 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStochastic Market Games
Jul 19, 2022



Some of the most relevant future applications of multi-agent systems like autonomous driving or factories as a service display mixed-motive scenarios, where agents might have conflicting goals. In these settings agents are likely to learn undesirable outcomes in terms of cooperation under independent learning, such as overly greedy behavior. Motivated from real world societies, in this work we propose to utilize market forces to provide incentives for agents to become cooperative. As demonstrated in an iterated version of the Prisoner's Dilemma, the proposed market formulation can change the dynamics of the game to consistently learn cooperative policies. Further we evaluate our approach in spatially and temporally extended settings for varying numbers of agents. We empirically find that the presence of markets can improve both the overall result and agent individual returns via their trading activities.
Synthesizing Safe Policies under Probabilistic Constraints with Reinforcement Learning and Bayesian Model Checking
May 08, 2020
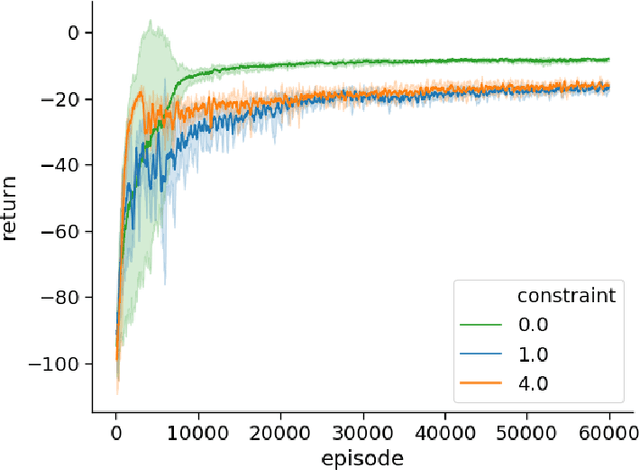

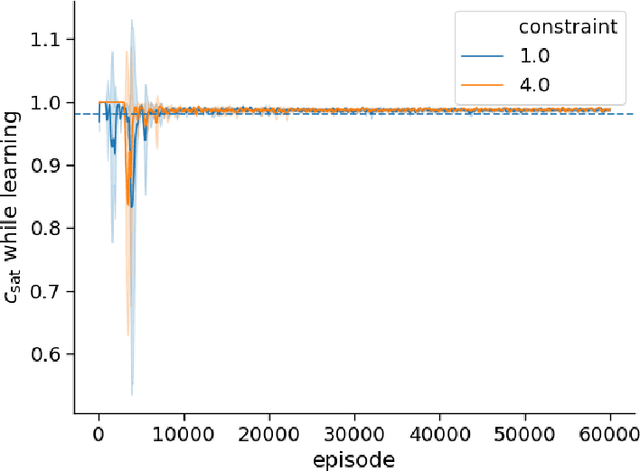
In this paper we propose Policy Synthesis under probabilistic Constraints (PSyCo), a systematic engineering method for synthesizing safe policies under probabilistic constraints with reinforcement learning and Bayesian model checking. As an implementation of PSyCo we introduce Safe Neural Evolutionary Strategies (SNES). SNES leverages Bayesian model checking while learning to adjust the Lagrangian of a constrained optimization problem derived from a PSyCo specification. We empirically evaluate SNES' ability to synthesize feasible policies in settings with formal safety requirements.
