 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFIS-DiT: Breaking the Few-Step Video Inference Barrier via Training-Free Frame Interleaved Sparsity
May 12, 2026While the overall inference latency of Video Diffusion Transformers (DiTs) can be substantially reduced through model distillation, per-step inference latency remains a critical bottleneck. Existing acceleration paradigms primarily exploit redundancy across the denoising trajectory; however, we identify a limitation where these step-wise strategies encounter diminishing returns in few-step regimes. In such scenarios, the scarcity of temporal states prevents effective feature reuse or predictive modeling, creating a formidable barrier to further acceleration. To overcome this, we propose Frame Interleaved Sparsity DiT (FIS-DiT), a training-free and operator-agnostic framework that shifts the optimization focus from the temporal trajectory to the latent frame dimension. Our approach is motivated by an intrinsic duality within this dimension: the existence of frame-wise sparsity that permits reduced computation, coupled with a structural consistency where each frame position remains equally vital to the global spatiotemporal context. Leveraging this insight, we implement Frame Interleaved Sparsity (FIS) as an execution strategy that manipulates frame subsets across the model hierarchy, refreshing all latent positions without requiring full-scale block computation. Empirical evaluations on Wan 2.2 and HunyuanVideo 1.5 demonstrate that FIS-DiT consistently achieves 2.11--2.41$\times$ speedup with negligible degradation across VBench-Q and CLIP metrics, providing a scalable and robust pathway toward real-time high-definition video generation.
Chain-of-Models Pre-Training: Rethinking Training Acceleration of Vision Foundation Models
Apr 14, 2026In this paper, we present Chain-of-Models Pre-Training (CoM-PT), a novel performance-lossless training acceleration method for vision foundation models (VFMs). This approach fundamentally differs from existing acceleration methods in its core motivation: rather than optimizing each model individually, CoM-PT is designed to accelerate the training pipeline at the model family level, scaling efficiently as the model family expands. Specifically, CoM-PT establishes a pre-training sequence for the model family, arranged in ascending order of model size, called model chain. In this chain, only the smallest model undergoes standard individual pre-training, while the other models are efficiently trained through sequential inverse knowledge transfer from their smaller predecessors by jointly reusing the knowledge in the parameter space and the feature space. As a result, CoM-PT enables all models to achieve performance that is mostly superior to standard individual training while significantly reducing training cost, and this is extensively validated across 45 datasets spanning zero-shot and fine-tuning tasks. Notably, its efficient scaling property yields a remarkable phenomenon: training more models even results in higher efficiency. For instance, when pre-training on CC3M: i) given ViT-L as the largest model, progressively prepending smaller models to the model chain reduces computational complexity by up to 72%; ii) within a fixed model size range, as the VFM family scales across 3, 4, and 7 models, the acceleration ratio of CoM-PT exhibits a striking leap: from 4.13X to 5.68X and 7.09X. Since CoM-PT is naturally agnostic to specific pre-training paradigms, we open-source the code to spur further extensions in more computationally intensive scenarios, such as large language model pre-training.
SliderQuant: Accurate Post-Training Quantization for LLMs
Mar 26, 2026In this paper, we address post-training quantization (PTQ) for large language models (LLMs) from an overlooked perspective: given a pre-trained high-precision LLM, the predominant sequential quantization framework treats different layers equally, but this may be not optimal in challenging bit-width settings. We empirically study the quantization impact of different layers on model accuracy, and observe that: (1) shallow/deep layers are usually more sensitive to quantization than intermediate layers; (2) among shallow/deep layers, the most sensitive one is the first/last layer, which exhibits significantly larger quantization error than others. These empirical observations imply that the quantization design for different layers of LLMs is required on multiple levels instead of a single level shared to all layers. Motivated by this, we propose a new PTQ framework termed Sliding-layer Quantization (SliderQuant) that relies on a simple adaptive sliding quantization concept facilitated by few learnable parameters. The base component of SliderQuant is called inter-layer sliding quantization, which incorporates three types of novel sliding window designs tailored for addressing the varying quantization sensitivity of shallow, intermediate and deep layers. The other component is called intra-layer sliding quantization that leverages an incremental strategy to quantize each window. As a result, SliderQuant has a strong ability to reduce quantization errors across layers. Extensive experiments on basic language generation, zero-shot commonsense reasoning and challenging math and code tasks with various LLMs, including Llama/Llama2/Llama3/Qwen2.5 model families, DeepSeek-R1 distilled models and large MoE models, show that our method outperforms existing PTQ methods (including the latest PTQ methods using rotation transformations) for both weight-only quantization and weight-activation quantization.
