 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurgical Mask Detection with Convolutional Neural Networks and Data Augmentations on Spectrograms
Paper and Code

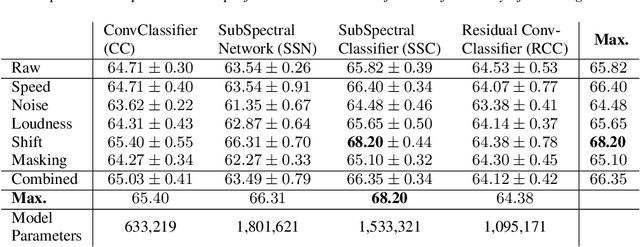
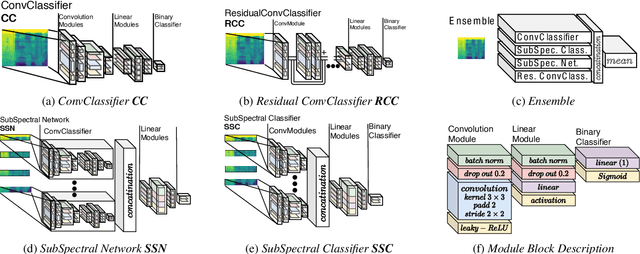
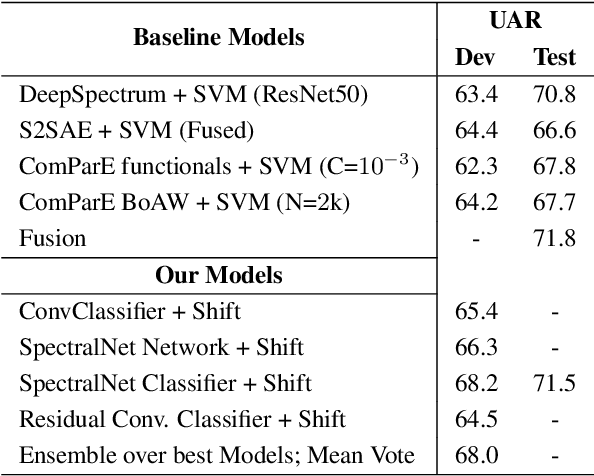
In many fields of research, labeled datasets are hard to acquire. This is where data augmentation promises to overcome the lack of training data in the context of neural network engineering and classification tasks. The idea here is to reduce model over-fitting to the feature distribution of a small under-descriptive training dataset. We try to evaluate such data augmentation techniques to gather insights in the performance boost they provide for several convolutional neural networks on mel-spectrogram representations of audio data. We show the impact of data augmentation on the binary classification task of surgical mask detection in samples of human voice (ComParE Challenge 2020). Also we consider four varying architectures to account for augmentation robustness. Results show that most of the baselines given by ComParE are outperformed.