 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning based Methods for Code Runtime Complexity Prediction
Nov 04, 2019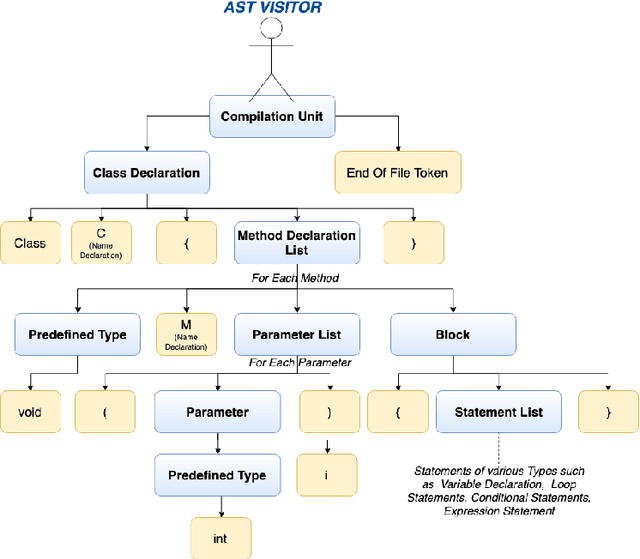
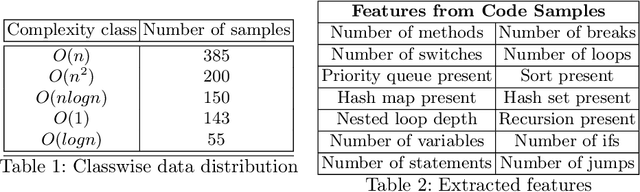
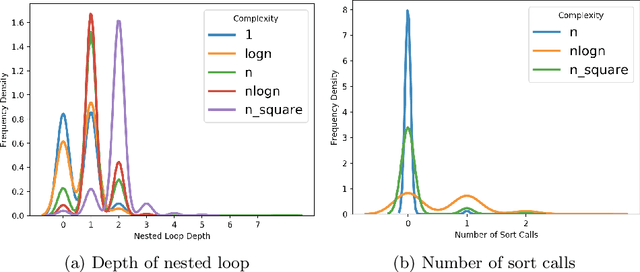
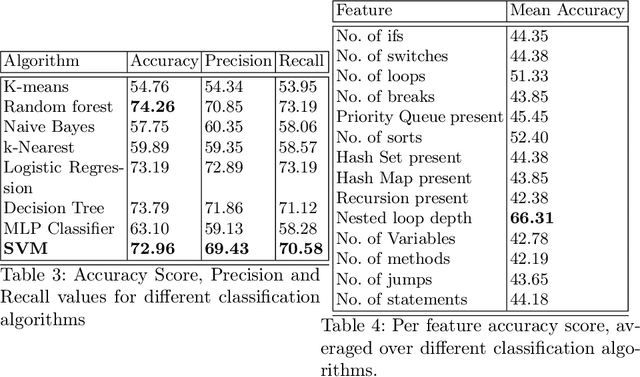
Predicting the runtime complexity of a programming code is an arduous task. In fact, even for humans, it requires a subtle analysis and comprehensive knowledge of algorithms to predict time complexity with high fidelity, given any code. As per Turing's Halting problem proof, estimating code complexity is mathematically impossible. Nevertheless, an approximate solution to such a task can help developers to get real-time feedback for the efficiency of their code. In this work, we model this problem as a machine learning task and check its feasibility with thorough analysis. Due to the lack of any open source dataset for this task, we propose our own annotated dataset CoRCoD: Code Runtime Complexity Dataset, extracted from online judges. We establish baselines using two different approaches: feature engineering and code embeddings, to achieve state of the art results and compare their performances. Such solutions can be widely useful in potential applications like automatically grading coding assignments, IDE-integrated tools for static code analysis, and others.
