 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Zero-Knowledge Task Planning via a Language-based Approach
Jan 06, 2026In this work, we introduce and formalize the Zero-Knowledge Task Planning (ZKTP) problem, i.e., formulating a sequence of actions to achieve some goal without task-specific knowledge. Additionally, we present a first investigation and approach for ZKTP that leverages a large language model (LLM) to decompose natural language instructions into subtasks and generate behavior trees (BTs) for execution. If errors arise during task execution, the approach also uses an LLM to adjust the BTs on-the-fly in a refinement loop. Experimental validation in the AI2-THOR simulator demonstrate our approach's effectiveness in improving overall task performance compared to alternative approaches that leverage task-specific knowledge. Our work demonstrates the potential of LLMs to effectively address several aspects of the ZKTP problem, providing a robust framework for automated behavior generation with no task-specific setup.
A Robot-Assisted Approach to Small Talk Training for Adults with ASD
May 29, 2025



From dating to job interviews, making new friends or simply chatting with the cashier at checkout, engaging in small talk is a vital, everyday social skill. For adults with Autism Spectrum Disorder (ASD), small talk can be particularly challenging, yet it is essential for social integration, building relationships, and accessing professional opportunities. In this study, we present our development and evaluation of an in-home autonomous robot system that allows users to practice small talk. Results from the week-long study show that adults with ASD enjoyed the training, made notable progress in initiating conversations and improving eye contact, and viewed the system as a valuable tool for enhancing their conversational skills.
Effects of Robot Competency and Motion Legibility on Human Correction Feedback
Jan 07, 2025



As robot deployments become more commonplace, people are likely to take on the role of supervising robots (i.e., correcting their mistakes) rather than directly teaching them. Prior works on Learning from Corrections (LfC) have relied on three key assumptions to interpret human feedback: (1) people correct the robot only when there is significant task objective divergence; (2) people can accurately predict if a correction is necessary; and (3) people trade off precision and physical effort when giving corrections. In this work, we study how two key factors (robot competency and motion legibility) affect how people provide correction feedback and their implications on these existing assumptions. We conduct a user study ($N=60$) under an LfC setting where participants supervise and correct a robot performing pick-and-place tasks. We find that people are more sensitive to suboptimal behavior by a highly competent robot compared to an incompetent robot when the motions are legible ($p=0.0015$) and predictable ($p=0.0055$). In addition, people also tend to withhold necessary corrections ($p < 0.0001$) when supervising an incompetent robot and are more prone to offering unnecessary ones ($p = 0.0171$) when supervising a highly competent robot. We also find that physical effort positively correlates with correction precision, providing empirical evidence to support this common assumption. We also find that this correlation is significantly weaker for an incompetent robot with legible motions than an incompetent robot with predictable motions ($p = 0.0075$). Our findings offer insights for accounting for competency and legibility when designing robot interaction behaviors and learning task objectives from corrections.
Gaze Behavior During a Long-Term, In-Home, Social Robot Intervention for Children with ASD
Jan 05, 2025



Atypical gaze behavior is a diagnostic hallmark of Autism Spectrum Disorder (ASD), playing a substantial role in the social and communicative challenges that individuals with ASD face. This study explores the impacts of a month-long, in-home intervention designed to promote triadic interactions between a social robot, a child with ASD, and their caregiver. Our results indicate that the intervention successfully promoted appropriate gaze behavior, encouraging children with ASD to follow the robot's gaze, resulting in more frequent and prolonged instances of spontaneous eye contact and joint attention with their caregivers. Additionally, we observed specific timelines for behavioral variability and novelty effects among users. Furthermore, diagnostic measures for ASD emerged as strong predictors of gaze patterns for both caregivers and children. These results deepen our understanding of ASD gaze patterns and highlight the potential for clinical relevance of robot-assisted interventions.
More than Chit-Chat: Developing Robots for Small-Talk Interactions
Dec 23, 2024



Beyond mere formality, small talk plays a pivotal role in social dynamics, serving as a verbal handshake for building rapport and understanding. For conversational AI and social robots, the ability to engage in small talk enhances their perceived sociability, leading to more comfortable and natural user interactions. In this study, we evaluate the capacity of current Large Language Models (LLMs) to drive the small talk of a social robot and identify key areas for improvement. We introduce a novel method that autonomously generates feedback and ensures LLM-generated responses align with small talk conventions. Through several evaluations -- involving chatbot interactions and human-robot interactions -- we demonstrate the system's effectiveness in guiding LLM-generated responses toward realistic, human-like, and natural small-talk exchanges.
A Grounded Observer Framework for Establishing Guardrails for Foundation Models in Socially Sensitive Domains
Dec 23, 2024



As foundation models increasingly permeate sensitive domains such as healthcare, finance, and mental health, ensuring their behavior meets desired outcomes and social expectations becomes critical. Given the complexities of these high-dimensional models, traditional techniques for constraining agent behavior, which typically rely on low-dimensional, discrete state and action spaces, cannot be directly applied. Drawing inspiration from robotic action selection techniques, we propose the grounded observer framework for constraining foundation model behavior that offers both behavioral guarantees and real-time variability. This method leverages real-time assessment of low-level behavioral characteristics to dynamically adjust model actions and provide contextual feedback. To demonstrate this, we develop a system capable of sustaining contextually appropriate, casual conversations ("small talk"), which we then apply to a robot for novel, unscripted interactions with humans. Finally, we discuss potential applications of the framework for other social contexts and areas for further research.
Sequential Discrete Action Selection via Blocking Conditions and Resolutions
Sep 12, 2024



