 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHedging and Pricing Structured Products Featuring Multiple Underlying Assets
Nov 02, 2024



Hedging a portfolio containing autocallable notes presents unique challenges due to the complex risk profile of these financial instruments. In addition to hedging, pricing these notes, particularly when multiple underlying assets are involved, adds another layer of complexity. Pricing autocallable notes involves intricate considerations of various risk factors, including underlying assets, interest rates, and volatility. Traditional pricing methods, such as sample-based Monte Carlo simulations, are often time-consuming and impractical for long maturities, particularly when there are multiple underlying assets. In this paper, we explore autocallable structured notes with three underlying assets and proposes a machine learning-based pricing method that significantly improves efficiency, computing prices 250 times faster than traditional Monte Carlo simulation based method. Additionally, we introduce a Distributional Reinforcement Learning (RL) algorithm to hedge a portfolio containing an autocallable structured note. Our distributional RL based hedging strategy provides better PnL compared to traditional Delta-neutral and Delta-Gamma neutral hedging strategies. The VaR 5% (PnL value) of our RL agent based hedging is 33.95, significantly outperforming both the Delta neutral strategy, which has a VaR 5% of -0.04, and the Delta-Gamma neutral strategy, which has a VaR 5% of 13.05. It also provides the hedging action with better left tail PnL, such as 95% and 99% value-at-risk (VaR) and conditional value-at-risk (CVaR), highlighting its potential for front-office hedging and risk management.
* Workshop on Simulation of Financial Markets and Economic Systems
Intelligent Querying for Target Tracking in Camera Networks using Deep Q-Learning with n-Step Bootstrapping
Apr 20, 2020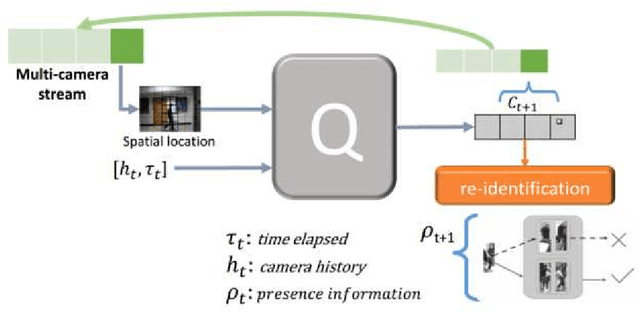
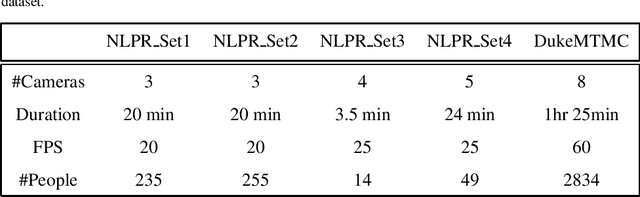
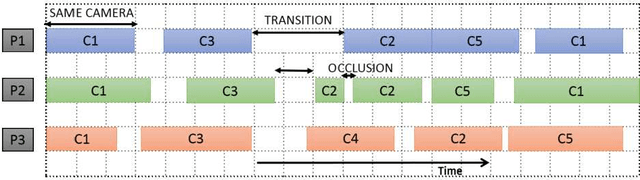
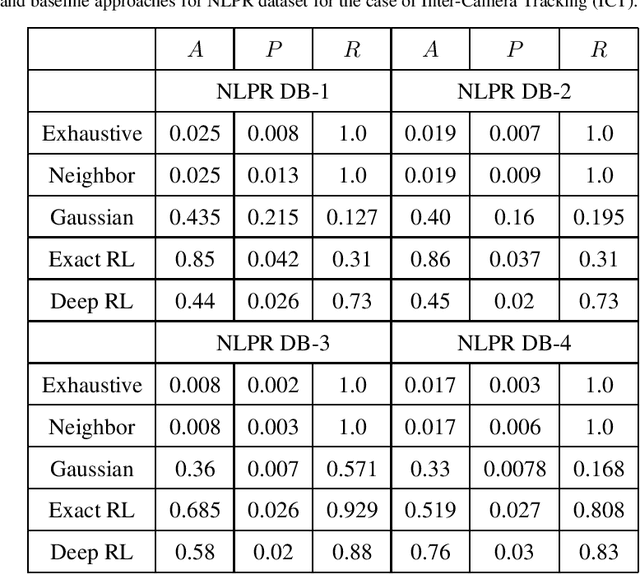
Surveillance camera networks are a useful infrastructure for various visual analytics applications, where high-level inferences and predictions could be made based on target tracking across the network. Most multi-camera tracking works focus on target re-identification and trajectory association problems to track the target. However, since camera networks can generate enormous amount of video data, inefficient schemes for making re-identification or trajectory association queries can incur prohibitively large computational requirements. In this paper, we address the problem of intelligent scheduling of re-identification queries in a multi-camera tracking setting. To this end, we formulate the target tracking problem in a camera network as an MDP and learn a reinforcement learning based policy that selects a camera for making a re-identification query. The proposed approach to camera selection does not assume the knowledge of the camera network topology but the resulting policy implicitly learns it. We have also shown that such a policy can be learnt directly from data. Using the NLPR MCT and the Duke MTMC multi-camera multi-target tracking benchmarks, we empirically show that the proposed approach substantially reduces the number of frames queried.
