 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Transformers for Primates Classification and Covid Detection
Dec 20, 2022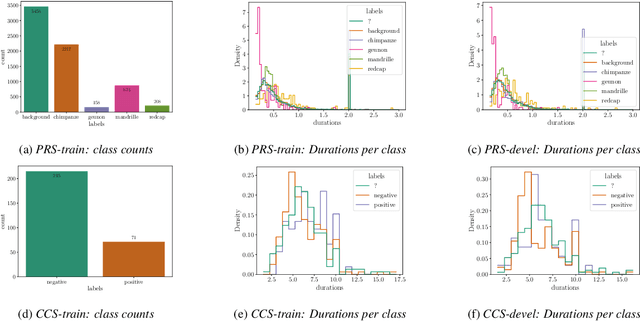
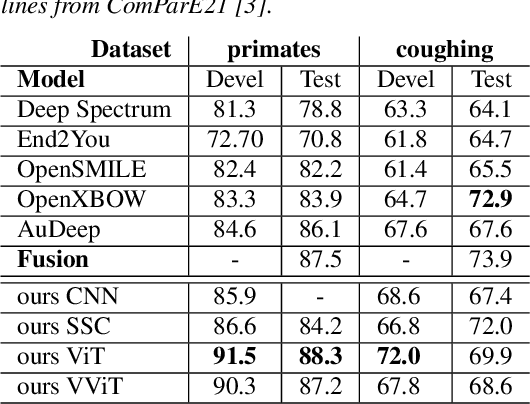
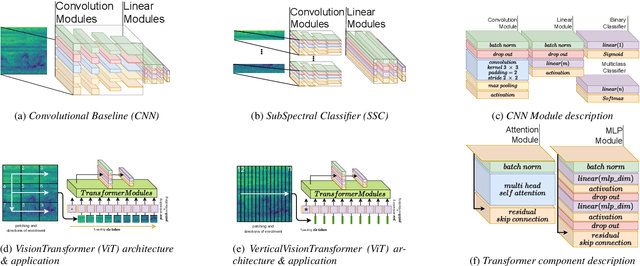
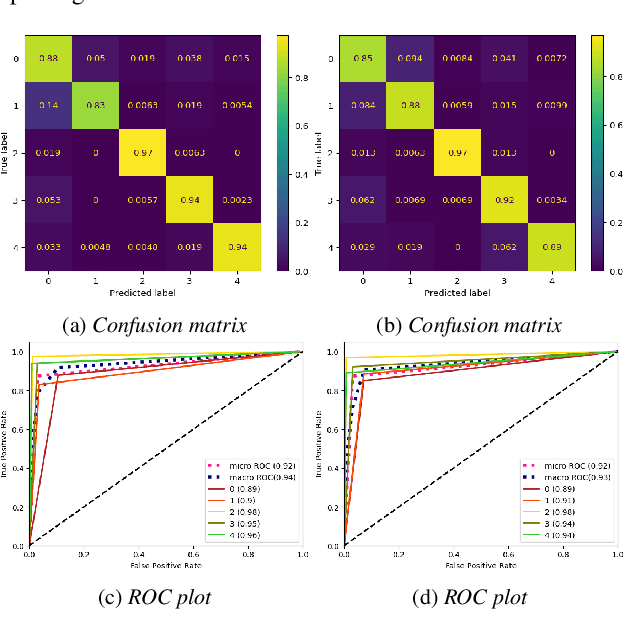
We apply the vision transformer, a deep machine learning model build around the attention mechanism, on mel-spectrogram representations of raw audio recordings. When adding mel-based data augmentation techniques and sample-weighting, we achieve comparable performance on both (PRS and CCS challenge) tasks of ComParE21, outperforming most single model baselines. We further introduce overlapping vertical patching and evaluate the influence of parameter configurations. Index Terms: audio classification, attention, mel-spectrogram, unbalanced data-sets, computational paralinguistics
Capturing Dependencies within Machine Learning via a Formal Process Model
Aug 10, 2022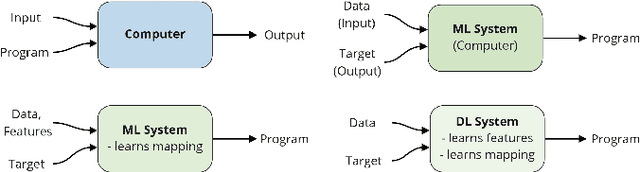
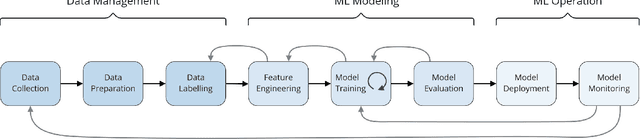
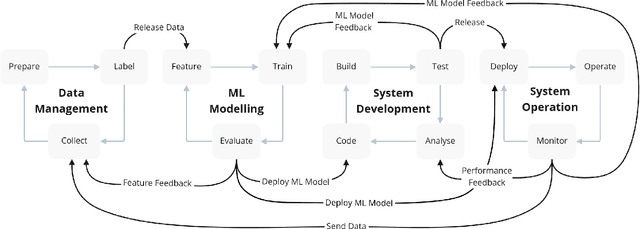
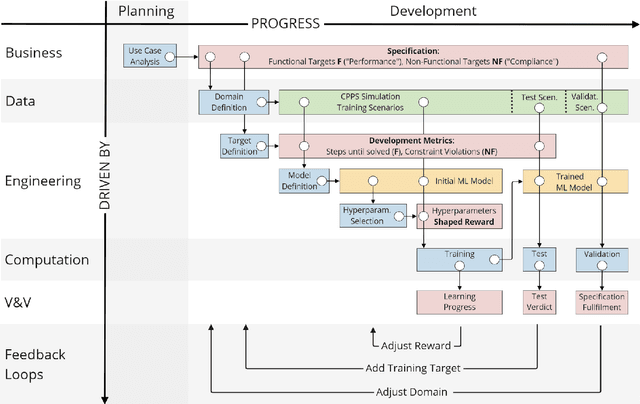
The development of Machine Learning (ML) models is more than just a special case of software development (SD): ML models acquire properties and fulfill requirements even without direct human interaction in a seemingly uncontrollable manner. Nonetheless, the underlying processes can be described in a formal way. We define a comprehensive SD process model for ML that encompasses most tasks and artifacts described in the literature in a consistent way. In addition to the production of the necessary artifacts, we also focus on generating and validating fitting descriptions in the form of specifications. We stress the importance of further evolving the ML model throughout its life-cycle even after initial training and testing. Thus, we provide various interaction points with standard SD processes in which ML often is an encapsulated task. Further, our SD process model allows to formulate ML as a (meta-) optimization problem. If automated rigorously, it can be used to realize self-adaptive autonomous systems. Finally, our SD process model features a description of time that allows to reason about the progress within ML development processes. This might lead to further applications of formal methods within the field of ML.
