 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeaker conditioning of acoustic models using affine transformation for multi-speaker speech recognition
Oct 30, 2021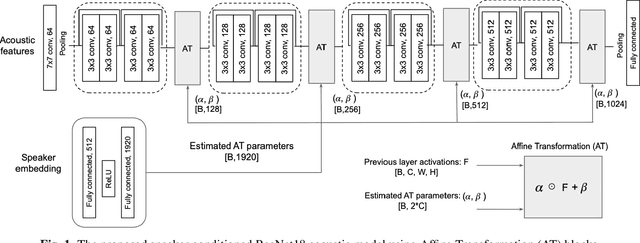

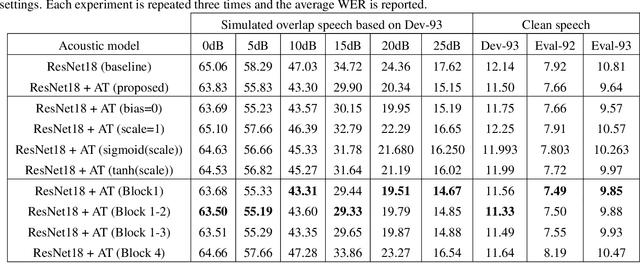
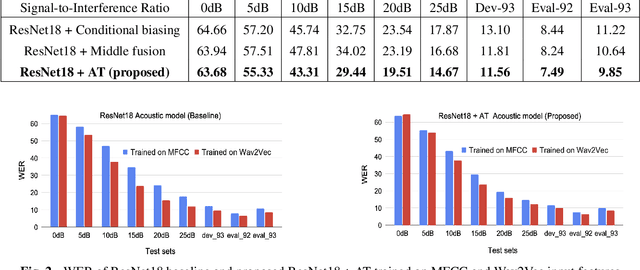
This study addresses the problem of single-channel Automatic Speech Recognition of a target speaker within an overlap speech scenario. In the proposed method, the hidden representations in the acoustic model are modulated by speaker auxiliary information to recognize only the desired speaker. Affine transformation layers are inserted into the acoustic model network to integrate speaker information with the acoustic features. The speaker conditioning process allows the acoustic model to perform computation in the context of target-speaker auxiliary information. The proposed speaker conditioning method is a general approach and can be applied to any acoustic model architecture. Here, we employ speaker conditioning on a ResNet acoustic model. Experiments on the WSJ corpus show that the proposed speaker conditioning method is an effective solution to fuse speaker auxiliary information with acoustic features for multi-speaker speech recognition, achieving +9% and +20% relative WER reduction for clean and overlap speech scenarios, respectively, compared to the original ResNet acoustic model baseline.