 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffects of Robot Competency and Motion Legibility on Human Correction Feedback
Jan 07, 2025



As robot deployments become more commonplace, people are likely to take on the role of supervising robots (i.e., correcting their mistakes) rather than directly teaching them. Prior works on Learning from Corrections (LfC) have relied on three key assumptions to interpret human feedback: (1) people correct the robot only when there is significant task objective divergence; (2) people can accurately predict if a correction is necessary; and (3) people trade off precision and physical effort when giving corrections. In this work, we study how two key factors (robot competency and motion legibility) affect how people provide correction feedback and their implications on these existing assumptions. We conduct a user study ($N=60$) under an LfC setting where participants supervise and correct a robot performing pick-and-place tasks. We find that people are more sensitive to suboptimal behavior by a highly competent robot compared to an incompetent robot when the motions are legible ($p=0.0015$) and predictable ($p=0.0055$). In addition, people also tend to withhold necessary corrections ($p < 0.0001$) when supervising an incompetent robot and are more prone to offering unnecessary ones ($p = 0.0171$) when supervising a highly competent robot. We also find that physical effort positively correlates with correction precision, providing empirical evidence to support this common assumption. We also find that this correlation is significantly weaker for an incompetent robot with legible motions than an incompetent robot with predictable motions ($p = 0.0075$). Our findings offer insights for accounting for competency and legibility when designing robot interaction behaviors and learning task objectives from corrections.
Active Probing and Influencing Human Behaviors Via Autonomous Agents
Apr 24, 2023

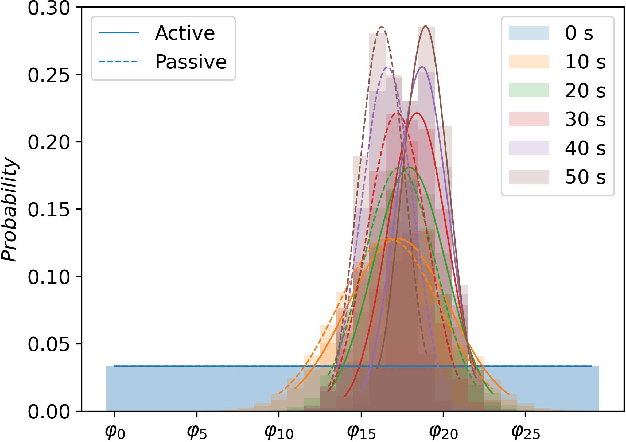

Autonomous agents (robots) face tremendous challenges while interacting with heterogeneous human agents in close proximity. One of these challenges is that the autonomous agent does not have an accurate model tailored to the specific human that the autonomous agent is interacting with, which could sometimes result in inefficient human-robot interaction and suboptimal system dynamics. Developing an online method to enable the autonomous agent to learn information about the human model is therefore an ongoing research goal. Existing approaches position the robot as a passive learner in the environment to observe the physical states and the associated human response. This passive design, however, only allows the robot to obtain information that the human chooses to exhibit, which sometimes doesn't capture the human's full intention. In this work, we present an online optimization-based probing procedure for the autonomous agent to clarify its belief about the human model in an active manner. By optimizing an information radius, the autonomous agent chooses the action that most challenges its current conviction. This procedure allows the autonomous agent to actively probe the human agents to reveal information that's previously unavailable to the autonomous agent. With this gathered information, the autonomous agent can interactively influence the human agent for some designated objectives. Our main contributions include a coherent theoretical framework that unifies the probing and influence procedures and two case studies in autonomous driving that show how active probing can help to create better participant experience during influence, like higher efficiency or less perturbations.