The Holy Grail of Quantum Artificial Intelligence: Major Challenges in Accelerating the Machine Learning Pipeline
Apr 29, 2020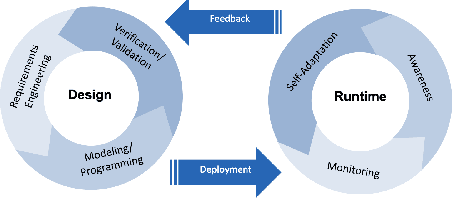

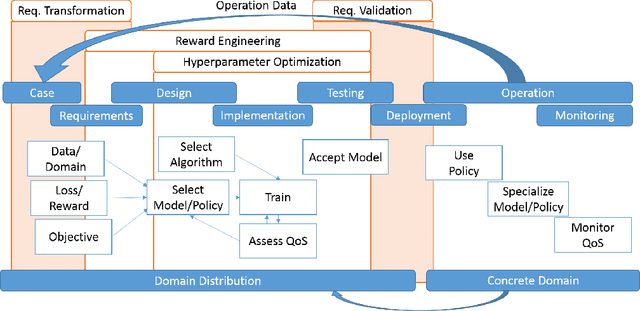
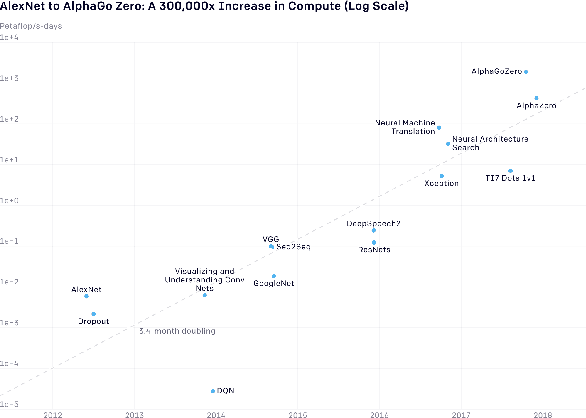
We discuss the synergetic connection between quantum computing and artificial intelligence. After surveying current approaches to quantum artificial intelligence and relating them to a formal model for machine learning processes, we deduce four major challenges for the future of quantum artificial intelligence: (i) Replace iterative training with faster quantum algorithms, (ii) distill the experience of larger amounts of data into the training process, (iii) allow quantum and classical components to be easily combined and exchanged, and (iv) build tools to thoroughly analyze whether observed benefits really stem from quantum properties of the algorithm.
Trajectory annotation using sequences of spatial perception
Apr 11, 2020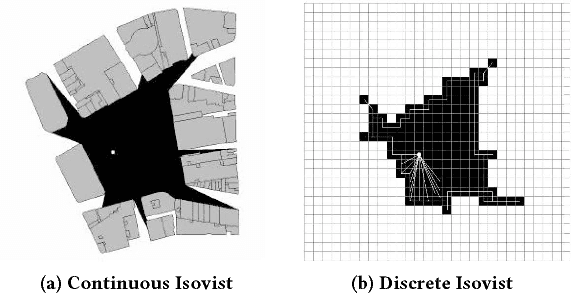

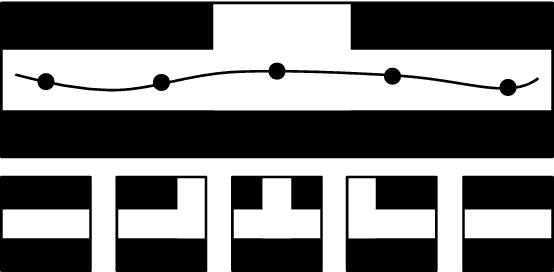

In the near future, more and more machines will perform tasks in the vicinity of human spaces or support them directly in their spatially bound activities. In order to simplify the verbal communication and the interaction between robotic units and/or humans, reliable and robust systems w.r.t. noise and processing results are needed. This work builds a foundation to address this task. By using a continuous representation of spatial perception in interiors learned from trajectory data, our approach clusters movement in dependency to its spatial context. We propose an unsupervised learning approach based on a neural autoencoding that learns semantically meaningful continuous encodings of spatio-temporal trajectory data. This learned encoding can be used to form prototypical representations. We present promising results that clear the path for future applications.