Quantifying Multimodality in World Models
Dec 14, 2021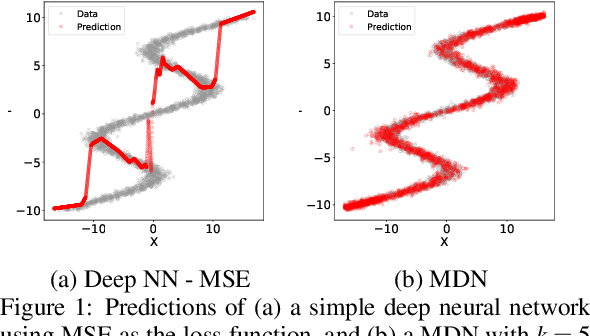
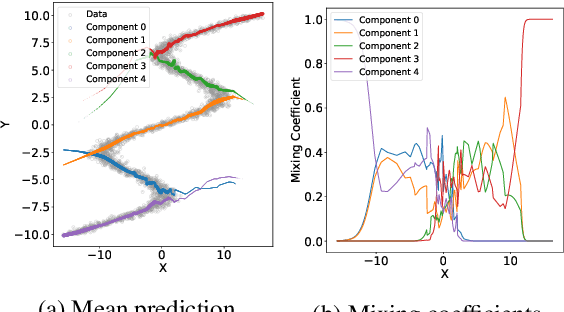
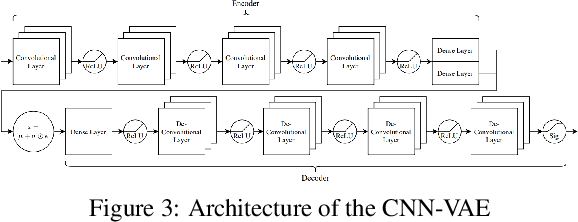
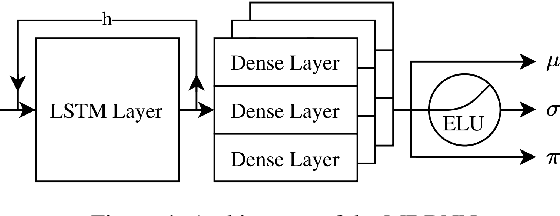
Model-based Deep Reinforcement Learning (RL) assumes the availability of a model of an environment's underlying transition dynamics. This model can be used to predict future effects of an agent's possible actions. When no such model is available, it is possible to learn an approximation of the real environment, e.g. by using generative neural networks, sometimes also called World Models. As most real-world environments are stochastic in nature and the transition dynamics are oftentimes multimodal, it is important to use a modelling technique that is able to reflect this multimodal uncertainty. In order to safely deploy such learning systems in the real world, especially in an industrial context, it is paramount to consider these uncertainties. In this work, we analyze existing and propose new metrics for the detection and quantification of multimodal uncertainty in RL based World Models. The correct modelling & detection of uncertain future states lays the foundation for handling critical situations in a safe way, which is a prerequisite for deploying RL systems in real-world settings.
SAT-MARL: Specification Aware Training in Multi-Agent Reinforcement Learning
Dec 14, 2020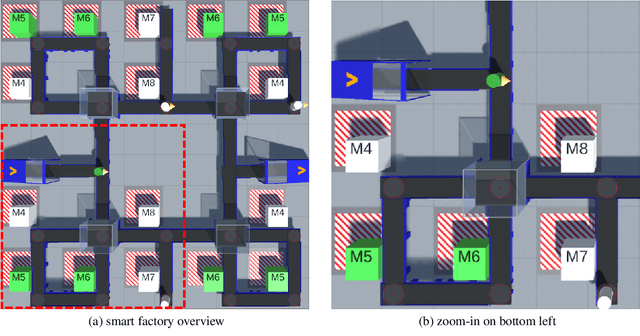
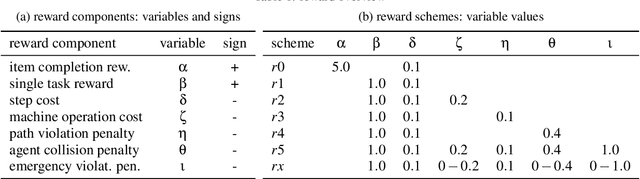
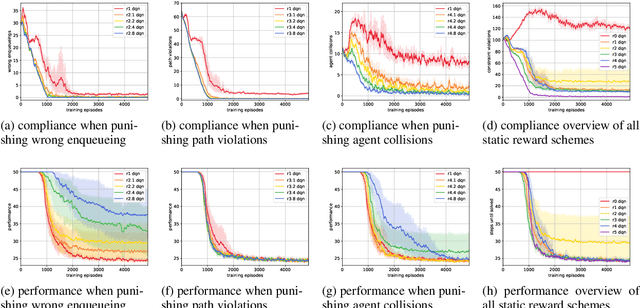
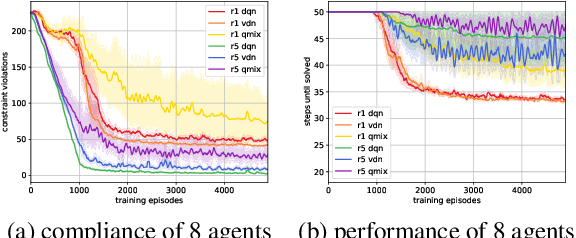
A characteristic of reinforcement learning is the ability to develop unforeseen strategies when solving problems. While such strategies sometimes yield superior performance, they may also result in undesired or even dangerous behavior. In industrial scenarios, a system's behavior also needs to be predictable and lie within defined ranges. To enable the agents to learn (how) to align with a given specification, this paper proposes to explicitly transfer functional and non-functional requirements into shaped rewards. Experiments are carried out on the smart factory, a multi-agent environment modeling an industrial lot-size-one production facility, with up to eight agents and different multi-agent reinforcement learning algorithms. Results indicate that compliance with functional and non-functional constraints can be achieved by the proposed approach.
