 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Clinical Concepts for Predicting Risk of Progression to Severe COVID-19
Paper and Code
Aug 28, 2022
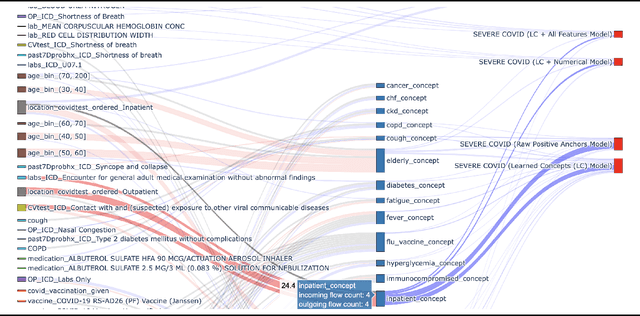

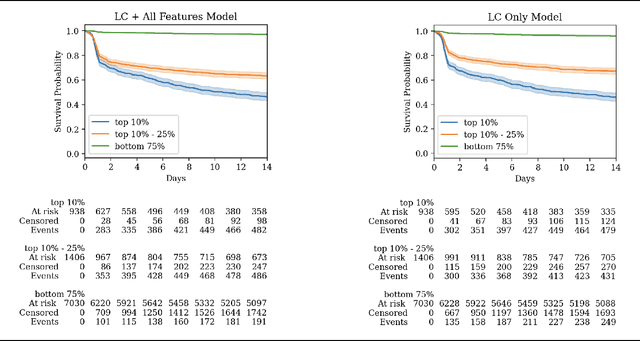
With COVID-19 now pervasive, identification of high-risk individuals is crucial. Using data from a major healthcare provider in Southwestern Pennsylvania, we develop survival models predicting severe COVID-19 progression. In this endeavor, we face a tradeoff between more accurate models relying on many features and less accurate models relying on a few features aligned with clinician intuition. Complicating matters, many EHR features tend to be under-coded, degrading the accuracy of smaller models. In this study, we develop two sets of high-performance risk scores: (i) an unconstrained model built from all available features; and (ii) a pipeline that learns a small set of clinical concepts before training a risk predictor. Learned concepts boost performance over the corresponding features (C-index 0.858 vs. 0.844) and demonstrate improvements over (i) when evaluated out-of-sample (subsequent time periods). Our models outperform previous works (C-index 0.844-0.872 vs. 0.598-0.810).