 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTeaching Language Models to Self-Improve by Learning from Language Feedback
Jun 11, 2024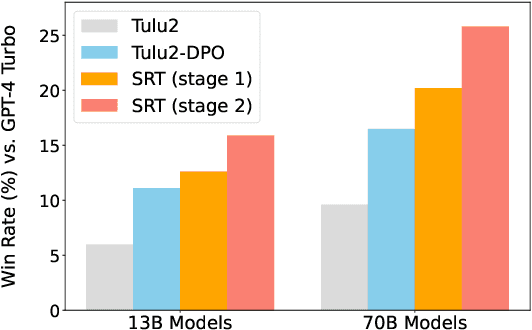

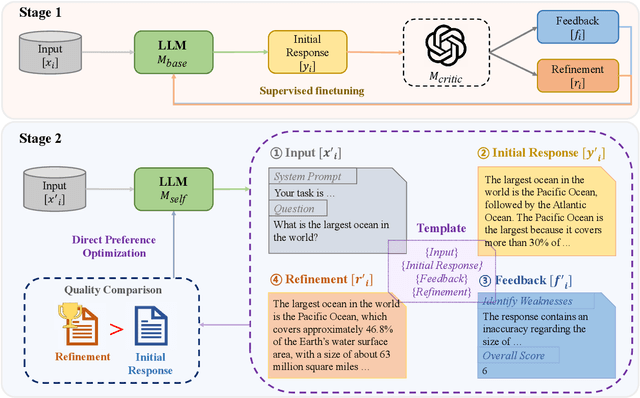

Aligning Large Language Models (LLMs) with human intentions and values is crucial yet challenging. Current methods primarily rely on human preferences, which are costly and insufficient in capturing nuanced feedback expressed in natural language. In this paper, we present Self-Refinement Tuning (SRT), a method that leverages model feedback for alignment, thereby reducing reliance on human annotations. SRT uses a base language model (e.g., Tulu2) to generate initial responses, which are critiqued and refined by a more advanced model (e.g., GPT-4-Turbo). This process enables the base model to self-evaluate and improve its outputs, facilitating continuous learning. SRT further optimizes the model by learning from its self-generated feedback and refinements, creating a feedback loop that promotes model improvement. Our empirical evaluations demonstrate that SRT significantly outperforms strong baselines across diverse tasks and model sizes. When applied to a 70B parameter model, SRT increases the win rate from 9.6\% to 25.8\% on the AlpacaEval 2.0 benchmark, surpassing well-established systems such as GPT-4-0314, Claude 2, and Gemini. Our analysis highlights the crucial role of language feedback in the success of SRT, suggesting potential for further exploration in this direction.
Prior Constraints-based Reward Model Training for Aligning Large Language Models
Apr 01, 2024



