 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCalibrated Preference Learning: The Case of Label Ranking
May 28, 2026Calibration, the alignment of predicted probabilities with true outcome frequencies, is essential for reliable decision-making. While extensively studied for classification and regression, calibration has not been formally addressed for probabilistic label ranking, where the goal is to predict a distribution over orderings of a label set. Naively treating rankings as classes ignores their structure and fails to capture important modalities such as pairwise and top-k predictions. We formalize calibration for label ranking and develop a hierarchy of notions covering full rankings, sub-rankings, and top-k rankings. We prove that full-rank calibration implies the others but not conversely, and sub-ranking and top-k calibration are incomparable. Empirically, we find popular label ranking models are often poorly calibrated, with substantial differences between sub-ranking and top-k metrics. Applying our framework to RLHF reward models, we find that calibration correlates strongly but not perfectly with benchmark accuracy, suggesting it captures a meaningful quality dimension beyond top-1 accuracy. These findings motivate future work on understanding the downstream effects of miscalibration and developing methods to correct it.
The Power of Stories: Narrative Priming Shapes How LLM Agents Collaborate and Compete
May 08, 2025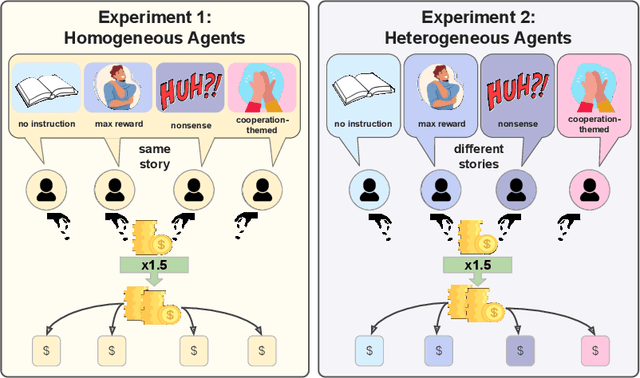
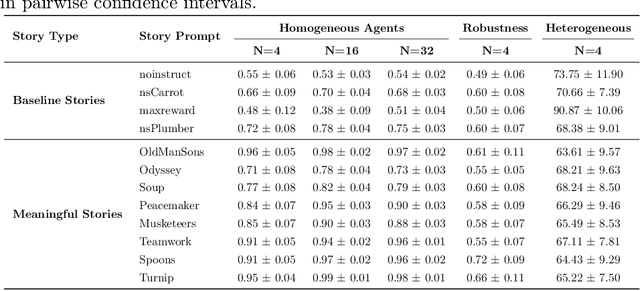
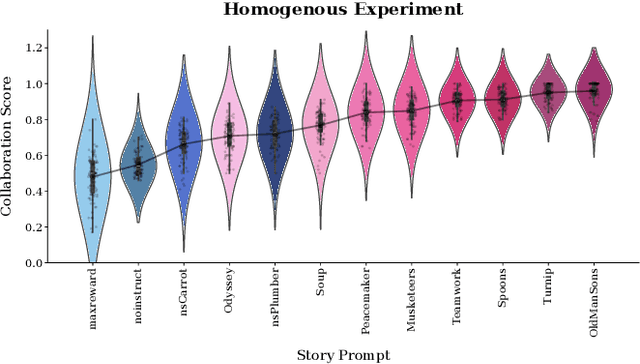
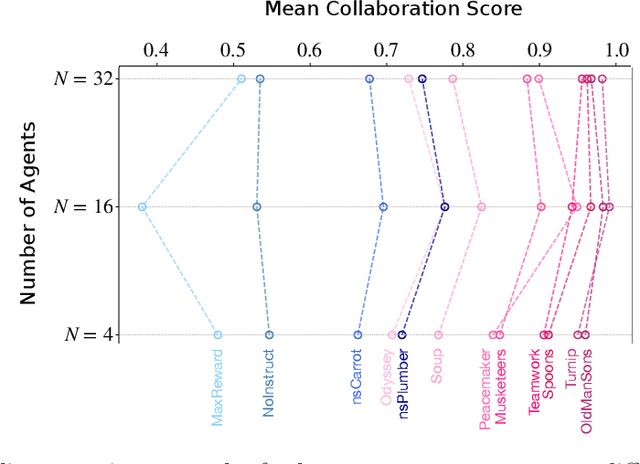
According to Yuval Noah Harari, large-scale human cooperation is driven by shared narratives that encode common beliefs and values. This study explores whether such narratives can similarly nudge LLM agents toward collaboration. We use a finitely repeated public goods game in which LLM agents choose either cooperative or egoistic spending strategies. We prime agents with stories highlighting teamwork to different degrees and test how this influences negotiation outcomes. Our experiments explore four questions:(1) How do narratives influence negotiation behavior? (2) What differs when agents share the same story versus different ones? (3) What happens when the agent numbers grow? (4) Are agents resilient against self-serving negotiators? We find that story-based priming significantly affects negotiation strategies and success rates. Common stories improve collaboration, benefiting each agent. By contrast, priming agents with different stories reverses this effect, and those agents primed toward self-interest prevail. We hypothesize that these results carry implications for multi-agent system design and AI alignment.
