 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGAP: Generalizable Approximate Graph Partitioning Framework
Paper and Code
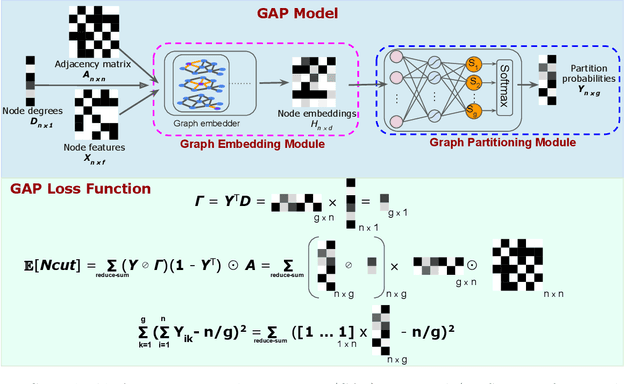
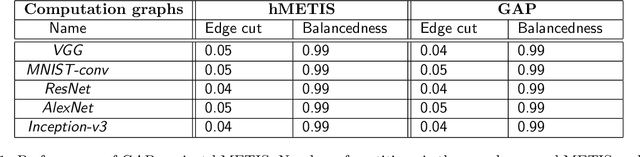

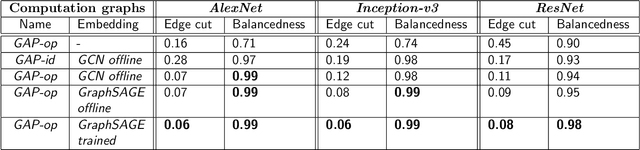
Graph partitioning is the problem of dividing the nodes of a graph into balanced partitions while minimizing the edge cut across the partitions. Due to its combinatorial nature, many approximate solutions have been developed, including variants of multi-level methods and spectral clustering. We propose GAP, a Generalizable Approximate Partitioning framework that takes a deep learning approach to graph partitioning. We define a differentiable loss function that represents the partitioning objective and use backpropagation to optimize the network parameters. Unlike baselines that redo the optimization per graph, GAP is capable of generalization, allowing us to train models that produce performant partitions at inference time, even on unseen graphs. Furthermore, because we learn the representation of the graph while jointly optimizing for the partitioning loss function, GAP can be easily tuned for a variety of graph structures. We evaluate the performance of GAP on graphs of varying sizes and structures, including graphs of widely used machine learning models (e.g., ResNet, VGG, and Inception-V3), scale-free graphs, and random graphs. We show that GAP achieves competitive partitions while being up to 100 times faster than the baseline and generalizes to unseen graphs.