* 10 pages, 17 figures
Bayesian Surprise in Indoor Environments
Apr 11, 2020



This paper proposes a novel method to identify unexpected structures in 2D floor plans using the concept of Bayesian Surprise. Taking into account that a person's expectation is an important aspect of the perception of space, we exploit the theory of Bayesian Surprise to robustly model expectation and thus surprise in the context of building structures. We use Isovist Analysis, which is a popular space syntax technique, to turn qualitative object attributes into quantitative environmental information. Since isovists are location-specific patterns of visibility, a sequence of isovists describes the spatial perception during a movement along multiple points in space. We then use Bayesian Surprise in a feature space consisting of these isovist readings. To demonstrate the suitability of our approach, we take "snapshots" of an agent's local environment to provide a short list of images that characterize a traversed trajectory through a 2D indoor environment. Those fingerprints represent surprising regions of a tour, characterize the traversed map and enable indoor LBS to focus more on important regions. Given this idea, we propose to use "surprise" as a new dimension of context in indoor location-based services (LBS). Agents of LBS, such as mobile robots or non-player characters in computer games, may use the context surprise to focus more on important regions of a map for a better use or understanding of the floor plan.
* 10 pages, 16 figures
Uncertainty-Based Out-of-Distribution Classification in Deep Reinforcement Learning
Dec 31, 2019
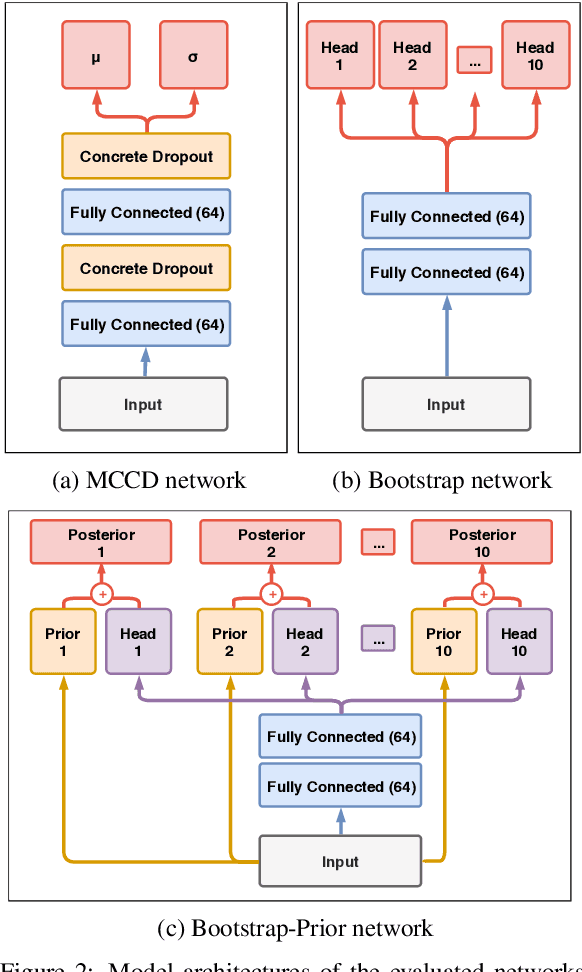

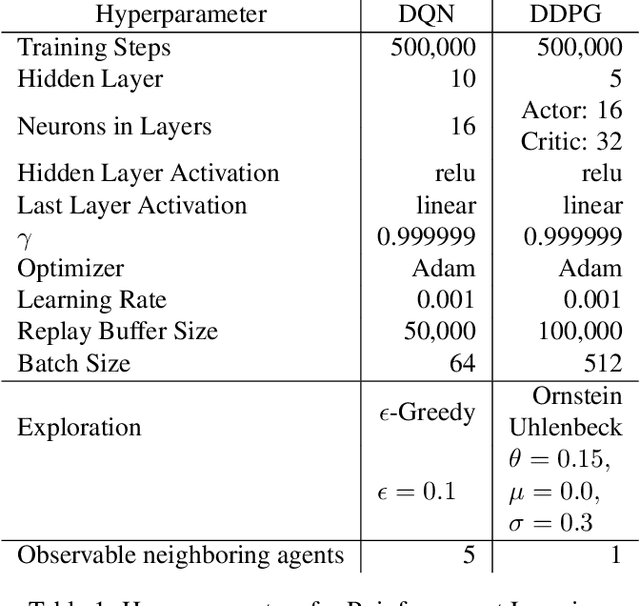
Robustness to out-of-distribution (OOD) data is an important goal in building reliable machine learning systems. Especially in autonomous systems, wrong predictions for OOD inputs can cause safety critical situations. As a first step towards a solution, we consider the problem of detecting such data in a value-based deep reinforcement learning (RL) setting. Modelling this problem as a one-class classification problem, we propose a framework for uncertainty-based OOD classification: UBOOD. It is based on the effect that an agent's epistemic uncertainty is reduced