 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgents that Listen: High-Throughput Reinforcement Learning with Multiple Sensory Systems
Paper and Code
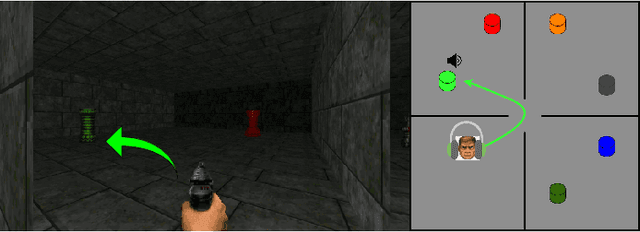
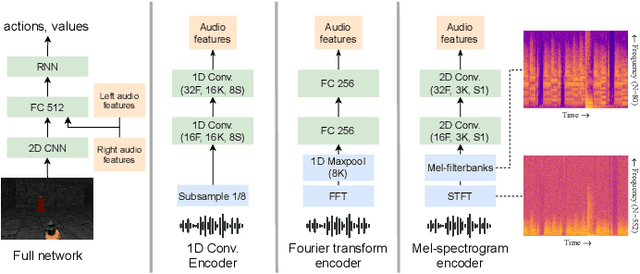

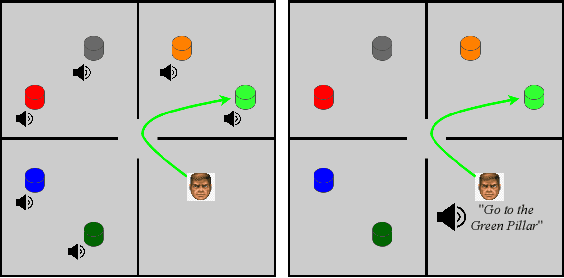
Humans and other intelligent animals evolved highly sophisticated perception systems that combine multiple sensory modalities. On the other hand, state-of-the-art artificial agents rely mostly on visual inputs or structured low-dimensional observations provided by instrumented environments. Learning to act based on combined visual and auditory inputs is still a new topic of research that has not been explored beyond simple scenarios. To facilitate progress in this area we introduce a new version of VizDoom simulator to create a highly efficient learning environment that provides raw audio observations. We study the performance of different model architectures in a series of tasks that require the agent to recognize sounds and execute instructions given in natural language. Finally, we train our agent to play the full game of Doom and find that it can consistently defeat a traditional vision-based adversary. We are currently in the process of merging the augmented simulator with the main ViZDoom code repository. Video demonstrations and experiment code can be found at https://sites.google.com/view/sound-rl.