 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReducing Annotation Effort by Identifying and Labeling Contextually Diverse Classes for Semantic Segmentation Under Domain Shift
Paper and Code
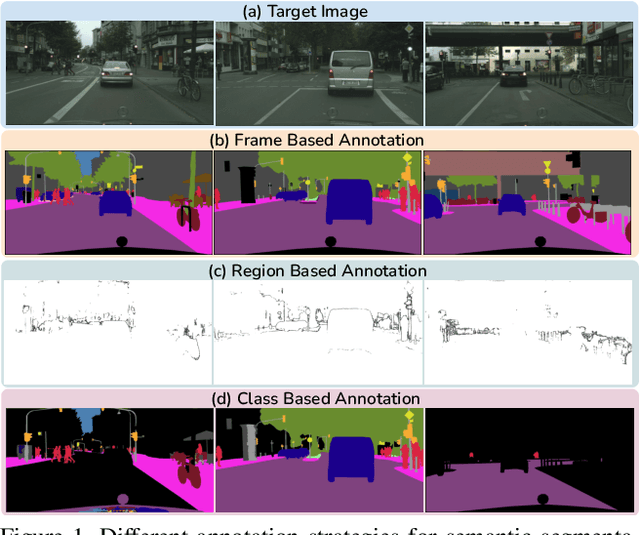
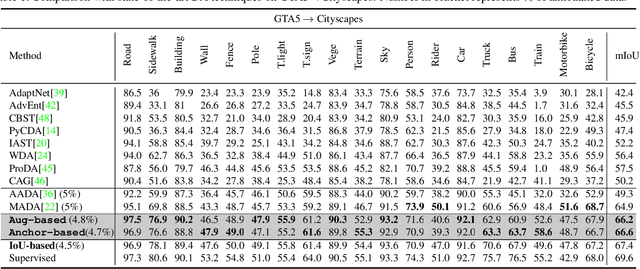
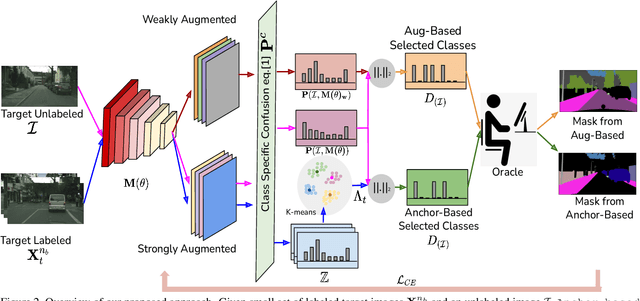
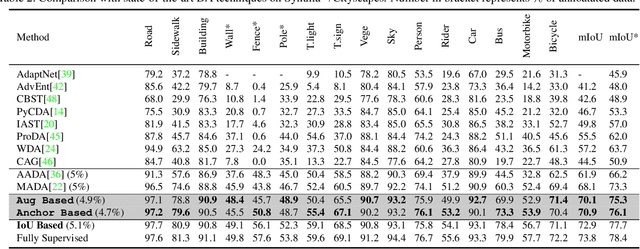
In Active Domain Adaptation (ADA), one uses Active Learning (AL) to select a subset of images from the target domain, which are then annotated and used for supervised domain adaptation (DA). Given the large performance gap between supervised and unsupervised DA techniques, ADA allows for an excellent trade-off between annotation cost and performance. Prior art makes use of measures of uncertainty or disagreement of models to identify `regions' to be annotated by the human oracle. However, these regions frequently comprise of pixels at object boundaries which are hard and tedious to annotate. Hence, even if the fraction of image pixels annotated reduces, the overall annotation time and the resulting cost still remain high. In this work, we propose an ADA strategy, which given a frame, identifies a set of classes that are hardest for the model to predict accurately, thereby recommending semantically meaningful regions to be annotated in a selected frame. We show that these set of `hard' classes are context-dependent and typically vary across frames, and when annotated help the model generalize better. We propose two ADA techniques: the Anchor-based and Augmentation-based approaches to select complementary and diverse regions in the context of the current training set. Our approach achieves 66.6 mIoU on GTA to Cityscapes dataset with an annotation budget of 4.7% in comparison to 64.9 mIoU by MADA using 5% of annotations. Our technique can also be used as a decorator for any existing frame-based AL technique, e.g., we report 1.5% performance improvement for CDAL on Cityscapes using our approach.