Surgical Mask Detection with Convolutional Neural Networks and Data Augmentations on Spectrograms
Aug 11, 2020
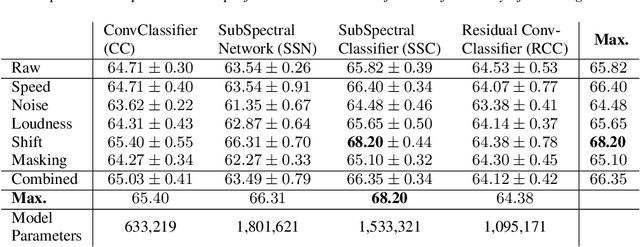
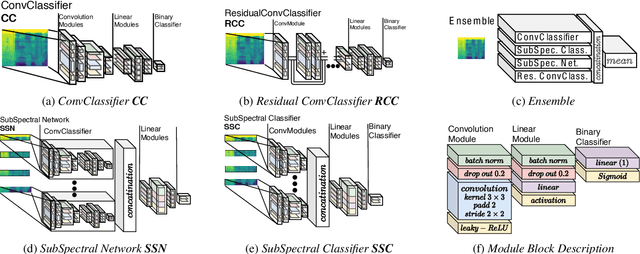
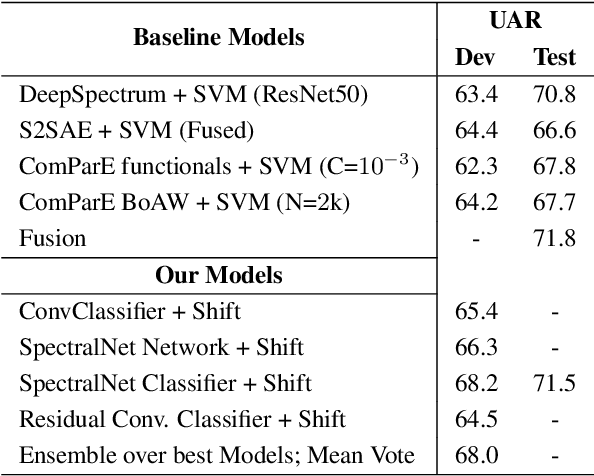
In many fields of research, labeled datasets are hard to acquire. This is where data augmentation promises to overcome the lack of training data in the context of neural network engineering and classification tasks. The idea here is to reduce model over-fitting to the feature distribution of a small under-descriptive training dataset. We try to evaluate such data augmentation techniques to gather insights in the performance boost they provide for several convolutional neural networks on mel-spectrogram representations of audio data. We show the impact of data augmentation on the binary classification task of surgical mask detection in samples of human voice (ComParE Challenge 2020). Also we consider four varying architectures to account for augmentation robustness. Results show that most of the baselines given by ComParE are outperformed.