In this work, we introduce a strategy that frames the sequential action selection problem for robots in terms of resolving \textit{blocking conditions}, i.e., situations that impede progress on an action en route to a goal. This strategy allows a robot to make one-at-a-time decisions that take in pertinent contextual information and swiftly adapt and react to current situations. We present a first instantiation of this strategy that combines a state-transition graph and a zero-shot Large Language Model (LLM). The state-transition graph tracks which previously attempted actions are currently blocked and which candidate actions may resolve existing blocking conditions. This information from the state-transition graph is used to automatically generate a prompt for the LLM, which then uses the given context and set of possible actions to select a single action to try next. This selection process is iterative, with each chosen and executed action further refining the state-transition graph, continuing until the agent either fulfills the goal or encounters a termination condition. We demonstrate the effectiveness of our approach by comparing it to various LLM and traditional task-planning methods in a testbed of simulation experiments. We discuss the implications of our work based on our results.
REACT: Two Datasets for Analyzing Both Human Reactions and Evaluative Feedback to Robots Over Time
Jan 31, 2024


Recent work in Human-Robot Interaction (HRI) has shown that robots can leverage implicit communicative signals from users to understand how they are being perceived during interactions. For example, these signals can be gaze patterns, facial expressions, or body motions that reflect internal human states. To facilitate future research in this direction, we contribute the REACT database, a collection of two datasets of human-robot interactions that display users' natural reactions to robots during a collaborative game and a photography scenario. Further, we analyze the datasets to show that interaction history is an important factor that can influence human reactions to robots. As a result, we believe that future models for interpreting implicit feedback in HRI should explicitly account for this history. REACT opens up doors to this possibility in the future.
That's Mine! Learning Ownership Relations and Norms for Robots
Jan 10, 2019
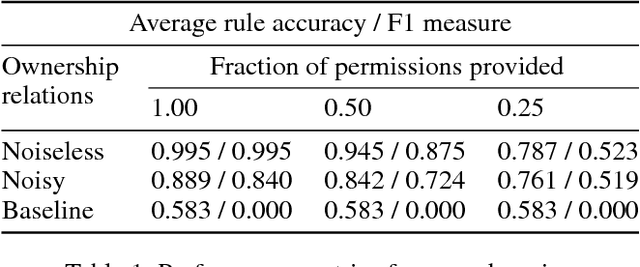
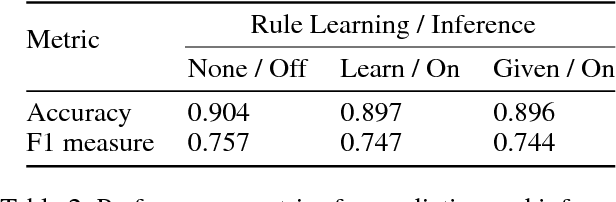

The ability for autonomous agents to learn and conform to human norms is crucial for their safety and effectiveness in social environments. While recent work has led to frameworks for the representation and inference of simple social rules, research into norm learning remains at an exploratory stage. Here, we present a robotic system capable of representing, learning, and inferring ownership relations and norms. Ownership is represented as a graph of probabilistic relations between objects and their owners, along with a database of predicate-based norms that constrain the actions permissible on owned objects. To learn these norms and relations, our system integrates (i) a novel incremental norm learning algorithm capable of both one-shot learning and induction from specific examples, (ii) Bayesian inference of ownership relations in response to apparent rule violations, and (iii) percept-based prediction of an object's likely owners. Through a series of simulated and real-world experiments, we demonstrate the competence and flexibility of the system in performing object manipulation tasks that require a variety of norms to be followed, laying the groundwork for future research into the acquisition and application of social norms.
How to be Helpful? Implementing Supportive Behaviors for Human-Robot Collaboration
Oct 30, 2017



The field of Human-Robot Collaboration (HRC) has seen a considerable amount of progress in the recent years. Although genuinely collaborative platforms are far from being deployed in real-world scenarios, advances in control and perception algorithms have progressively popularized robots in manufacturing settings, where they work side by side with human peers to achieve shared tasks. Unfortunately, little progress has been made toward the development of systems that are proactive in their collaboration, and autonomously take care of some of the chores that compose most of the collaboration tasks. In this work, we present a collaborative system capable of assisting the human partner with a variety of supportive behaviors in spite of its limited perceptual and manipulation capabilities and incomplete model of the task. Our framework leverages information from a high-level, hierarchical model of the task. The model, that is shared between the human and robot, enables transparent synchronization between the peers and understanding of each other's plan. More precisely, we derive a partially observable Markov model from the high-level task representation. We then use an online solver to compute a robot policy, that is robust to unexpected observations such as inaccuracies of perception, failures in object manipulations, as well as discovers hidden user preferences. We demonstrate that the system is capable of robustly providing support to the human in a furniture construction task.