Energy Discrepancies: A Score-Independent Loss for Energy-Based Models
Jul 12, 2023



Energy-based models are a simple yet powerful class of probabilistic models, but their widespread adoption has been limited by the computational burden of training them. We propose a novel loss function called Energy Discrepancy (ED) which does not rely on the computation of scores or expensive Markov chain Monte Carlo. We show that ED approaches the explicit score matching and negative log-likelihood loss under different limits, effectively interpolating between both. Consequently, minimum ED estimation overcomes the problem of nearsightedness encountered in score-based estimation methods, while also enjoying theoretical guarantees. Through numerical experiments, we demonstrate that ED learns low-dimensional data distributions faster and more accurately than explicit score matching or contrastive divergence. For high-dimensional image data, we describe how the manifold hypothesis puts limitations on our approach and demonstrate the effectiveness of energy discrepancy by training the energy-based model as a prior of a variational decoder model.
Flexible model composition in machine learning and its implementation in MLJ
Dec 31, 2020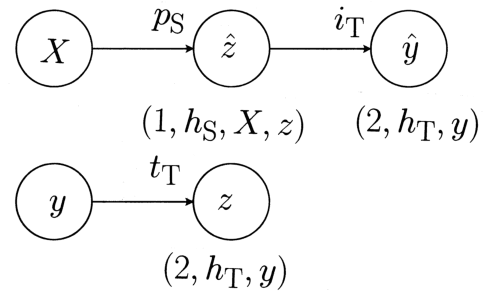


A graph-based protocol called `learning networks' which combine assorted machine learning models into meta-models is described. Learning networks are shown to overcome several limitations of model composition as implemented in the dominant machine learning platforms. After illustrating the protocol in simple examples, a concise syntax for specifying a learning network, implemented in the MLJ framework, is presented. Using the syntax, it is shown that learning networks are are sufficiently flexible to include Wolpert's model stacking, with out-of-sample predictions for the base learners.
MLJ: A Julia package for composable Machine Learning
Jul 23, 2020
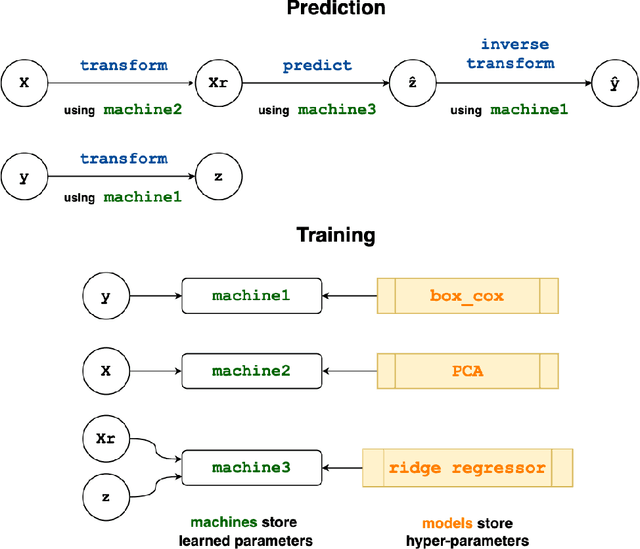
MLJ (Machine Learing in Julia) is an open source software package providing a common interface for interacting with machine learning models written in Julia and other languages. It provides tools and meta-algorithms for selecting, tuning, evaluating, composing and comparing those models, with a focus on flexible model composition. In this design overview we detail chief novelties of the framework, together with the clear benefits of Julia over the dominant multi-language alternatives.
