 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscrete Facial Encoding: : A Framework for Data-driven Facial Display Discovery
Oct 02, 2025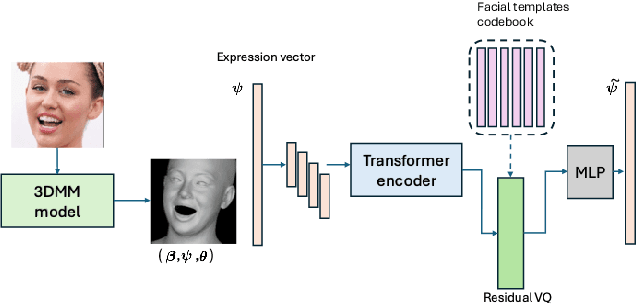
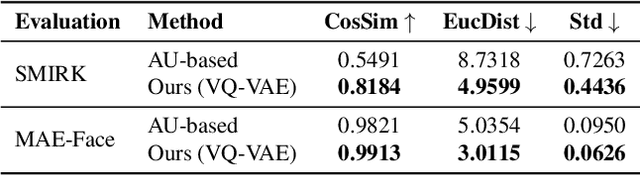

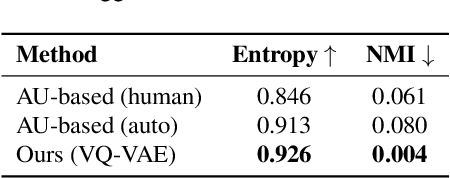
Facial expression analysis is central to understanding human behavior, yet existing coding systems such as the Facial Action Coding System (FACS) are constrained by limited coverage and costly manual annotation. In this work, we introduce Discrete Facial Encoding (DFE), an unsupervised, data-driven alternative of compact and interpretable dictionary of facial expressions from 3D mesh sequences learned through a Residual Vector Quantized Variational Autoencoder (RVQ-VAE). Our approach first extracts identity-invariant expression features from images using a 3D Morphable Model (3DMM), effectively disentangling factors such as head pose and facial geometry. We then encode these features using an RVQ-VAE, producing a sequence of discrete tokens from a shared codebook, where each token captures a specific, reusable facial deformation pattern that contributes to the overall expression. Through extensive experiments, we demonstrate that Discrete Facial Encoding captures more precise facial behaviors than FACS and other facial encoding alternatives. We evaluate the utility of our representation across three high-level psychological tasks: stress detection, personality prediction, and depression detection. Using a simple Bag-of-Words model built on top of the learned tokens, our system consistently outperforms both FACS-based pipelines and strong image and video representation learning models such as Masked Autoencoders. Further analysis reveals that our representation covers a wider variety of facial displays, highlighting its potential as a scalable and effective alternative to FACS for psychological and affective computing applications.
PromptGAR: Flexible Promptive Group Activity Recognition
Mar 11, 2025



We present PromptGAR, a novel framework that addresses the limitations of current Group Activity Recognition (GAR) approaches by leveraging multi-modal prompts to achieve both input flexibility and high recognition accuracy. The existing approaches suffer from limited real-world applicability due to their reliance on full prompt annotations, the lack of long-term actor consistency, and under-exploration of multi-group scenarios. To bridge the gap, we proposed PromptGAR, which is the first GAR model to provide input flexibility across prompts, frames, and instances without the need for retraining. Specifically, we unify bounding boxes, skeletal keypoints, and areas as point prompts and employ a recognition decoder for cross-updating class and prompt tokens. To ensure long-term consistency for extended activity durations, we also introduce a relative instance attention mechanism that directly encodes instance IDs. Finally, PromptGAR explores the use of area prompts to enable the selective recognition of the particular group activity within videos that contain multiple concurrent groups. Comprehensive evaluations demonstrate that PromptGAR achieves competitive performances both on full prompts and diverse prompt inputs, establishing its effectiveness on input flexibility and generalization ability for real-world applications.