 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConformation Generation using Transformer Flows
Nov 16, 2024

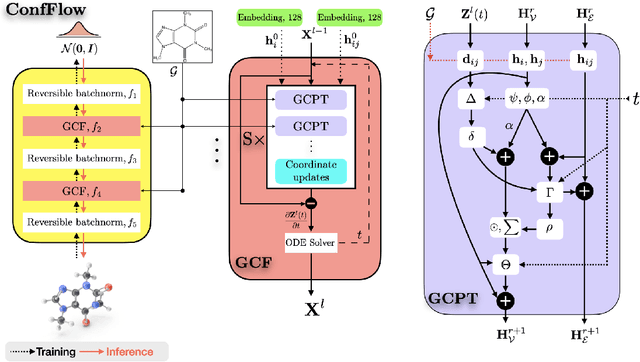

Estimating three-dimensional conformations of a molecular graph allows insight into the molecule's biological and chemical functions. Fast generation of valid conformations is thus central to molecular modeling. Recent advances in graph-based deep networks have accelerated conformation generation from hours to seconds. However, current network architectures do not scale well to large molecules. Here we present ConfFlow, a flow-based model for conformation generation based on transformer networks. In contrast with existing approaches, ConfFlow directly samples in the coordinate space without enforcing any explicit physical constraints. The generative procedure is highly interpretable and is akin to force field updates in molecular dynamics simulation. When applied to the generation of large molecule conformations, ConfFlow improve accuracy by up to $40\%$ relative to state-of-the-art learning-based methods. The source code is made available at https://github.com/IntelLabs/ConfFlow.
Auto-decoding Graphs
Jun 04, 2020



We present an approach to synthesizing new graph structures from empirically specified distributions. The generative model is an auto-decoder that learns to synthesize graphs from latent codes. The graph synthesis model is learned jointly with an empirical distribution over the latent codes. Graphs are synthesized using self-attention modules that are trained to identify likely connectivity patterns. Graph-based normalizing flows are used to sample latent codes from the distribution learned by the auto-decoder. The resulting model combines accuracy and scalability. On benchmark datasets of large graphs, the presented model outperforms the state of the art by a factor of 1.5 in mean accuracy and average rank across at least three different graph statistics, with a 2x speedup during inference.
Deep Continuous Clustering
Mar 05, 2018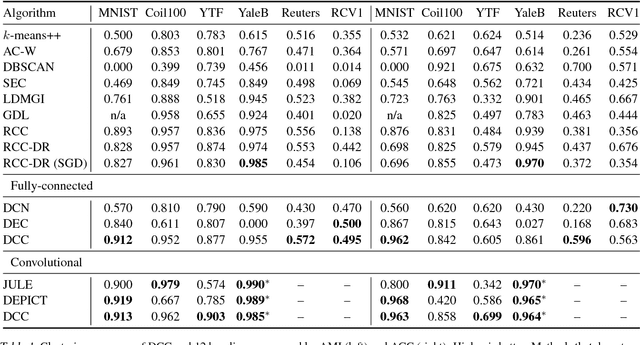



Clustering high-dimensional datasets is hard because interpoint distances become less informative in high-dimensional spaces. We present a clustering algorithm that performs nonlinear dimensionality reduction and clustering jointly. The data is embedded into a lower-dimensional space by a deep autoencoder. The autoencoder is optimized as part of the clustering process. The resulting network produces clustered data. The presented approach does not rely on prior knowledge of the number of ground-truth clusters. Joint nonlinear dimensionality reduction and clustering are formulated as optimization of a global continuous objective. We thus avoid discrete reconfigurations of the objective that characterize prior clustering algorithms. Experiments on datasets from multiple domains demonstrate that the presented algorithm outperforms state-of-the-art clustering schemes, including recent methods that use deep networks.