 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAMPLIFY:Attention-based Mixup for Performance Improvement and Label Smoothing in Transformer
Sep 22, 2023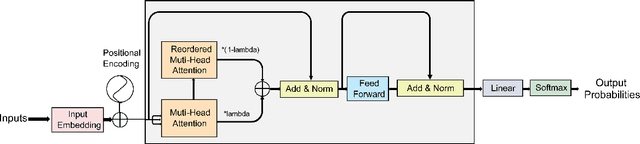
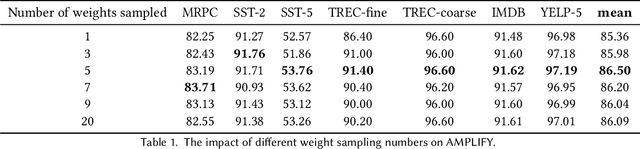
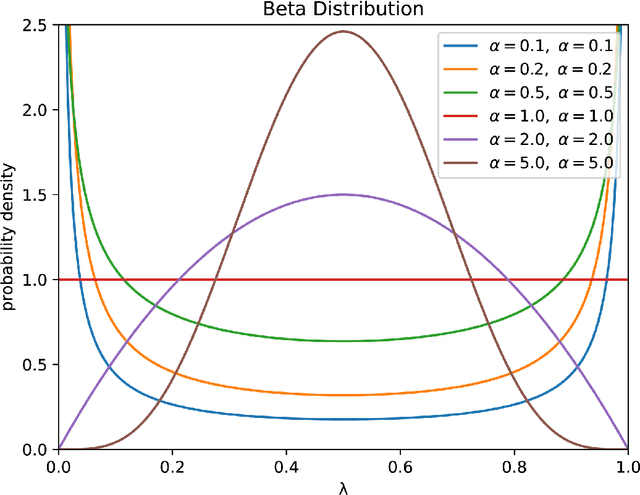
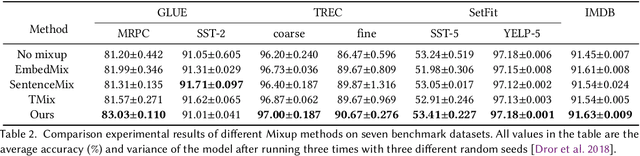
Mixup is an effective data augmentation method that generates new augmented samples by aggregating linear combinations of different original samples. However, if there are noises or aberrant features in the original samples, Mixup may propagate them to the augmented samples, leading to over-sensitivity of the model to these outliers . To solve this problem, this paper proposes a new Mixup method called AMPLIFY. This method uses the Attention mechanism of Transformer itself to reduce the influence of noises and aberrant values in the original samples on the prediction results, without increasing additional trainable parameters, and the computational cost is very low, thereby avoiding the problem of high resource consumption in common Mixup methods such as Sentence Mixup . The experimental results show that, under a smaller computational resource cost, AMPLIFY outperforms other Mixup methods in text classification tasks on 7 benchmark datasets, providing new ideas and new ways to further improve the performance of pre-trained models based on the Attention mechanism, such as BERT, ALBERT, RoBERTa, and GPT. Our code can be obtained at https://github.com/kiwi-lilo/AMPLIFY.