A Reinforcement Learning Approach to Target Tracking in a Camera Network
Jul 26, 2018
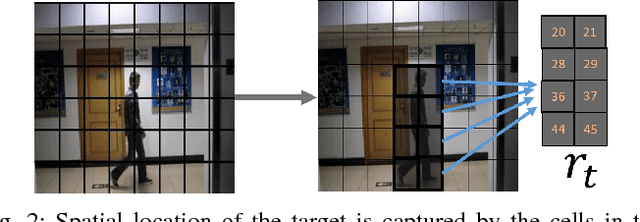
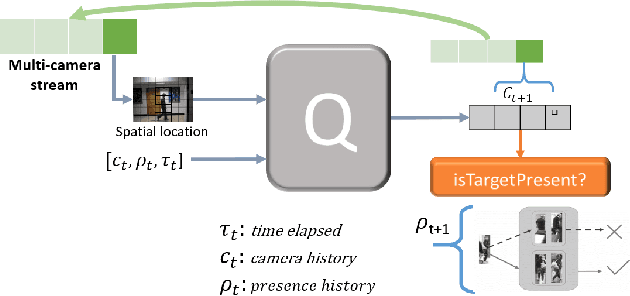
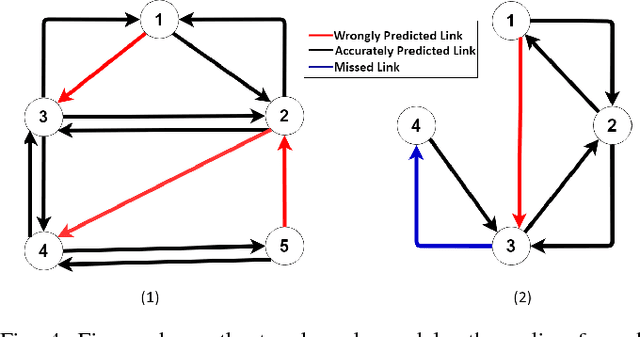
Target tracking in a camera network is an important task for surveillance and scene understanding. The task is challenging due to disjoint views and illumination variation in different cameras. In this direction, many graph-based methods were proposed using appearance-based features. However, the appearance information fades with high illumination variation in the different camera FOVs. We, in this paper, use spatial and temporal information as the state of the target to learn a policy that predicts the next camera given the current state. The policy is trained using Q-learning and it does not assume any information about the topology of the camera network. We will show that the policy learns the camera network topology. We demonstrate the performance of the proposed method on the NLPR MCT dataset.
A Reinforcement Learning Approach to Jointly Adapt Vehicular Communications and Planning for Optimized Driving
Jul 10, 2018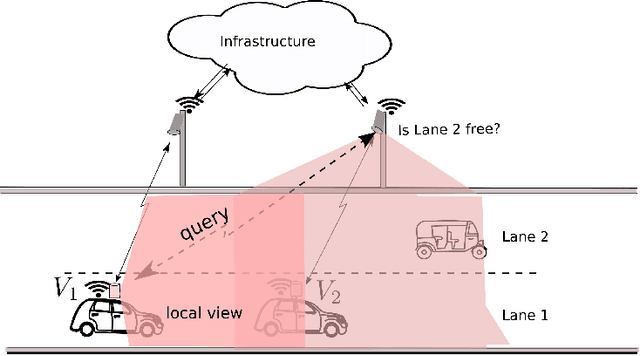
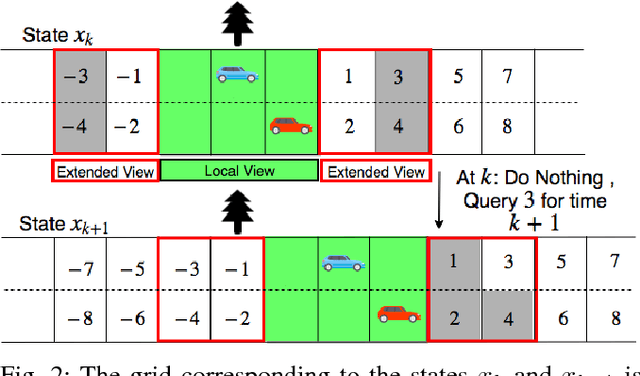
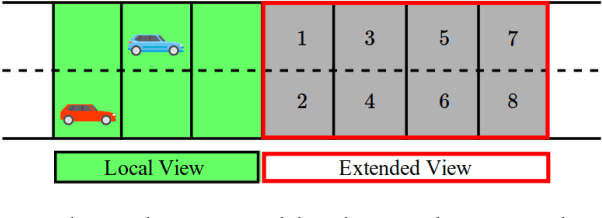
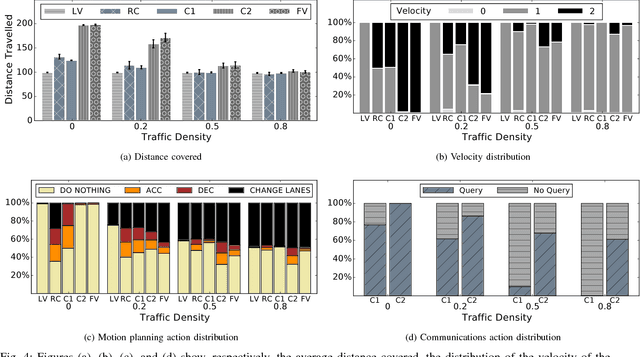
Our premise is that autonomous vehicles must optimize communications and motion planning jointly. Specifically, a vehicle must adapt its motion plan staying cognizant of communications rate related constraints and adapt the use of communications while being cognizant of motion planning related restrictions that may be imposed by the on-road environment. To this end, we formulate a reinforcement learning problem wherein an autonomous vehicle jointly chooses (a) a motion planning action that executes on-road and (b) a communications action of querying sensed information from the infrastructure. The goal is to optimize the driving utility of the autonomous vehicle. We apply the Q-learning algorithm to make the vehicle learn the optimal policy, which makes the optimal choice of planning and communications actions at any given time. We demonstrate the ability of the optimal policy to smartly adapt communications and planning actions, while achieving large driving utilities, using simulations.