Measuring Sample Quality with Diffusions
Feb 21, 2018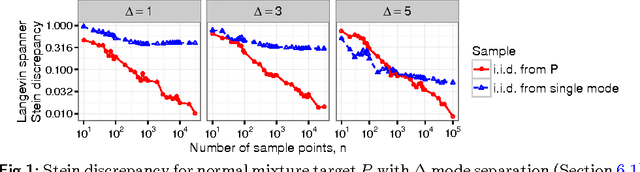
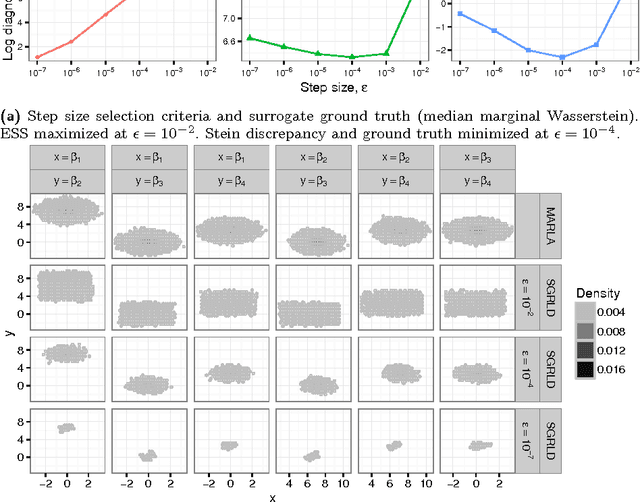
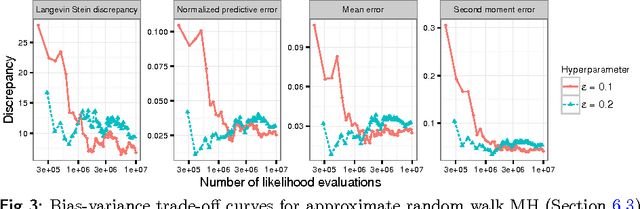
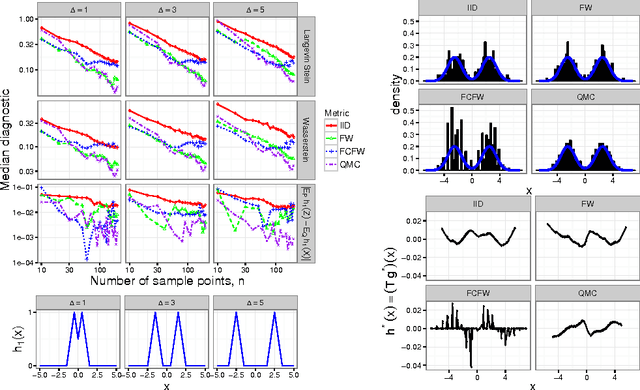
Stein's method for measuring convergence to a continuous target distribution relies on an operator characterizing the target and Stein factor bounds on the solutions of an associated differential equation. While such operators and bounds are readily available for a diversity of univariate targets, few multivariate targets have been analyzed. We introduce a new class of characterizing operators based on Ito diffusions and develop explicit multivariate Stein factor bounds for any target with a fast-coupling Ito diffusion. As example applications, we develop computable and convergence-determining diffusion Stein discrepancies for log-concave, heavy-tailed, and multimodal targets and use these quality measures to select the hyperparameters of biased Markov chain Monte Carlo (MCMC) samplers, compare random and deterministic quadrature rules, and quantify bias-variance tradeoffs in approximate MCMC. Our results establish a near-linear relationship between diffusion Stein discrepancies and Wasserstein distances, improving upon past work even for strongly log-concave targets. The exposed relationship between Stein factors and Markov process coupling may be of independent interest.
