 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConstructing Organism Networks from Collaborative Self-Replicators
Paper and Code
Dec 20, 2022


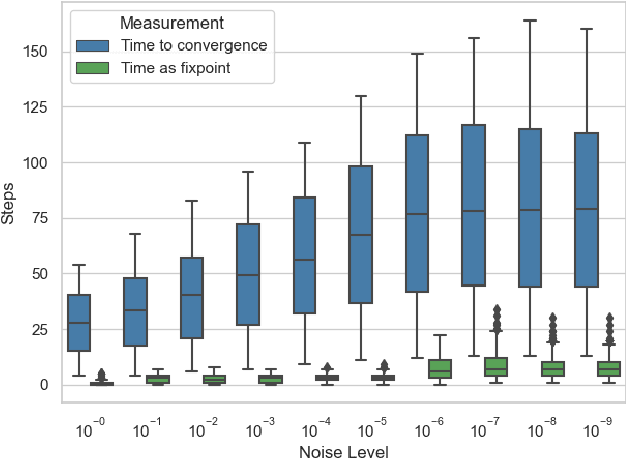
We introduce organism networks, which function like a single neural network but are composed of several neural particle networks; while each particle network fulfils the role of a single weight application within the organism network, it is also trained to self-replicate its own weights. As organism networks feature vastly more parameters than simpler architectures, we perform our initial experiments on an arithmetic task as well as on simplified MNIST-dataset classification as a collective. We observe that individual particle networks tend to specialise in either of the tasks and that the ones fully specialised in the secondary task may be dropped from the network without hindering the computational accuracy of the primary task. This leads to the discovery of a novel pruning-strategy for sparse neural networks