for situations encountered during training (in-distribution), and thus lower than for unencountered (OOD) situations. Being agnostic towards the approach used for estimating epistemic uncertainty, combinations with different uncertainty estimation methods, e.g. approximate Bayesian inference methods or ensembling techniques are possible. We further present a first viable solution for calculating a dynamic classification threshold, based on the uncertainty distribution of the training data. Evaluation shows that the framework produces reliable classification results when combined with ensemble-based estimators, while the combination with concrete dropout-based estimators fails to reliably detect OOD situations. In summary, UBOOD presents a viable approach for OOD classification in deep RL settings by leveraging the epistemic uncertainty of the agent's value function.
Emergent Escape-based Flocking Behavior using Multi-Agent Reinforcement Learning
May 10, 2019
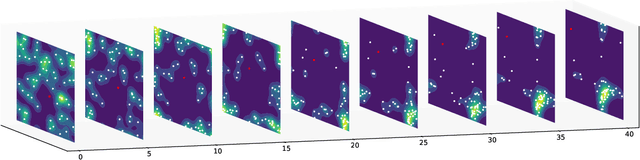
In nature, flocking or swarm behavior is observed in many species as it has beneficial properties like reducing the probability of being caught by a predator. In this paper, we propose SELFish (Swarm Emergent Learning Fish), an approach with multiple autonomous agents which can freely move in a continuous space with the objective to avoid being caught by a present predator. The predator has the property that it might get distracted by multiple possible preys in its vicinity. We show that this property in interaction with self-interested agents which are trained with reinforcement learning to solely survive as long as possible leads to flocking behavior similar to Boids, a common simulation for flocking behavior. Furthermore we present interesting insights in the swarming behavior and in the process of agents being caught in our modeled environment.
Memory Bounded Open-Loop Planning in Large POMDPs using Thompson Sampling
May 10, 2019

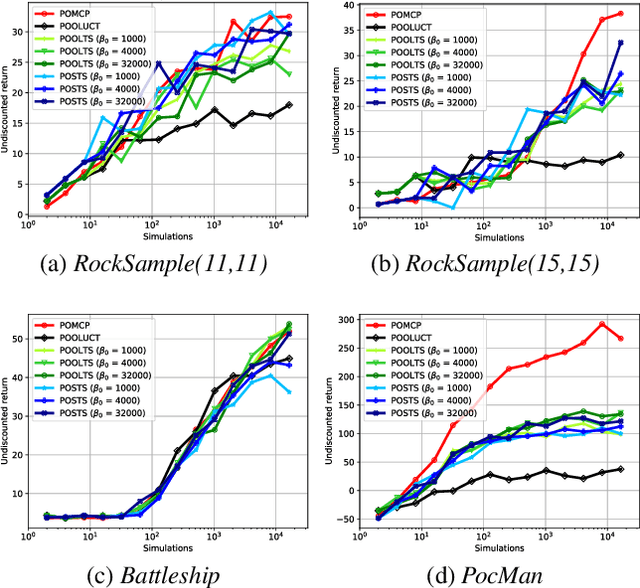
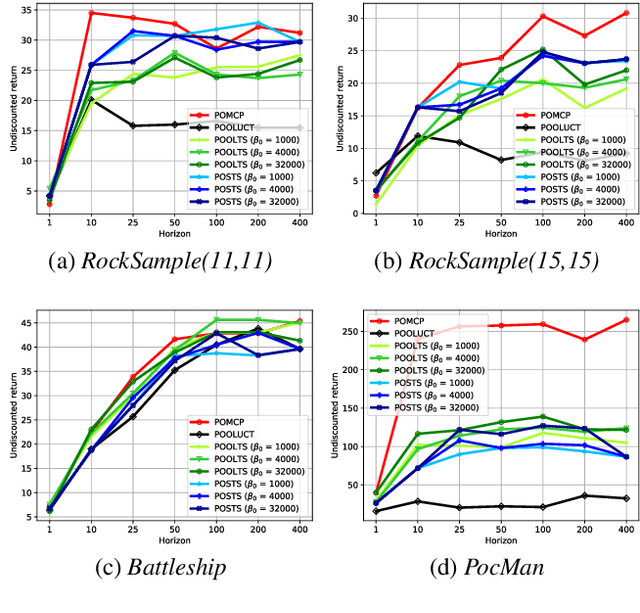