Foresee: Attentive Future Projections of Chaotic Road Environments with Online Training
May 30, 2018
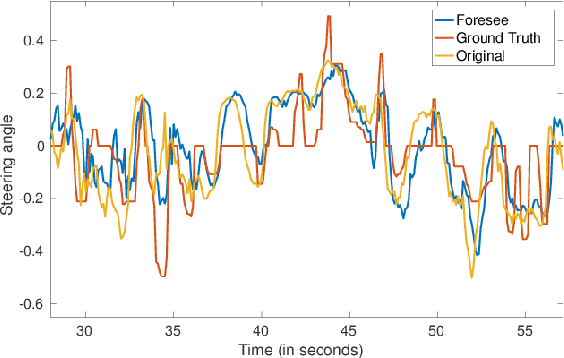
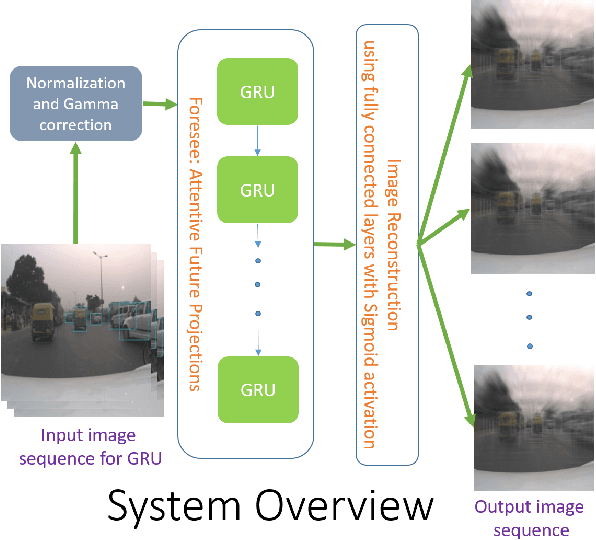

In this paper, we train a recurrent neural network to learn dynamics of a chaotic road environment and to project the future of the environment on an image. Future projection can be used to anticipate an unseen environment for example, in autonomous driving. Road environment is highly dynamic and complex due to the interaction among traffic participants such as vehicles and pedestrians. Even in this complex environment, a human driver is efficacious to safely drive on chaotic roads irrespective of the number of traffic participants. The proliferation of deep learning research has shown the efficacy of neural networks in learning this human behavior. In the same direction, we investigate recurrent neural networks to understand the chaotic road environment which is shared by pedestrians, vehicles (cars, trucks, bicycles etc.), and sometimes animals as well. We propose \emph{Foresee}, a unidirectional gated recurrent units (GRUs) network with attention to project future of the environment in the form of images. We have collected several videos on Delhi roads consisting of various traffic participants, background and infrastructure differences (like 3D pedestrian crossing) at various times on various days. We train \emph{Foresee} in an unsupervised way and we use online training to project frames up to $0.5$ seconds in advance. We show that our proposed model performs better than state of the art methods (prednet and Enc. Dec. LSTM) and finally, we show that our trained model generalizes to a public dataset for future projections.