Relativistic Monte Carlo
Sep 14, 2016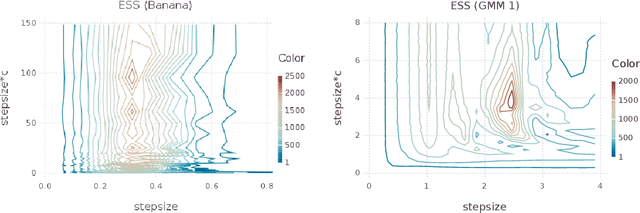
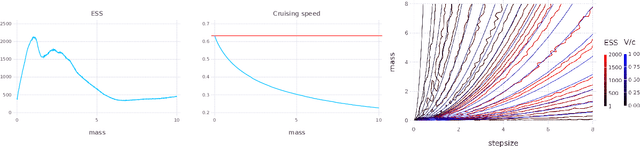
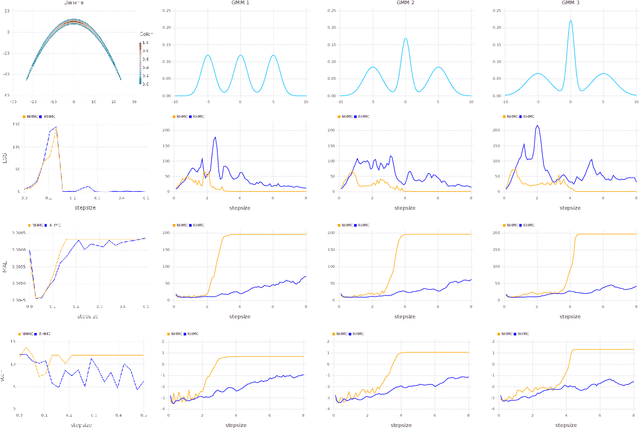
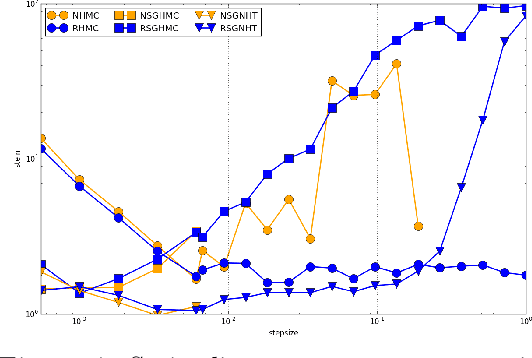
Hamiltonian Monte Carlo (HMC) is a popular Markov chain Monte Carlo (MCMC) algorithm that generates proposals for a Metropolis-Hastings algorithm by simulating the dynamics of a Hamiltonian system. However, HMC is sensitive to large time discretizations and performs poorly if there is a mismatch between the spatial geometry of the target distribution and the scales of the momentum distribution. In particular the mass matrix of HMC is hard to tune well. In order to alleviate these problems we propose relativistic Hamiltonian Monte Carlo, a version of HMC based on relativistic dynamics that introduce a maximum velocity on particles. We also derive stochastic gradient versions of the algorithm and show that the resulting algorithms bear interesting relationships to gradient clipping, RMSprop, Adagrad and Adam, popular optimisation methods in deep learning. Based on this, we develop relativistic stochastic gradient descent by taking the zero-temperature limit of relativistic stochastic gradient Hamiltonian Monte Carlo. In experiments we show that the relativistic algorithms perform better than classical Newtonian variants and Adam.