Policy Entropy for Out-of-Distribution Classification
May 25, 2020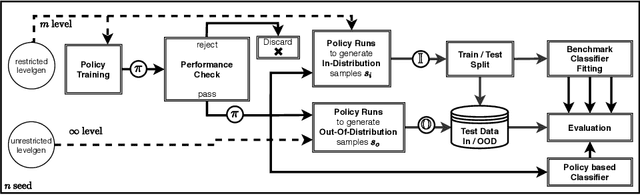
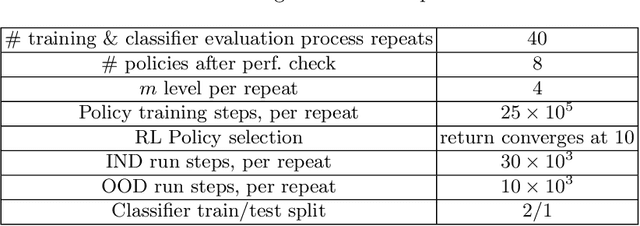

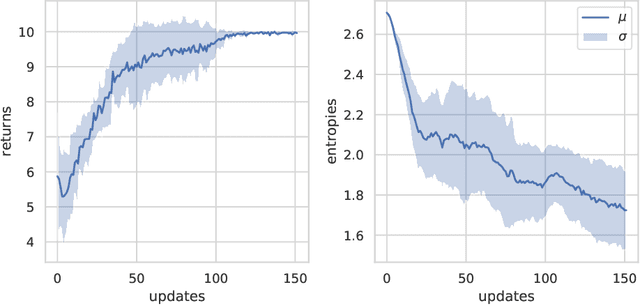
One critical prerequisite for the deployment of reinforcement learning systems in the real world is the ability to reliably detect situations on which the agent was not trained. Such situations could lead to potential safety risks when wrong predictions lead to the execution of harmful actions. In this work, we propose PEOC, a new policy entropy based out-of-distribution classifier that reliably detects unencountered states in deep reinforcement learning. It is based on using the entropy of an agent's policy as the classification score of a one-class classifier. We evaluate our approach using a procedural environment generator. Results show that PEOC is highly competitive against state-of-the-art one-class classification algorithms on the evaluated environments. Furthermore, we present a structured process for benchmarking out-of-distribution classification in reinforcement learning.
Trajectory annotation using sequences of spatial perception
Apr 11, 2020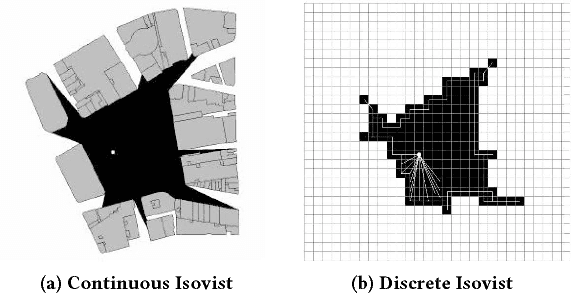

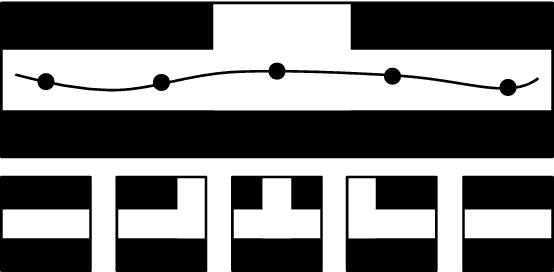

In the near future, more and more machines will perform tasks in the vicinity of human spaces or support them directly in their spatially bound activities. In order to simplify the verbal communication and the interaction between robotic units and/or humans, reliable and robust systems w.r.t. noise and processing results are needed. This work builds a foundation to address this task. By using a continuous representation of spatial perception in interiors learned from trajectory data, our approach clusters movement in dependency to its spatial context. We propose an unsupervised learning approach based on a neural autoencoding that learns semantically meaningful continuous encodings of spatio-temporal trajectory data. This learned encoding can be used to form prototypical representations. We present promising results that clear the path for future applications.
