 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Route with Confidence Tokens
Oct 17, 2024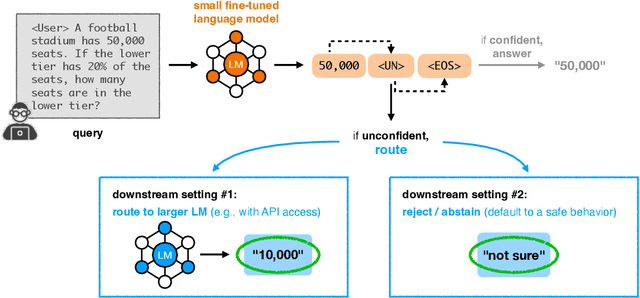

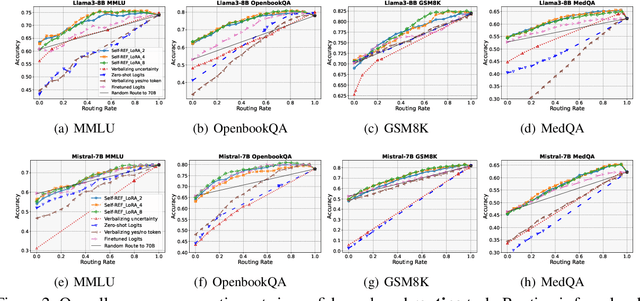
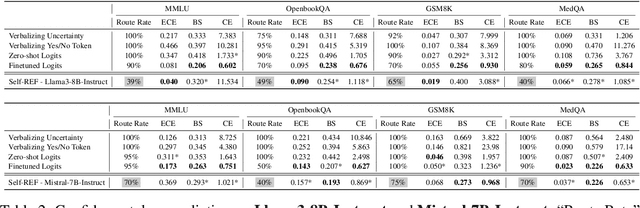
Large language models (LLMs) have demonstrated impressive performance on several tasks and are increasingly deployed in real-world applications. However, especially in high-stakes settings, it becomes vital to know when the output of an LLM may be unreliable. Depending on whether an answer is trustworthy, a system can then choose to route the question to another expert, or otherwise fall back on a safe default behavior. In this work, we study the extent to which LLMs can reliably indicate confidence in their answers, and how this notion of confidence can translate into downstream accuracy gains. We propose Self-REF, a lightweight training strategy to teach LLMs to express confidence in whether their answers are correct in a reliable manner. Self-REF introduces confidence tokens into the LLM, from which a confidence score can be extracted. Compared to conventional approaches such as verbalizing confidence and examining token probabilities, we demonstrate empirically that confidence tokens show significant improvements in downstream routing and rejection learning tasks.
Sentiment Analysis by Joint Learning of Word Embeddings and Classifier
Aug 14, 2017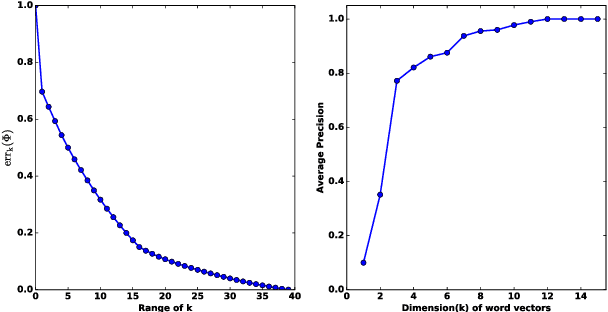
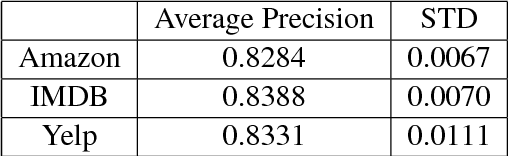
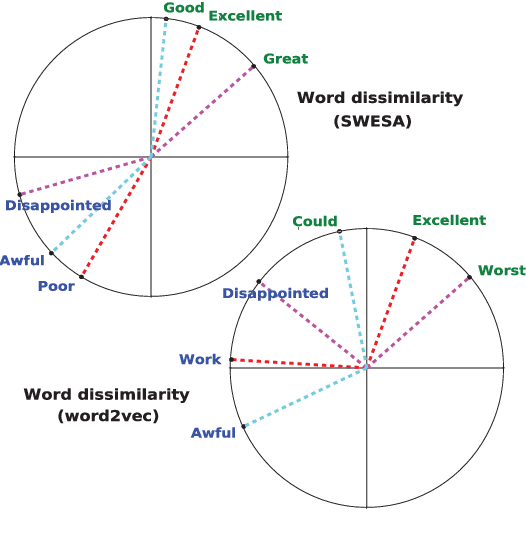
Word embeddings are representations of individual words of a text document in a vector space and they are often use- ful for performing natural language pro- cessing tasks. Current state of the art al- gorithms for learning word embeddings learn vector representations from large corpora of text documents in an unsu- pervised fashion. This paper introduces SWESA (Supervised Word Embeddings for Sentiment Analysis), an algorithm for sentiment analysis via word embeddings. SWESA leverages document label infor- mation to learn vector representations of words from a modest corpus of text doc- uments by solving an optimization prob- lem that minimizes a cost function with respect to both word embeddings as well as classification accuracy. Analysis re- veals that SWESA provides an efficient way of estimating the dimension of the word embeddings that are to be learned. Experiments on several real world data sets show that SWESA has superior per- formance when compared to previously suggested approaches to word embeddings and sentiment analysis tasks.