State-of-the-art approaches to partially observable planning like POMCP are based on stochastic tree search. While these approaches are computationally efficient, they may still construct search trees of considerable size, which could limit the performance due to restricted memory resources. In this paper, we propose Partially Observable Stacked Thompson Sampling (POSTS), a memory bounded approach to open-loop planning in large POMDPs, which optimizes a fixed size stack of Thompson Sampling bandits. We empirically evaluate POSTS in four large benchmark problems and compare its performance with different tree-based approaches. We show that POSTS achieves competitive performance compared to tree-based open-loop planning and offers a performance-memory tradeoff, making it suitable for partially observable planning with highly restricted computational and memory resources.
Distributed Policy Iteration for Scalable Approximation of Cooperative Multi-Agent Policies
Jan 25, 2019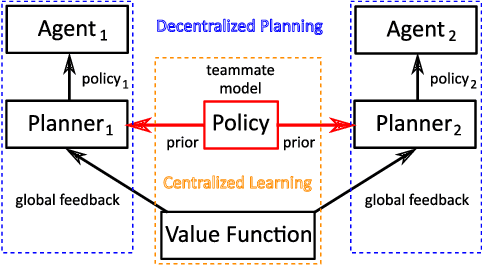
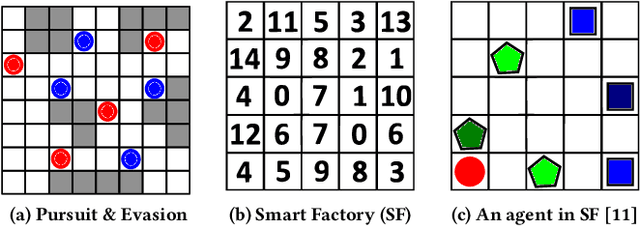
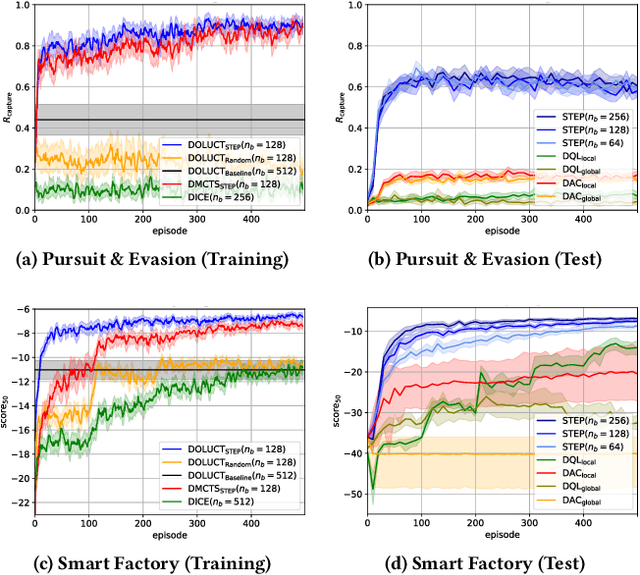
Decision making in multi-agent systems (MAS) is a great challenge due to enormous state and joint action spaces as well as uncertainty, making centralized control generally infeasible. Decentralized control offers better scalability and robustness but requires mechanisms to coordinate on joint tasks and to avoid conflicts. Common approaches to learn decentralized policies for cooperative MAS suffer from non-stationarity and lacking credit assignment, which can lead to unstable and uncoordinated behavior in complex environments. In this paper, we propose Strong Emergent Policy approximation (STEP), a scalable approach to learn strong decentralized policies for cooperative MAS with a distributed variant of policy iteration. For that, we use function approximation to learn from action recommendations of a decentralized multi-agent planning algorithm. STEP combines decentralized multi-agent planning with centralized learning, only requiring a generative model for distributed black box optimization. We experimentally evaluate STEP in two challenging and stochastic domains with large state and joint action spaces and show that STEP is able to learn stronger policies than standard multi-agent reinforcement learning algorithms, when combining multi-agent open-loop planning with centralized function approximation. The learned policies can be reintegrated into the multi-agent planning process to further improve performance.