(Non-) asymptotic properties of Stochastic Gradient Langevin Dynamics
Sep 21, 2015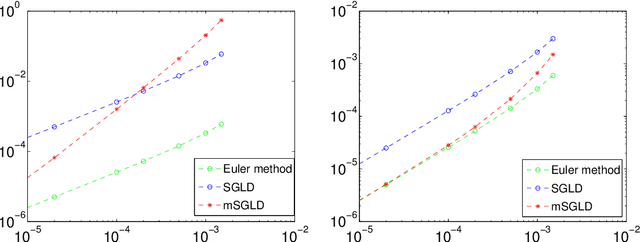
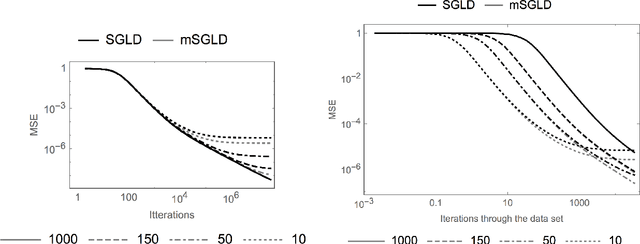
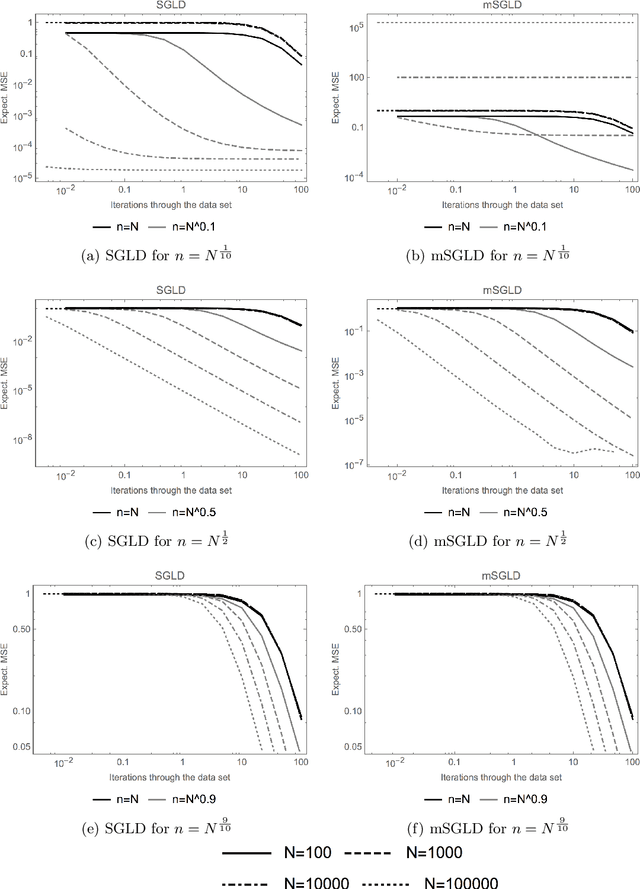
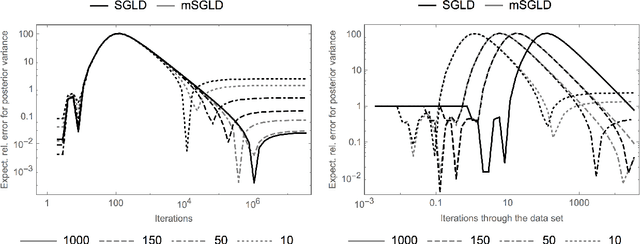
Applying standard Markov chain Monte Carlo (MCMC) algorithms to large data sets is computationally infeasible. The recently proposed stochastic gradient Langevin dynamics (SGLD) method circumvents this problem in three ways: it generates proposed moves using only a subset of the data, it skips the Metropolis-Hastings accept-reject step, and it uses sequences of decreasing step sizes. In \cite{TehThierryVollmerSGLD2014}, we provided the mathematical foundations for the decreasing step size SGLD, including consistency and a central limit theorem. However, in practice the SGLD is run for a relatively small number of iterations, and its step size is not decreased to zero. The present article investigates the behaviour of the SGLD with fixed step size. In particular we characterise the asymptotic bias explicitly, along with its dependence on the step size and the variance of the stochastic gradient. On that basis a modified SGLD which removes the asymptotic bias due to the variance of the stochastic gradients up to first order in the step size is derived. Moreover, we are able to obtain bounds on the finite-time bias, variance and mean squared error (MSE). The theory is illustrated with a Gaussian toy model for which the bias and the MSE for the estimation of moments can be obtained explicitly. For this toy model we study the gain of the SGLD over the standard Euler method in the limit of large data sets.