 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-time Speaker counting in a cocktail party scenario using Attention-guided Convolutional Neural Network
Paper and Code
Oct 30, 2021
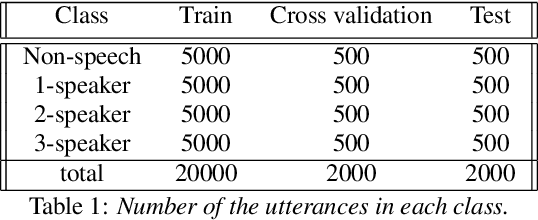

Most current speech technology systems are designed to operate well even in the presence of multiple active speakers. However, most solutions assume that the number of co-current speakers is known. Unfortunately, this information might not always be available in real-world applications. In this study, we propose a real-time, single-channel attention-guided Convolutional Neural Network (CNN) to estimate the number of active speakers in overlapping speech. The proposed system extracts higher-level information from the speech spectral content using a CNN model. Next, the attention mechanism summarizes the extracted information into a compact feature vector without losing critical information. Finally, the active speakers are classified using a fully connected network. Experiments on simulated overlapping speech using WSJ corpus show that the attention solution is shown to improve the performance by almost 3% absolute over conventional temporal average pooling. The proposed Attention-guided CNN achieves 76.15% for both Weighted Accuracy and average Recall, and 75.80% Precision on speech segments as short as 20 frames (i.e., 200 ms). All the classification metrics exceed 92% for the attention-guided model in offline scenarios where the input signal is more than 100 frames long (i.e., 1s).