Uncertainty-Based Out-of-Distribution Detection in Deep Reinforcement Learning
Jan 08, 2019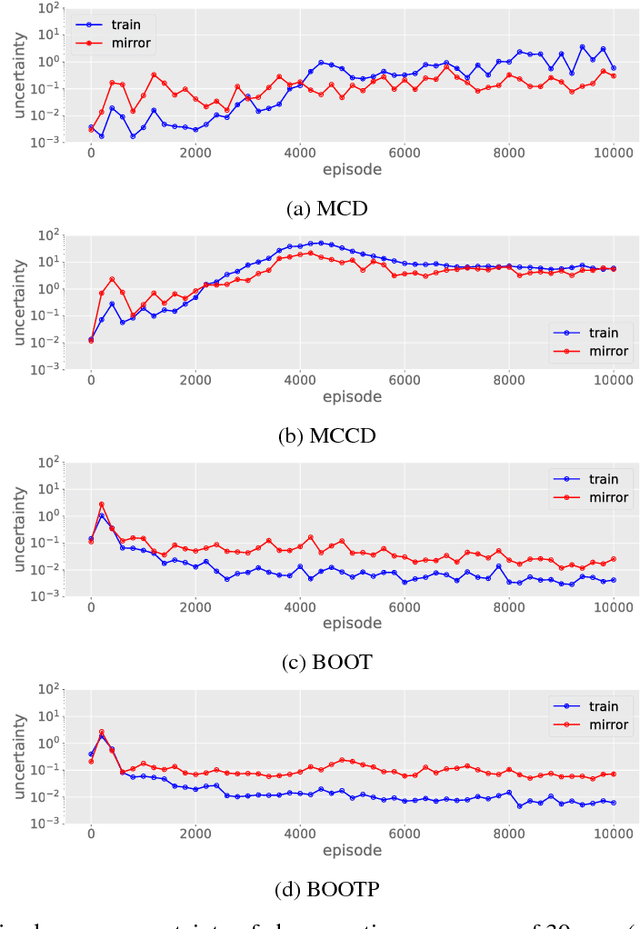
We consider the problem of detecting out-of-distribution (OOD) samples in deep reinforcement learning. In a value based reinforcement learning setting, we propose to use uncertainty estimation techniques directly on the agent's value estimating neural network to detect OOD samples. The focus of our work lies in analyzing the suitability of approximate Bayesian inference methods and related ensembling techniques that generate uncertainty estimates. Although prior work has shown that dropout-based variational inference techniques and bootstrap-based approaches can be used to model epistemic uncertainty, the suitability for detecting OOD samples in deep reinforcement learning remains an open question. Our results show that uncertainty estimation can be used to differentiate in- from out-of-distribution samples. Over the complete training process of the reinforcement learning agents, bootstrap-based approaches tend to produce more reliable epistemic uncertainty estimates, when compared to dropout-based approaches.