* 10 pages, 17 figures
Bayesian Surprise in Indoor Environments
Apr 11, 2020



This paper proposes a novel method to identify unexpected structures in 2D floor plans using the concept of Bayesian Surprise. Taking into account that a person's expectation is an important aspect of the perception of space, we exploit the theory of Bayesian Surprise to robustly model expectation and thus surprise in the context of building structures. We use Isovist Analysis, which is a popular space syntax technique, to turn qualitative object attributes into quantitative environmental information. Since isovists are location-specific patterns of visibility, a sequence of isovists describes the spatial perception during a movement along multiple points in space. We then use Bayesian Surprise in a feature space consisting of these isovist readings. To demonstrate the suitability of our approach, we take "snapshots" of an agent's local environment to provide a short list of images that characterize a traversed trajectory through a 2D indoor environment. Those fingerprints represent surprising regions of a tour, characterize the traversed map and enable indoor LBS to focus more on important regions. Given this idea, we propose to use "surprise" as a new dimension of context in indoor location-based services (LBS). Agents of LBS, such as mobile robots or non-player characters in computer games, may use the context surprise to focus more on important regions of a map for a better use or understanding of the floor plan.
* 10 pages, 16 figures
Uncertainty-Based Out-of-Distribution Classification in Deep Reinforcement Learning
Dec 31, 2019
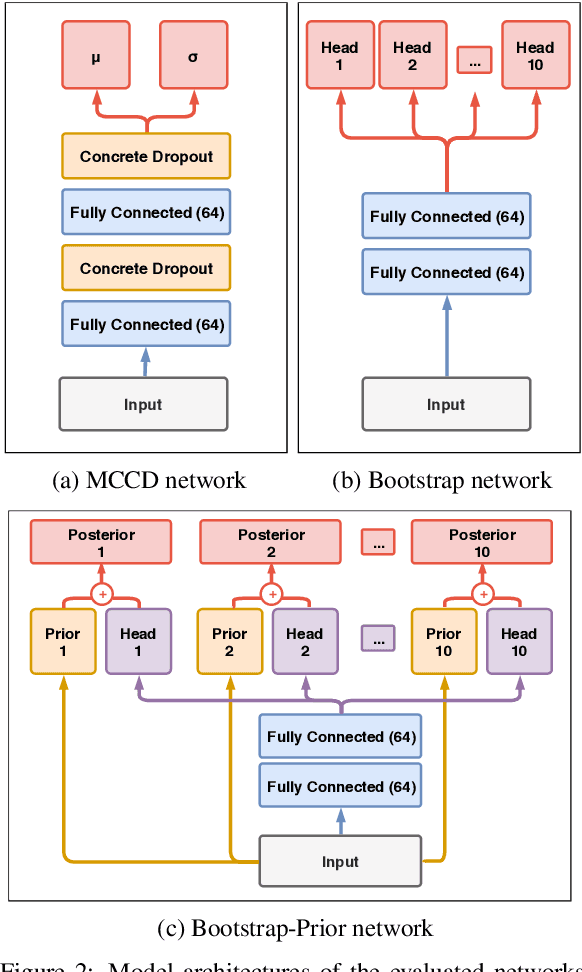
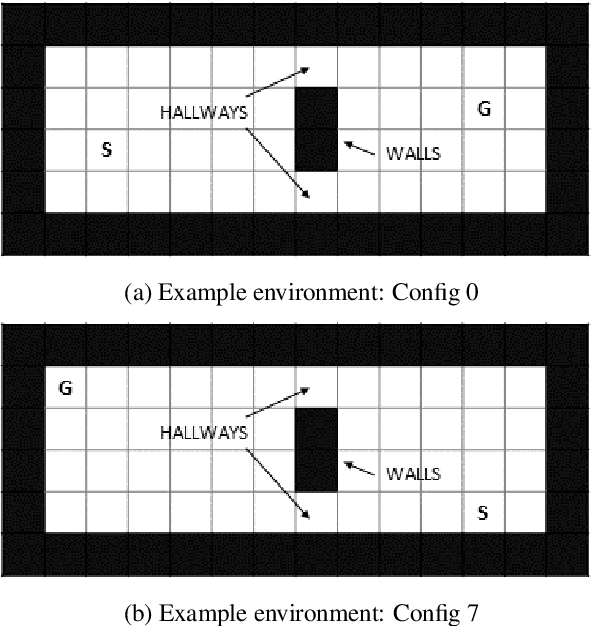

Robustness to out-of-distribution (OOD) data is an important goal in building reliable machine learning systems. Especially in autonomous systems, wrong predictions for OOD inputs can cause safety critical situations. As a first step towards a solution, we consider the problem of detecting such data in a value-based deep reinforcement learning (RL) setting. Modelling this problem as a one-class classification problem, we propose a framework for uncertainty-based OOD classification: UBOOD. It is based on the effect that an agent's epistemic uncertainty is reduced for situations encountered during training (in-distribution), and thus lower than for unencountered (OOD) situations. Being agnostic towards the approach used for estimating epistemic uncertainty, combinations with different uncertainty estimation methods, e.g. approximate Bayesian inference methods or ensembling techniques are possible. We further present a first viable solution for calculating a dynamic classification threshold, based on the uncertainty distribution of the training data. Evaluation shows that the framework produces reliable classification results when combined with ensemble-based estimators, while the combination with concrete dropout-based estimators fails to reliably detect OOD situations. In summary, UBOOD presents a viable approach for OOD classification in deep RL settings by leveraging the epistemic uncertainty of the agent's value function.