Intent-Aware Contextual Recommendation System
Nov 28, 2017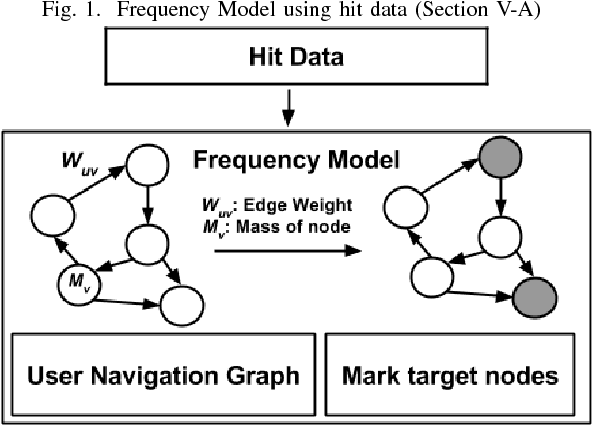
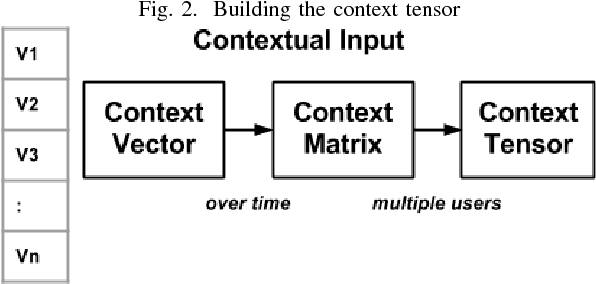

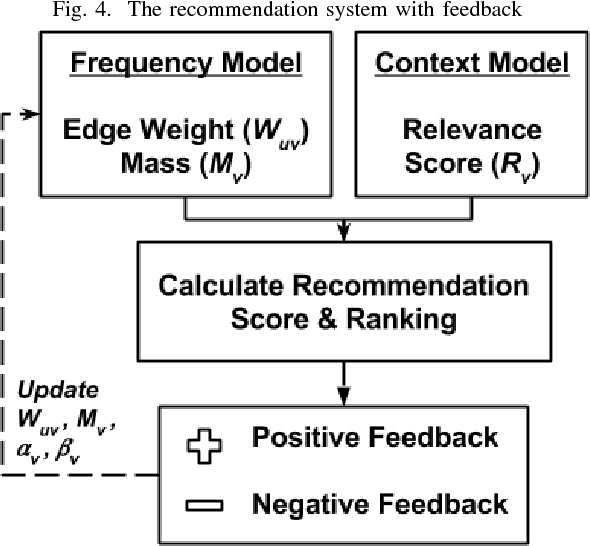
Recommender systems take inputs from user history, use an internal ranking algorithm to generate results and possibly optimize this ranking based on feedback. However, often the recommender system is unaware of the actual intent of the user and simply provides recommendations dynamically without properly understanding the thought process of the user. An intelligent recommender system is not only useful for the user but also for businesses which want to learn the tendencies of their users. Finding out tendencies or intents of a user is a difficult problem to solve. Keeping this in mind, we sought out to create an intelligent system which will keep track of the user's activity on a web-application as well as determine the intent of the user in each session. We devised a way to encode the user's activity through the sessions. Then, we have represented the information seen by the user in a high dimensional format which is reduced to lower dimensions using tensor factorization techniques. The aspect of intent awareness (or scoring) is dealt with at this stage. Finally, combining the user activity data with the contextual information gives the recommendation score. The final recommendations are then ranked using filtering and collaborative recommendation techniques to show the top-k recommendations to the user. A provision for feedback is also envisioned in the current system which informs the model to update the various weights in the recommender system. Our overall model aims to combine both frequency-based and context-based recommendation systems and quantify the intent of a user to provide better recommendations. We ran experiments on real-world timestamped user activity data, in the setting of recommending reports to the users of a business analytics tool and the results are better than the baselines. We also tuned certain aspects of our model to arrive at optimized results.