 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgent Incentives: A Causal Perspective
Feb 02, 2021

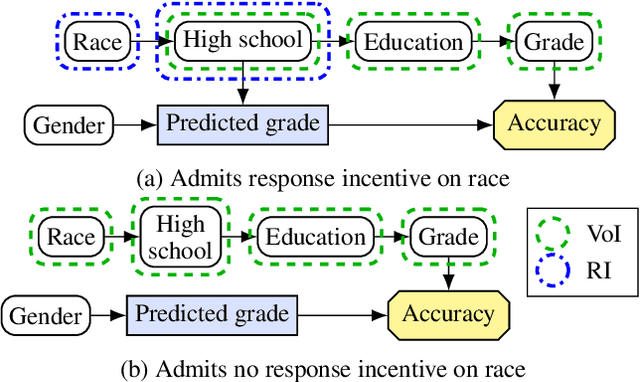
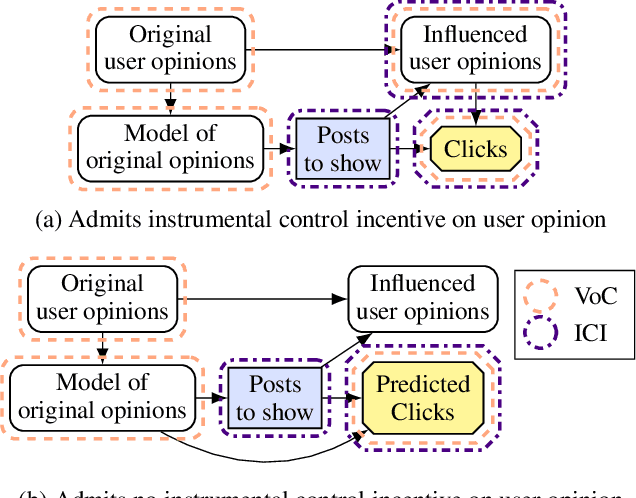
We present a framework for analysing agent incentives using causal influence diagrams. We establish that a well-known criterion for value of information is complete. We propose a new graphical criterion for value of control, establishing its soundness and completeness. We also introduce two new concepts for incentive analysis: response incentives indicate which changes in the environment affect an optimal decision, while instrumental control incentives establish whether an agent can influence its utility via a variable X. For both new concepts, we provide sound and complete graphical criteria. We show by example how these results can help with evaluating the safety and fairness of an AI system.
The Incentives that Shape Behaviour
Jan 20, 2020

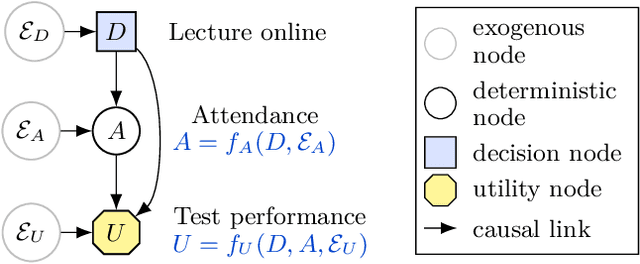
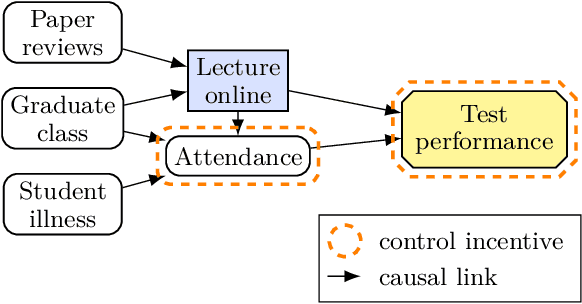
Which variables does an agent have an incentive to control with its decision, and which variables does it have an incentive to respond to? We formalise these incentives, and demonstrate unique graphical criteria for detecting them in any single decision causal influence diagram. To this end, we introduce structural causal influence models, a hybrid of the influence diagram and structural causal model frameworks. Finally, we illustrate how these incentives predict agent incentives in both fairness and AI safety applications.
