-identification query. The proposed approach to camera selection does not assume the knowledge of the camera network topology but the resulting policy implicitly learns it. We have also shown that such a policy can be learnt directly from data. Using the NLPR MCT and the Duke MTMC multi-camera multi-target tracking benchmarks, we empirically show that the proposed approach substantially reduces the number of frames queried.
A Reinforcement Learning Approach to Target Tracking in a Camera Network
Jul 26, 2018
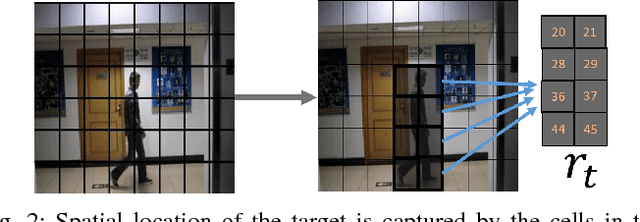
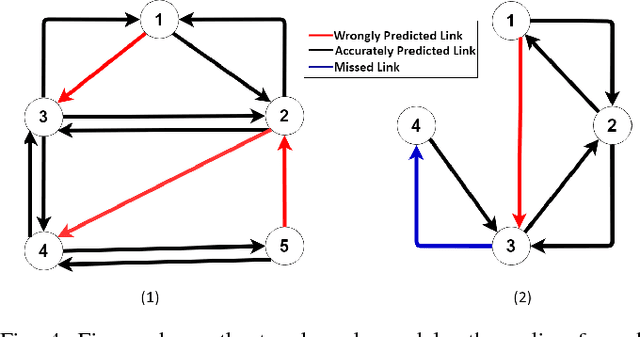
Target tracking in a camera network is an important task for surveillance and scene understanding. The task is challenging due to disjoint views and illumination variation in different cameras. In this direction, many graph-based methods were proposed using appearance-based features. However, the appearance information fades with high illumination variation in the different camera FOVs. We, in this paper, use spatial and temporal information as the state of the target to learn a policy that predicts the next camera given the current state. The policy is trained using Q-learning and it does not assume any information about the topology of the camera network. We will show that the policy learns the camera network topology. We demonstrate the performance of the proposed method on the NLPR MCT dataset.
A Reinforcement Learning Approach to Jointly Adapt Vehicular Communications and Planning for Optimized Driving
Jul 10, 2018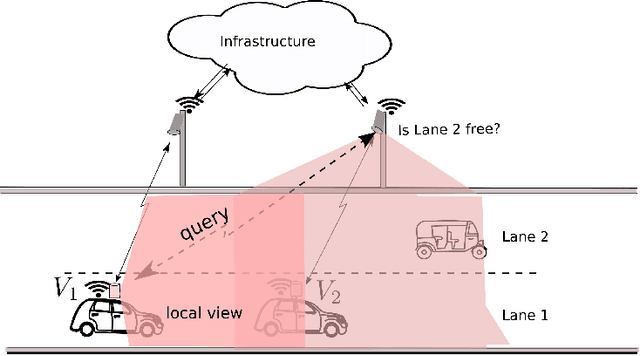
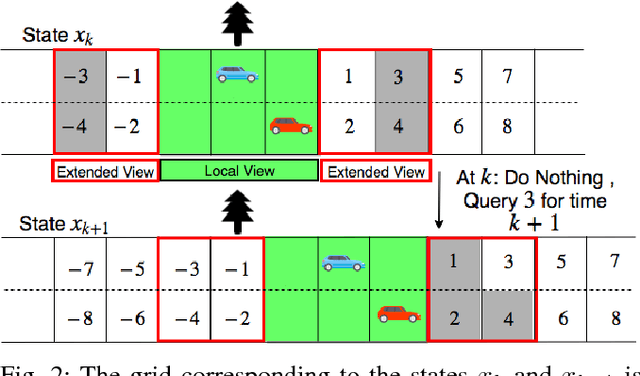
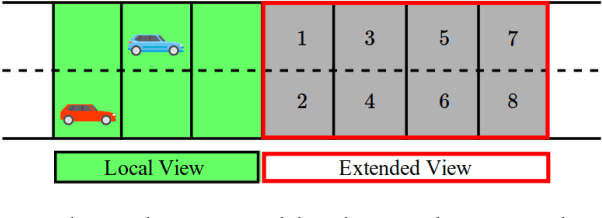
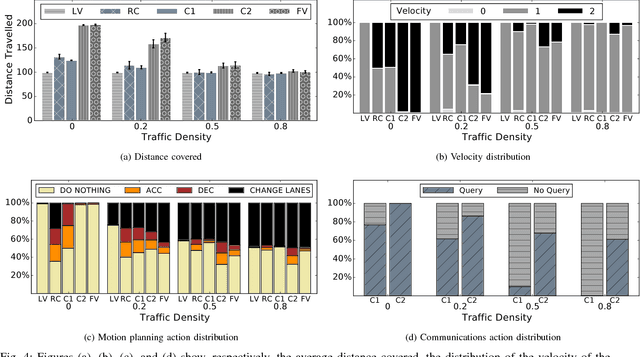
Our premise is that autonomous vehicles must optimize communications and motion planning jointly. Specifically, a vehicle must adapt its motion plan staying cognizant of communications rate related constraints and adapt the use of communications while being cognizant of motion planning related restrictions that may be imposed by the on-road environment. To this end, we formulate a reinforcement learning problem wherein an autonomous vehicle jointly chooses (a) a motion planning action that executes on-road and (b) a communications action of querying sensed information from the infrastructure. The goal is to optimize the driving utility of the autonomous vehicle. We apply the Q-learning algorithm to make the vehicle learn the optimal policy, which makes the optimal choice of planning and communications actions at any given time. We demonstrate the ability of the optimal policy to smartly adapt communications and planning actions, while achieving large driving utilities, using simulations.