ScaleKD: Strong Vision Transformers Could Be Excellent Teachers
Nov 11, 2024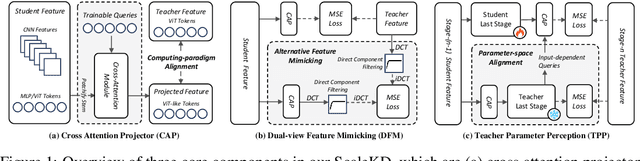
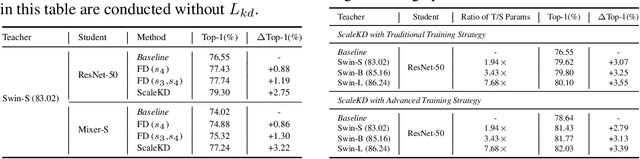
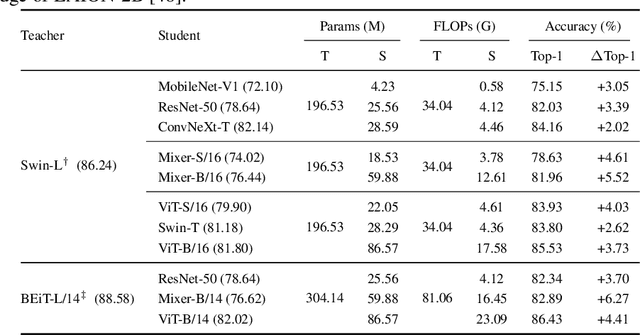
In this paper, we question if well pre-trained vision transformer (ViT) models could be used as teachers that exhibit scalable properties to advance cross architecture knowledge distillation (KD) research, in the context of using large-scale datasets for evaluation. To make this possible, our analysis underlines the importance of seeking effective strategies to align (1) feature computing paradigm differences, (2) model scale differences, and (3) knowledge density differences. By combining three coupled components namely cross attention projector, dual-view feature mimicking and teacher parameter perception tailored to address the above problems, we present a simple and effective KD method, called ScaleKD. Our method can train student backbones that span across a variety of convolutional neural network (CNN), multi-layer perceptron (MLP), and ViT architectures on image classification datasets, achieving state-of-the-art distillation performance. For instance, taking a well pre-trained Swin-L as the teacher model, our method gets 75.15%|82.03%|84.16%|78.63%|81.96%|83.93%|83.80%|85.53% top-1 accuracies for MobileNet-V1|ResNet-50|ConvNeXt-T|Mixer-S/16|Mixer-B/16|ViT-S/16|Swin-T|ViT-B/16 models trained on ImageNet-1K dataset from scratch, showing 3.05%|3.39%|2.02%|4.61%|5.52%|4.03%|2.62%|3.73% absolute gains to the individually trained counterparts. Intriguingly, when scaling up the size of teacher models or their pre-training datasets, our method showcases the desired scalable properties, bringing increasingly larger gains to student models. The student backbones trained by our method transfer well on downstream MS-COCO and ADE20K datasets. More importantly, our method could be used as a more efficient alternative to the time-intensive pre-training paradigm for any target student model if a strong pre-trained ViT is available, reducing the amount of viewed training samples up to 195x.
Development of a Platform to Enable Real Time, Non-disruptive Testing and Early Fault Detection of Critical High Voltage Transformers and Switchgears in High Speed-rail
Oct 01, 2024Partial discharge (PD) incidents can occur in critical components of high-speed rail electric systems, such as transformers and switchgears, due to localized insulation defects that cannot withstand electric stress, leading to potential flashovers. These incidents can escalate over time, resulting in breakdowns, downtime, and safety risks. Fortunately, PD activities emit radio frequency (RF) signals, allowing for the development of a hardware platform for real-time, non-invasive PD detection and monitoring. The system uses an RF antenna and high-speed data acquisition to scan signals across a configurable frequency range (100MHz to 3GHz), utilizing intermediate frequency modulation and sliding frequency windows for detailed analysis. When signals exceed a threshold, the system records the events, capturing both raw signal data and spectrum snapshots. Real-time data is streamed to a cloud server, offering remote access through a dedicated smartphone application, enabling maintenance teams to monitor and respond promptly. Laboratory testing has confirmed the system's ability to accurately capture RF signals and provide real-time PD monitoring, enhancing the reliability and safety of high-speed rail infrastructure.
Augmentation-Free Dense Contrastive Knowledge Distillation for Efficient Semantic Segmentation
Dec 07, 2023



In recent years, knowledge distillation methods based on contrastive learning have achieved promising results on image classification and object detection tasks. However, in this line of research, we note that less attention is paid to semantic segmentation. Existing methods heavily rely on data augmentation and memory buffer, which entail high computational resource demands when applying them to handle semantic segmentation that requires to preserve high-resolution feature maps for making dense pixel-wise predictions. In order to address this problem, we present Augmentation-free Dense Contrastive Knowledge Distillation (Af-DCD), a new contrastive distillation learning paradigm to train compact and accurate deep neural networks for semantic segmentation applications. Af-DCD leverages a masked feature mimicking strategy, and formulates a novel contrastive learning loss via taking advantage of tactful feature partitions across both channel and spatial dimensions, allowing to effectively transfer dense and structured local knowledge learnt by the teacher model to a target student model while maintaining training efficiency. Extensive experiments on five mainstream benchmarks with various teacher-student network pairs demonstrate the effectiveness of our approach. For instance, the DeepLabV3-Res18|DeepLabV3-MBV2 model trained by Af-DCD reaches 77.03%|76.38% mIOU on Cityscapes dataset when choosing DeepLabV3-Res101 as the teacher, setting new performance records. Besides that, Af-DCD achieves an absolute mIOU improvement of 3.26%|3.04%|2.75%|2.30%|1.42% compared with individually trained counterpart on Cityscapes|Pascal VOC|Camvid|ADE20K|COCO-Stuff-164K. Code is available at https://github.com/OSVAI/Af-DCD