Benchmarking Model-Based Reinforcement Learning
Jul 03, 2019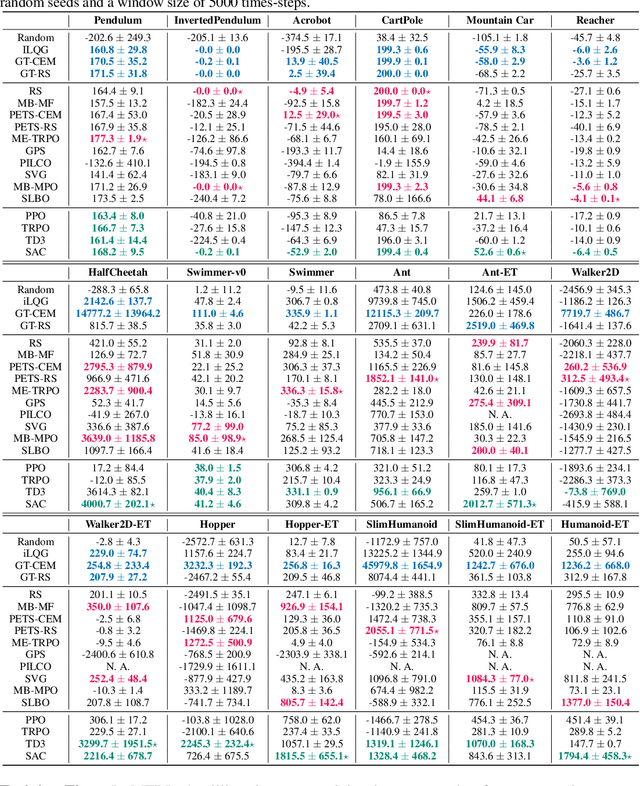
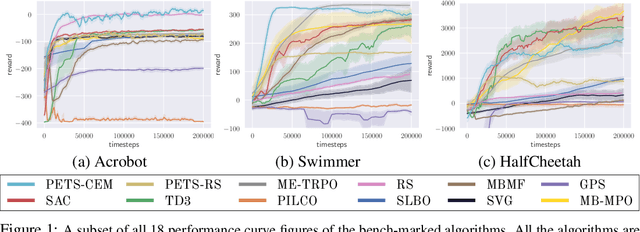
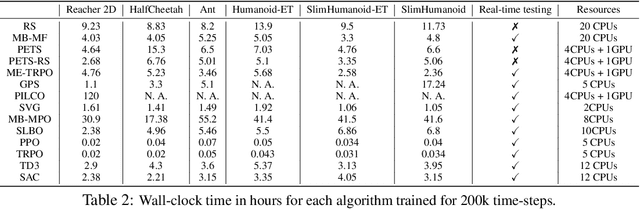
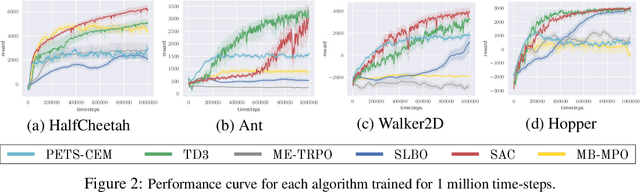
Model-based reinforcement learning (MBRL) is widely seen as having the potential to be significantly more sample efficient than model-free RL. However, research in model-based RL has not been very standardized. It is fairly common for authors to experiment with self-designed environments, and there are several separate lines of research, which are sometimes closed-sourced or not reproducible. Accordingly, it is an open question how these various existing MBRL algorithms perform relative to each other. To facilitate research in MBRL, in this paper we gather a wide collection of MBRL algorithms and propose over 18 benchmarking environments specially designed for MBRL. We benchmark these algorithms with unified problem settings, including noisy environments. Beyond cataloguing performance, we explore and unify the underlying algorithmic differences across MBRL algorithms. We characterize three key research challenges for future MBRL research: the dynamics bottleneck, the planning horizon dilemma, and the early-termination dilemma. Finally, to maximally facilitate future research on MBRL, we open-source our benchmark in http://www.cs.toronto.edu/~tingwuwang/mbrl.html.