Reinforcement learning with human feedback for aligning large language models (LLMs) trains a reward model typically using ranking loss with comparison pairs.However, the training procedure suffers from an inherent problem: the uncontrolled scaling of reward scores during reinforcement learning due to the lack of constraints while training the reward model.This paper proposes a Prior Constraints-based Reward Model (namely PCRM) training method to mitigate this problem. PCRM incorporates prior constraints, specifically, length ratio and cosine similarity between outputs of each comparison pair, during reward model training to regulate optimization magnitude and control score margins. We comprehensively evaluate PCRM by examining its rank correlation with human preferences and its effectiveness in aligning LLMs via RL. Experimental results demonstrate that PCRM significantly improves alignment performance by effectively constraining reward score scaling. As another bonus, our method is easily integrated into arbitrary rank-based alignment methods, such as direct preference optimization, and can yield consistent improvement.
BioDrone: A Bionic Drone-based Single Object Tracking Benchmark for Robust Vision
Feb 07, 2024Single object tracking (SOT) is a fundamental problem in computer vision, with a wide range of applications, including autonomous driving, augmented reality, and robot navigation. The robustness of SOT faces two main challenges: tiny target and fast motion. These challenges are especially manifested in videos captured by unmanned aerial vehicles (UAV), where the target is usually far away from the camera and often with significant motion relative to the camera. To evaluate the robustness of SOT methods, we propose BioDrone -- the first bionic drone-based visual benchmark for SOT. Unlike existing UAV datasets, BioDrone features videos captured from a flapping-wing UAV system with a major camera shake due to its aerodynamics. BioDrone hence highlights the tracking of tiny targets with drastic changes between consecutive frames, providing a new robust vision benchmark for SOT. To date, BioDrone offers the largest UAV-based SOT benchmark with high-quality fine-grained manual annotations and automatically generates frame-level labels, designed for robust vision analyses. Leveraging our proposed BioDrone, we conduct a systematic evaluation of existing SOT methods, comparing the performance of 20 representative models and studying novel means of optimizing a SOTA method (KeepTrack KeepTrack) for robust SOT. Our evaluation leads to new baselines and insights for robust SOT. Moving forward, we hope that BioDrone will not only serve as a high-quality benchmark for robust SOT, but also invite future research into robust computer vision. The database, toolkits, evaluation server, and baseline results are available at http://biodrone.aitestunion.com.
* This paper is published in IJCV (refer to DOI). Please cite the published IJCV
Anomaly Detection of Particle Orbit in Accelerator using LSTM Deep Learning Technology
Jan 28, 2024A stable, reliable, and controllable orbit lock system is crucial to an electron (or ion) accelerator because the beam orbit and beam energy instability strongly affect the quality of the beam delivered to experimental halls. Currently, when the orbit lock system fails operators must manually intervene. This paper develops a Machine Learning based fault detection methodology to identify orbit lock anomalies and notify accelerator operations staff of the off-normal behavior. Our method is unsupervised, so it does not require labeled data. It uses Long-Short Memory Networks (LSTM) Auto Encoder to capture normal patterns and predict future values of monitoring sensors in the orbit lock system. Anomalies are detected when the prediction error exceeds a threshold. We conducted experiments using monitoring data from Jefferson Lab's Continuous Electron Beam Accelerator Facility (CEBAF). The results are promising: the percentage of real anomalies identified by our solution is 68.6%-89.3% using monitoring data of a single component in the orbit lock control system. The accuracy can be as high as 82%.
ESRL: Efficient Sampling-based Reinforcement Learning for Sequence Generation
Aug 04, 2023



Applying Reinforcement Learning (RL) to sequence generation models enables the direct optimization of long-term rewards (\textit{e.g.,} BLEU and human feedback), but typically requires large-scale sampling over a space of action sequences. This is a computational challenge as presented by the practice of sequence generation problems, such as machine translation, where we often deal with a large action space (\textit{e.g.,} a vocabulary) and a long action sequence (\textit{e.g.,} a translation). In this work, we introduce two-stage sampling and dynamic sampling approaches to improve the sampling efficiency during training sequence generation models via RL. We experiment with our approaches on the traditional sequence generation tasks, including machine translation and abstractive summarization. Furthermore, we evaluate our approaches in RL from human feedback (RLHF) through training a large language model using the reward model. Experimental results show that the efficient sampling-based RL, referred to as ESRL, can outperform all baselines in terms of both training efficiency and memory consumption. Notably, ESRL yields consistent performance gains over the strong REINFORCE, minimum risk training, and proximal policy optimization methods.
Improved Knowledge Distillation for Pre-trained Language Models via Knowledge Selection
Feb 01, 2023



Knowledge distillation addresses the problem of transferring knowledge from a teacher model to a student model. In this process, we typically have multiple types of knowledge extracted from the teacher model. The problem is to make full use of them to train the student model. Our preliminary study shows that: (1) not all of the knowledge is necessary for learning a good student model, and (2) knowledge distillation can benefit from certain knowledge at different training steps. In response to these, we propose an actor-critic approach to selecting appropriate knowledge to transfer during the process of knowledge distillation. In addition, we offer a refinement of the training algorithm to ease the computational burden. Experimental results on the GLUE datasets show that our method outperforms several strong knowledge distillation baselines significantly.