 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangling Representations using Gaussian Processes in Variational Autoencoders for Video Prediction
Jan 08, 2020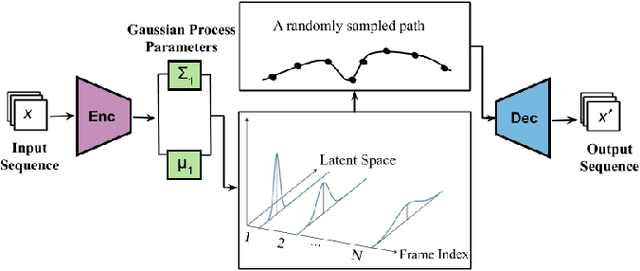
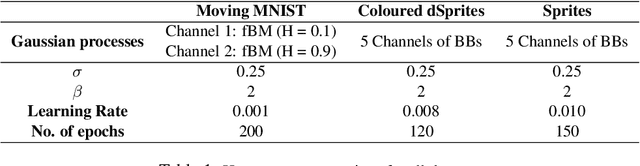
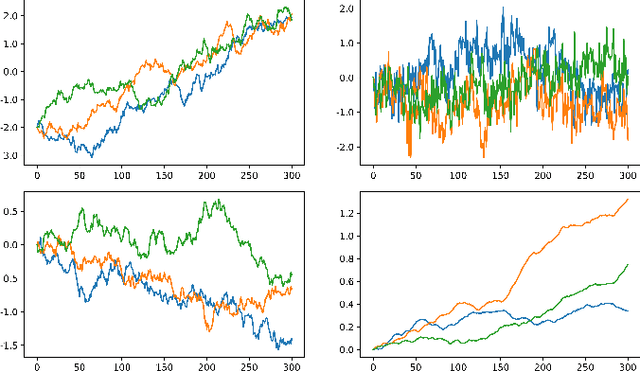
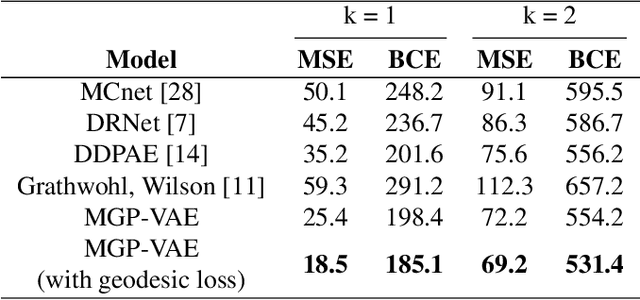
We introduce MGP-VAE, a variational autoencoder which uses Gaussian processes (GP) to model the latent space distribution. We employ MGP-VAE for the unsupervised learning of video sequences to obtain disentangled representations. Previous work in this area has mainly been confined to separating dynamic information from static content. We improve on previous results by establishing a framework by which multiple features, static or dynamic, can be disentangled. Specifically we use fractional Brownian motions (fBM) and Brownian bridges (BB) to enforce an inter-frame correlation structure in each independent channel. We show that varying this correlation structure enables one to capture different aspects of variation in the data. We demonstrate the quality of our disentangled representations on numerous experiments on three publicly available datasets, and also perform quantitative tests on a video prediction task. In addition, we introduce a novel geodesic loss function which takes into account the curvature of the data manifold to improve learning in the prediction task. Our experiments show quantitatively that the combination of our improved disentangled representations with the novel loss function enable MGP-VAE to outperform the state-of-the-art in video prediction.