 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM Interactive Optimization of Open Source Python Libraries -- Case Studies and Generalization
Dec 08, 2023With the advent of large language models (LLMs) like GPT-3, a natural question is the extent to which these models can be utilized for source code optimization. This paper presents methodologically stringent case studies applied to well-known open source python libraries pillow and numpy. We find that contemporary LLM ChatGPT-4 (state September and October 2023) is surprisingly adept at optimizing energy and compute efficiency. However, this is only the case in interactive use, with a human expert in the loop. Aware of experimenter bias, we document our qualitative approach in detail, and provide transcript and source code. We start by providing a detailed description of our approach in conversing with the LLM to optimize the _getextrema function in the pillow library, and a quantitative evaluation of the performance improvement. To demonstrate qualitative replicability, we report further attempts on another locus in the pillow library, and one code locus in the numpy library, to demonstrate generalization within and beyond a library. In all attempts, the performance improvement is significant (factor up to 38). We have also not omitted reporting of failed attempts (there were none). We conclude that LLMs are a promising tool for code optimization in open source libraries, but that the human expert in the loop is essential for success. Nonetheless, we were surprised by how few iterations were required to achieve substantial performance improvements that were not obvious to the expert in the loop. We would like bring attention to the qualitative nature of this study, more robust quantitative studies would need to introduce a layer of selecting experts in a representative sample -- we invite the community to collaborate.
MLJ: A Julia package for composable Machine Learning
Jul 23, 2020
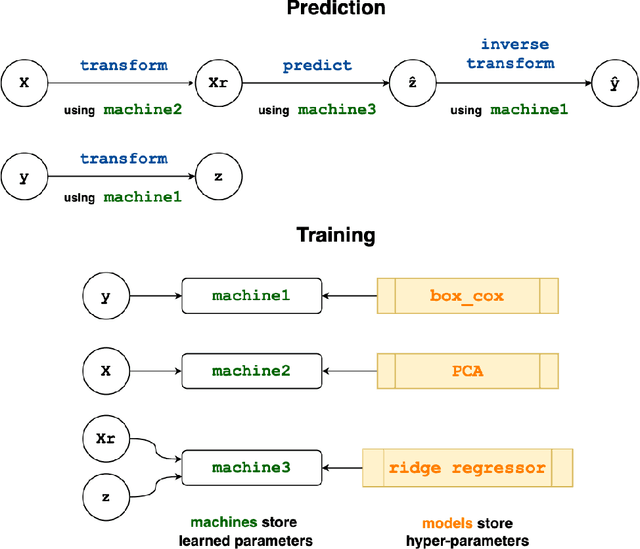
MLJ (Machine Learing in Julia) is an open source software package providing a common interface for interacting with machine learning models written in Julia and other languages. It provides tools and meta-algorithms for selecting, tuning, evaluating, composing and comparing those models, with a focus on flexible model composition. In this design overview we detail chief novelties of the framework, together with the clear benefits of Julia over the dominant multi-language alternatives.
Algebraic-Combinatorial Methods for Low-Rank Matrix Completion with Application to Athletic Performance Prediction
Jun 11, 2014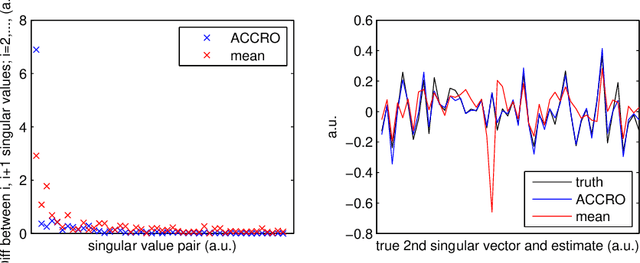

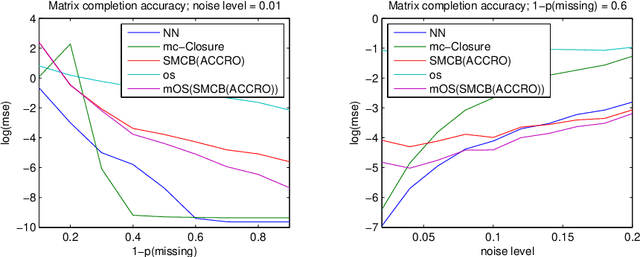
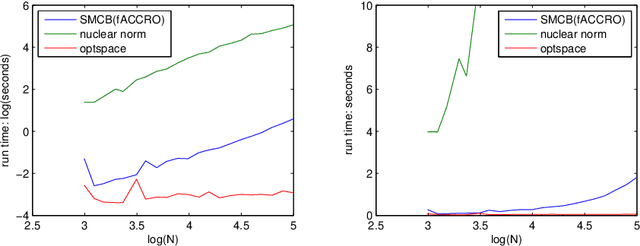
This paper presents novel algorithms which exploit the intrinsic algebraic and combinatorial structure of the matrix completion task for estimating missing en- tries in the general low rank setting. For positive data, we achieve results out- performing the state of the art nuclear norm, both in accuracy and computational efficiency, in simulations and in the task of predicting athletic performance from partially observed data.
A Combinatorial Algebraic Approach for the Identifiability of Low-Rank Matrix Completion
Jun 27, 2012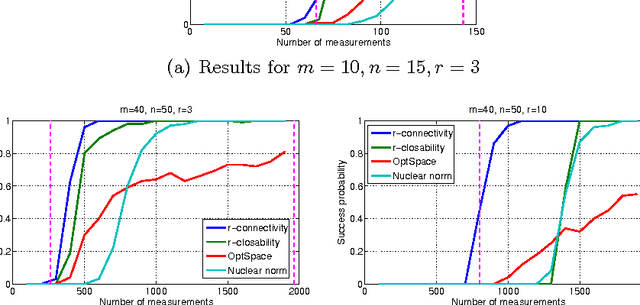
In this paper, we review the problem of matrix completion and expose its intimate relations with algebraic geometry, combinatorics and graph theory. We present the first necessary and sufficient combinatorial conditions for matrices of arbitrary rank to be identifiable from a set of matrix entries, yielding theoretical constraints and new algorithms for the problem of matrix completion. We conclude by algorithmically evaluating the tightness of the given conditions and algorithms for practically relevant matrix sizes, showing that the algebraic-combinatoric approach can lead to improvements over state-of-the-art matrix completion methods.