Uncertainty-Based Out-of-Distribution Detection in Deep Reinforcement Learning
Jan 08, 2019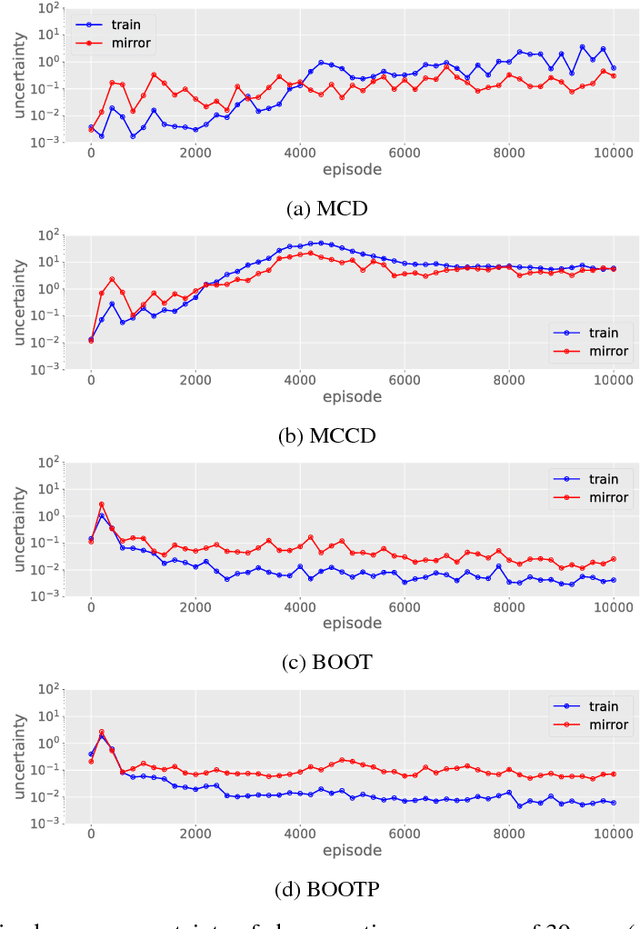
We consider the problem of detecting out-of-distribution (OOD) samples in deep reinforcement learning. In a value based reinforcement learning setting, we propose to use uncertainty estimation techniques directly on the agent's value estimating neural network to detect OOD samples. The focus of our work lies in analyzing the suitability of approximate Bayesian inference methods and related ensembling techniques that generate uncertainty estimates. Although prior work has shown that dropout-based variational inference techniques and bootstrap-based approaches can be used to model epistemic uncertainty, the suitability for detecting OOD samples in deep reinforcement learning remains an open question. Our results show that uncertainty estimation can be used to differentiate in- from out-of-distribution samples. Over the complete training process of the reinforcement learning agents, bootstrap-based approaches tend to produce more reliable epistemic uncertainty estimates, when compared to dropout-based approaches.