 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWildfire Forecasting with Satellite Images and Deep Generative Model
Aug 22, 2022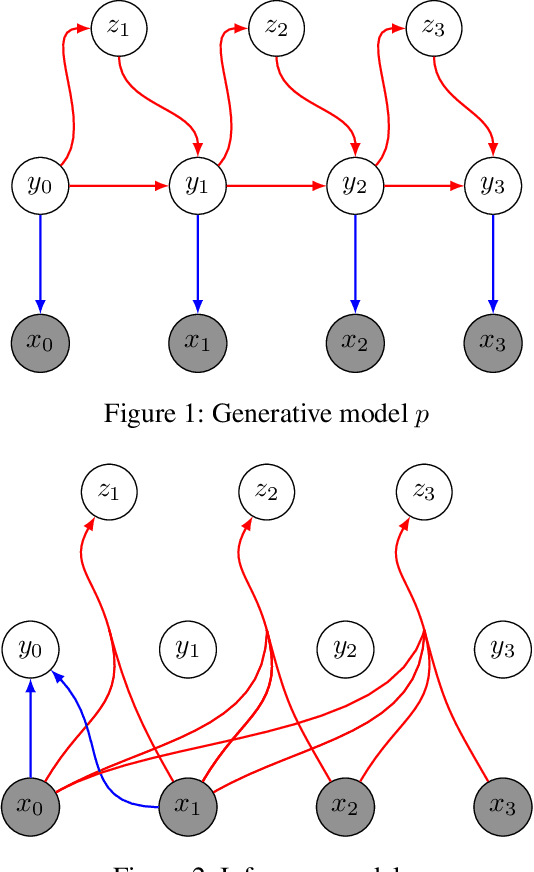

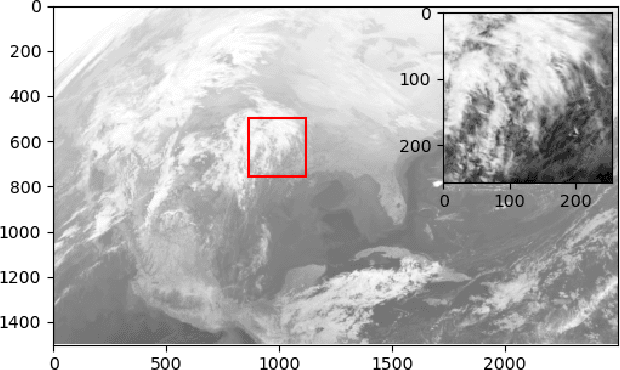
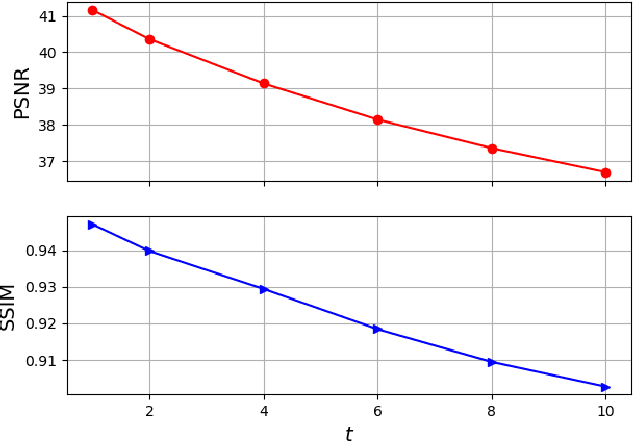
Wildfire forecasting has been one of the most critical tasks that humanities want to thrive. It plays a vital role in protecting human life. Wildfire prediction, on the other hand, is difficult because of its stochastic and chaotic properties. We tackled the problem by interpreting a series of wildfire images as a video and used it to anticipate how the fire would behave in the future. However, creating video prediction models that account for the inherent uncertainty of the future is challenging. The bulk of published attempts is based on stochastic image-autoregressive recurrent networks, which raises various performance and application difficulties, such as computational cost and limited efficiency on massive datasets. Another possibility is to use entirely latent temporal models that combine frame synthesis and temporal dynamics. However, due to design and training issues, no such model for stochastic video prediction has yet been proposed in the literature. This paper addresses these issues by introducing a novel stochastic temporal model whose dynamics are driven in a latent space. It naturally predicts video dynamics by allowing our lighter, more interpretable latent model to beat previous state-of-the-art approaches on the GOES-16 dataset. Results will be compared towards various benchmarking models.