 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralized Clustering by Learning to Optimize Expected Normalized Cuts
Oct 16, 2019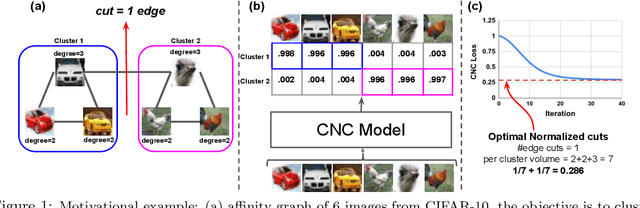
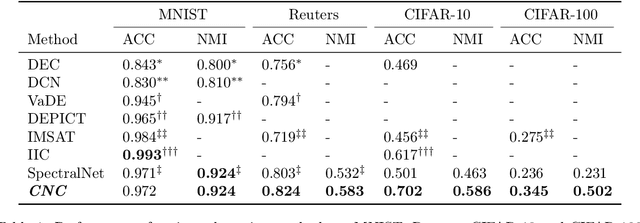

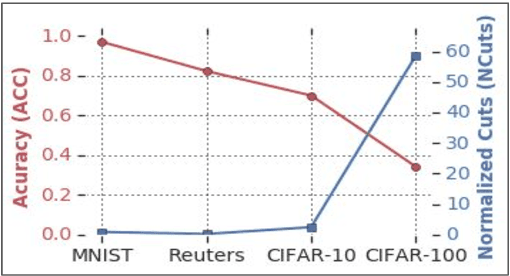
We introduce a novel end-to-end approach for learning to cluster in the absence of labeled examples. Our clustering objective is based on optimizing normalized cuts, a criterion which measures both intra-cluster similarity as well as inter-cluster dissimilarity. We define a differentiable loss function equivalent to the expected normalized cuts. Unlike much of the work in unsupervised deep learning, our trained model directly outputs final cluster assignments, rather than embeddings that need further processing to be usable. Our approach generalizes to unseen datasets across a wide variety of domains, including text, and image. Specifically, we achieve state-of-the-art results on popular unsupervised clustering benchmarks (e.g., MNIST, Reuters, CIFAR-10, and CIFAR-100), outperforming the strongest baselines by up to 10.9%. Our generalization results are superior (by up to 21.9%) to the recent top-performing clustering approach with the ability to generalize.
Reinforcement Learning Driven Heuristic Optimization
Jun 16, 2019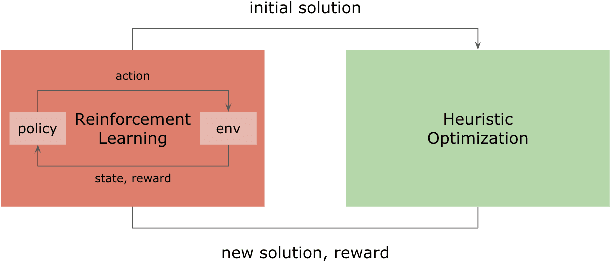


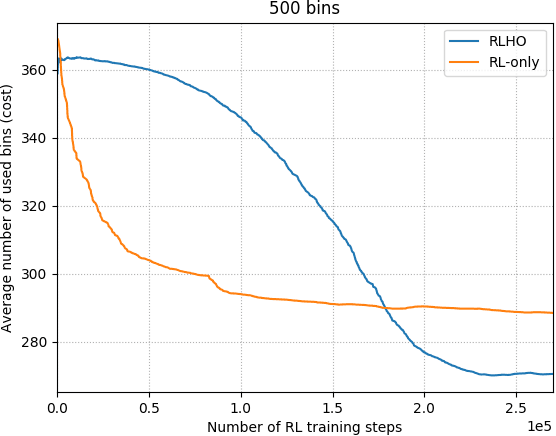
Heuristic algorithms such as simulated annealing, Concorde, and METIS are effective and widely used approaches to find solutions to combinatorial optimization problems. However, they are limited by the high sample complexity required to reach a reasonable solution from a cold-start. In this paper, we introduce a novel framework to generate better initial solutions for heuristic algorithms using reinforcement learning (RL), named RLHO. We augment the ability of heuristic algorithms to greedily improve upon an existing initial solution generated by RL, and demonstrate novel results where RL is able to leverage the performance of heuristics as a learning signal to generate better initialization. We apply this framework to Proximal Policy Optimization (PPO) and Simulated Annealing (SA). We conduct a series of experiments on the well-known NP-complete bin packing problem, and show that the RLHO method outperforms our baselines. We show that on the bin packing problem, RL can learn to help heuristics perform even better, allowing us to combine the best parts of both approaches.
GAP: Generalizable Approximate Graph Partitioning Framework
Mar 02, 2019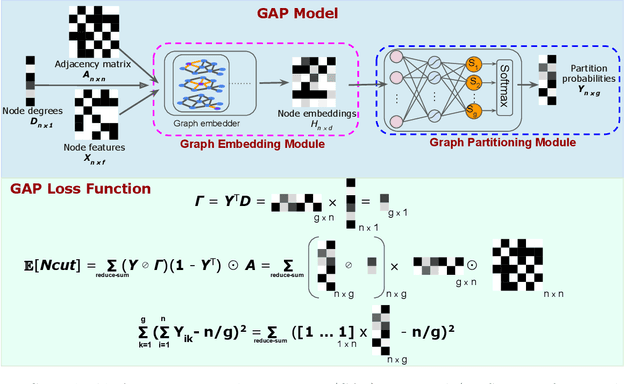
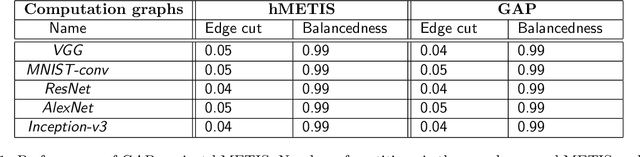

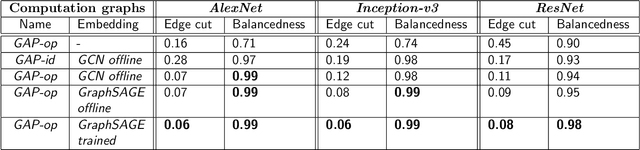
Graph partitioning is the problem of dividing the nodes of a graph into balanced partitions while minimizing the edge cut across the partitions. Due to its combinatorial nature, many approximate solutions have been developed, including variants of multi-level methods and spectral clustering. We propose GAP, a Generalizable Approximate Partitioning framework that takes a deep learning approach to graph partitioning. We define a differentiable loss function that represents the partitioning objective and use backpropagation to optimize the network parameters. Unlike baselines that redo the optimization per graph, GAP is capable of generalization, allowing us to train models that produce performant partitions at inference time, even on unseen graphs. Furthermore, because we learn the representation of the graph while jointly optimizing for the partitioning loss function, GAP can be easily tuned for a variety of graph structures. We evaluate the performance of GAP on graphs of varying sizes and structures, including graphs of widely used machine learning models (e.g., ResNet, VGG, and Inception-V3), scale-free graphs, and random graphs. We show that GAP achieves competitive partitions while being up to 100 times faster than the baseline and generalizes to unseen graphs.